







文章目录
进程以及状态
进程
进程:一个程序运行起来后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单元。(资源包括:Cpu,内存,文件,socket 对象,等等)
进程的状态

操作系统内核实际上采用时间片轮转的方式进行调控进程的运行,也就是在内核分配中,实际上是存在进程队列 和 睡眠队列,前者好比程序运行了一个时间片就移到下一个进程周期中,然后到达下一个进程周期时,进行重新分配时间片后,再接着运行,而在进程运行的时候,如果发现需要等待条件(如input)的时候,就将这个进程调入睡眠队列。
R 状态 运行
S 状态 睡眠
常用的查看进程状态的命令:top ps(下文会详细介绍)
而对于ps来说,看到 R 状态是两次采样之间的一个时间片变化分析计算,并不意味着他是处于运动状态,意思是他在一个时间片(两次采样)之间存在运动状态
linux下的进程管理
常用的相关指令:
| 命令 | 含义 |
|---|---|
| ps | 查看系统中的进程 |
| top | 动态显示系统中的进程 |
| kill | 向进程发送信号(包括后台进程) |
| crontab | 用于安装删除或者列出用于驱动cron后台进程的任务 |
| bg | 将挂起的进程放到后台执行 |
备注:
- cat /proc/cpuinfo 查看 Linux 的 cpu 的核数
- 进程 process:是 os 的最小单元 os 会为每个进程分配大小为 4g 的虚拟内存空间,其中1g 给内核空间 3g 给用户空间{代码区 数据区 堆栈}
- python main.py & 让进程在后台运行
ps
ps –elf 可以显示父子进程关系,基本上用这个就可以了,加上|grep 进行筛选相关的想查看的进程

补充:
- 进程的状态包括四种:S 睡眠(input) T 暂停(ctrl+z,单步调试)R 运行(正常python运行) Z僵尸
top
top 显示前 20 条进程,动态的改变,按 q退出
运行出来是这样子的
top - 16:24:25 up 284 days, 4:59, 1 user, load average: 0.10, 0.05, 0.01
Tasks: 115 total, 1 running, 114 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.1%us, 0.0%sy, 0.0%ni, 99.8%id, 0.0%wa, 0.0%hi, 0.1%si, 0.0%st
Mem: 4074364k total, 3733628k used, 340736k free, 296520k buffers
Swap: 2104504k total, 40272k used, 2064232k free, 931680k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
11836 root 15 0 2324 1028 800 R 0.3 0.0 0:00.02 top
27225 root 25 0 1494m 696m 11m S 0.3 17.5 2304:03 java
1 root 18 0 2072 620 532 S 0.0 0.0 7:04.48 init
下面介绍一下是什么意思:
第一行:
16:24:25 当前时间
up 284 days, 4:59 系统启动时间
1 user 当前系统登录用户数目
# 重要
load average: 0.10, 0.05, 0.01 平均负载(1 分钟,10 分钟,15 分钟)
平均负载(load average),一般对于单个 cpu 来说,负载在 0~1.00 之间是正常的,超过 1.00 须引起注意。在多核 cpu 中,系统平均负载不应该高于 cpu 核心的总数太多
第二行:
115 total 进程总数、
1 running 运行进程数、
114 sleeping 休眠进程数、
0 stopped 终止进程数、
0 zombie 僵死进程数
第三行:
# 重要 用户空间实际上就是比如我们采用for循环的打印这类的,在端口上打印数据之类的操作
0.1%us %us 用户空间占用 cpu 百分比;
# 重要 内核空间大部分在于调用资源的占比 也就是在Flood DDos攻击下主要攻击的地方
0.0%sy %sy 内核空间占用 cpu 百分比;
0.0%ni %ni 用户进程空间内改变过优先级的进程占用 cpu 百分比;
# 重要
99.8%id %id 空闲 cpu 百分比,反映一个系统 cpu 的闲忙程度。越大越空闲;
0.0%wa %wa 等待输入输出(I/O)的 cpu 百分比;
0.0%hi %hi 指的是 cpu 处理硬件中断的时间;
0.1%si %si 值的是 cpu 处理软件中断的时间;
0.0%st %st 用于有虚拟 cpu 的情况,用来指示被虚拟机偷掉的 cpu 时间。
第四行(Mem):
4074364k total total 总的物理内存;
3733628k used used 使用物理内存大小;
340736k free free 空闲物理内存;
296520k buffers buffers 用于内核缓存的内存大小
查看系统内存占用情况 也可以使用free命令
第五行(Swap):
2104504k total total 总的交换空间大小;
40272k used used 已经使用交换空间大小;
2064232k free free 空间交换空间大小;
931680k cached cached 缓冲的交换空间大小
然后下面就是和 ps 相仿的各进程情况列表了
第六行:
- PID 进程号
- USER 运行用户
- PR 优先级,PR(Priority)优先级
- NI 任务 nice 值
- VIRT 进程使用的虚拟内存总量,单位 kb。VIRT=SWAP+RES
- RES 物理内存用量
- SHR 共享内存用量
S 该进程的状态。其中 S 代表休眠状态;D 代表不可中断的休眠状态;R 代表运行状态;Z 代表僵死状态;T 代表停止或跟踪状态 - %CPU 该进程自最近一次刷新以来所占用的 CPU 时间和总时间的百分比
- %MEM 该进程占用的物理内存占总内存的百分比
- TIME+ 累计 cpu 占用时间
11.COMMAND 该进程的命令名称,如果一行显示不下,则会进行截取。内存中的进程会有一个完整的命令行。
bg
bg 让暂停的进程在后台运行
fg 拉到前台
jobs 看后台任务
$ python main.py
^Z
[1]+ 已停止 main.py
$ jobs
[1]+ 已停止 main.py
$ python main.py &
[2] 4616
$ jobs
[1]+ 已停止 python main.py
[2]- 运行中 python main.py &
# bg就是让这里通过ctrl+z暂停执行的代码重新后台跑起来 1是对应的这个id号
$ bg 1
[1]+ python main.py &
$ jobs
[1]+ 运行中 python main.py &
[2]- 运行中 python main.py &
# 实际上就是把后台运行的代码,拉到前台运行
$ fg 2
python main.py &
kill
kill -l 查看系统的所有信号
kill -9 进程号 表示向某个进程发送 9 号信号,从而杀掉某个进程
利用 pkill -f a 可以杀死进程名为 a 的进程,如果有空格,用\转义
pkill -f python\ 1.while 死循环.p
crontab
crontab –e 设置当前用户定时任务
vim /etc/crontab 设置定时任务
crontab -l 查看当前自己设置的定时任务
详细见:链接
进程的创建
multiprocessing 模块就是跨平台版本的多进程模块,提供了一个 Process 类来代表一个进程对象,这个对象可以理解为是一个独立的进程,可以执行另外的事情
两个while同时运行示例
from multiprocessing import Process
import time
def run_proc():
"""子进程要执行的代码"""
while True:
print("----2----")
time.sleep(1)
if __name__=='__main__':
p = Process(target=run_proc)
p.start()
while True:
print("----1----")
time.sleep(1)
对于这个程序来说,实际上是先python运行得到一个父进程,然后这个父进程通过process生成一个子进程,然后两个进程之间相互时间片轮转运行。
获取进程pid
from multiprocessing import Process
import os
import time
def run_proc():
"""子进程要执行的代码"""
print('子进程运行中,pid=%d...' % os.getpid()) # os.getpid 获取当前进程的进程号
print('子进程将要结束...')
if __name__ == '__main__':
print('父进程 pid: %d' % os.getpid()) # os.getpid 获取当前进程的进程号
p = Process(target=run_proc)
p.start()
- 获取父亲的 pid : os.getppid() # 多个p
- 而对父进程的使用os.getppid(),得到的pid是bash(命令行的pid)
Process 结构
- Process(group , target , name , args , kwargs)
• target:如果传递了函数的引用,可以让这个子进程就执行这里的代码
• args:给 target 指定的函数传递的参数,以元组的方式传递
• kwargs:给 target 指定的函数传递命名参数,keyword 参数
• name:给进程设定一个名字,可以不设定
• group:指定进程组,大多数情况下用不到 - Process 创建的实例对象的常用方法:
• start():启动子进程实例(创建子进程)
•== is_alive():判断进程子进程是否还在活着==
• join([timeout]):是否等待子进程执行结束,或等待多少秒回收子进程尸体,实际上这个很重要。
•== terminate():不管任务是否完成,立即终止子进程== - Process 创建的实例对象的常用属性:
• pid:当前进程的 pid(进程号)
给子进程指定的函数传递参数
from multiprocessing import Process
import os
from time import sleep
def run_proc(name, age, **kwargs):
for i in range(10):
print('子进程运行中,name= %s,age=%d ,pid=%d...' % (name, age, os.getpid()))
print(kwargs)
sleep(0.2)
if __name__=='__main__':
# 这边是关键 args 和 kwargs
p = Process(target=run_proc, args=('test',18), kwargs={"m":20})
p.start()
sleep(1) # 1 秒中之后,立即结束子进程
p.terminate()
p.join()
进程间是否共享全局变量
from multiprocessing import Process
import os
import time
nums = [11, 22]
def work1():
"""子进程要执行的代码"""
print("in process1 pid=%d ,nums=%s" % (os.getpid(), nums))
for i in range(3):
nums.append(i)
time.sleep(1)
print("in process1 pid=%d ,nums=%s" % (os.getpid(), nums))
def work2():
"""子进程要执行的代码"""
print("in process2 pid=%d ,nums=%s" % (os.getpid(), nums))
if __name__ == '__main__':
p1 = Process(target=work1)
p1.start()
p1.join()
p2 = Process(target=work2)
p2.start()
好好理解一下,实际上对于num参数来说,创建子进程的时候会复制一份父进程的资源,而二者的资源独立使用,对于num是何值,取决于创建子进程的那一瞬间父进程的该项资源是什么值。
补充
- 孤儿进程 — 子进程在运行,父进程先执行结束完退出,此时通过ps
-elf|grep 程序名称进行查看,发现父进程进入等待wait状态,子进程在运行,然后此时kill 杀死父进程,子进程变为孤儿进程。(定义:孤儿进程是指其父进程已经结束或者失去了对该进程的控制权,而该进程仍然在运行的情况下,被称为孤儿进程。,但是对于python程序来说,当孤儿进程出现的时候,linux内核会将这个孤儿进程的父亲pid弄成1,也就是开机进程,此时此孤儿进程结束之后,资源就由开机进程回收) - 僵尸进程 — 子进程退出,父进程在忙碌,没有回收它,要避免僵尸,Python 进程变为僵尸进程后,名字会改变(所以如果想要查看僵尸进程的时候,就需要查找对应进程的的pid,或者直接ps -elf直接翻)

- 并不能通过kill的方法杀死僵尸进程,原因就在于,实际上我们kill实现的功能就是通过将这个进程变成僵尸进程,然后父亲进程马上就会回收子进程的资源,也就是此时这个僵尸进程就会马上消失,所以想要杀死一个僵尸进程,就不能让父亲进程时刻处于忙碌状态。
进程间通信-Queue
常用操作
| 常用操作 | 说明 |
|---|---|
| q = Queue(number) | 括号中指定的数据是这个队列最大能容纳多少条的信息,若括号中没有指定最大可接收的消息数量,或数量为负值,那么就代表可接受的消息数量没有上限(直到内存的尽头) |
| Queue.qsize() | 返回当前队列包含的消息数量 |
| Queue.empty() | 如果队列为空,返回 True,反之 False |
| Queue.full() | 如果队列满了,返回 True,反之 False |
| Queue.get([block[, timeout]]) | 获取队列中的一条消息,然后将其从队列中移除,block 默认值为 True |
| Queue.get_nowait() | 相当 Queue.get(block=False) |
| Queue.put(item,[block[, timeout]]) | 将 item 消息写入队列,block 默认值为True |
| Queue.put_nowait(item) | 相当 Queue.put(item, False) |
- 对于Queue.get([block[, timeout]])中:
1)如果 block 使用默认值,且没有设置 timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为止,如果设置了 timeout,则会等待 timeout 秒,若还没读取到任何消息,则抛出==“Queue.Empty”==异常
2)如果 block 值为 False,消息列队如果为空,则会立刻抛出"Queue.Empty"异常。 - 对于Queue.put(item,[block[, timeout]]):
1)如果 block 使用默认值,且没有设置 timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了 timeout,则会等待 timeout 秒,若还没空间,则抛出==“Queue.Full”==异常;
2)如果 block 值为 False,消息列队如果没有空间可写入,则会立刻抛抛出"Queue.Full"异常;
Queue 实例
from multiprocessing import Process, Queue
import time
def writer(q):
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(1)
def reader(q:Queue):
while True:
if not q.empty():
value = q.get(True)
print('Get %s from queue.' % value)
time.sleep(2)
else:
break
if __name__ == '__main__':
q=Queue(10)
pw=Process(target=writer,args=(q,)) #一个元素必须加逗号,才是元组
pr=Process(target=reader,args=(q,))
pw.start()
time.sleep(1)
pr.start()
pw.join()
pr.join()
管道通信(了解)
此模块参考链接
Pipe 常用来实现 2 个进程之间的通信,这 2 个进程分别位于管道的两端,一端用来发送数据,另一端用来接收数据。使用 Pipe 实现进程通信,首先需要调用 multiprocessing.Pipe() 函数来创建一个管道。
conn1, conn2 = multiprocessing.Pipe( [duplex=True] )
其中,conn1 和 conn2 分别用来接收 Pipe 函数返回的 2 个端口;duplex 参数默认为True,表示该管道是双向的,即位于 2 个端口的进程既可以发送数据,也可以接受数据,而如果将 duplex 值设为 False,则表示管道是单向的,conn1 只能用来接收数据,而 conn2只能用来发送数据。
样例
from multiprocessing import Pipe, Process
def son_process(x, pipe):
_out_pipe, _in_pipe = pipe
# 关闭fork过来的输入端
_in_pipe.close()
while True:
try:
msg = _out_pipe.recv()
print(msg)
except EOFError:
# 当out_pipe接受不到输出的时候且输入被关闭的时候,会抛出EORFError,可以捕获并且退出子进程
break
if __name__ == '__main__':
out_pipe, in_pipe = Pipe(True)
son_p = Process(target=son_process, args=(100, (out_pipe, in_pipe)))
son_p.start()
# 等 pipe 被 fork 后,关闭主进程的输出端
# 这样,创建的Pipe一端连接着主进程的输入,一端连接着子进程的输出口
out_pipe.close()
for x in range(1000):
in_pipe.send(x)
in_pipe.close()
son_p.join()
print "主进程也结束了"
为什么上面
- 当主进程创建Pipe的时候,Pipe的两个Connections连接的都是主进程;
- 当主进程创建子进程后,Connections被拷贝了一份,此时一共有2(主进程)+ 2(子进程)= 4 个Connections;
- 随后,我们关闭主进程中的 out_connection 和子进程中的 in_connection 端口,即可建立一条主进程通往子进程的管道了;
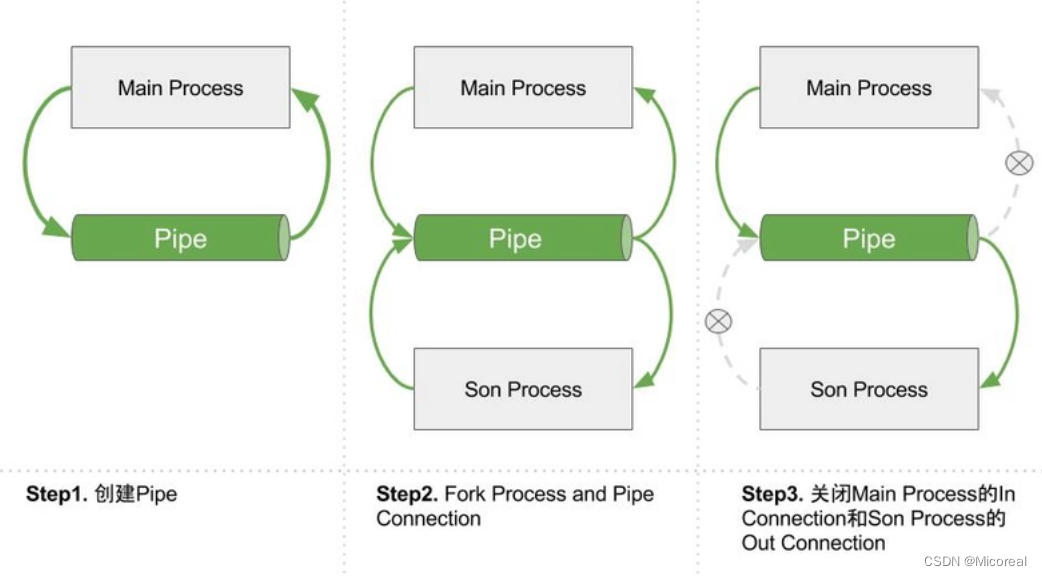
4. 由于Pipe之间的通信时通过,in_conn.send()、out_conn.recv() 这种方式进行通信的,因此如果当某一方调用了 .recv() 函数但一直没有另外的端口使用 .send() 方法的话,recv() 函数就会阻塞住。为了避免程序阻塞,我们在明确另一个端口不会再调用 .send() 函数后可以直接将发送端口给 close(),这样以来如果接收端还在继续调用 .recv() 方法的话程序就会抛出 EOFError 的异常
进程池 Pool
当需要创建的子进程数量不多时,可以直接利用 multiprocessing 中的 Process 动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到 multiprocessing 模块提供的 Pool 方法。
初始化 Pool 时,可以指定一个最大进程数(一般和CPU的核数相关一倍到两倍之间),当有新的请求提交到 Pool 中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务
from multiprocessing.pool import Pool
import os, time, random
def worker(msg):
t_start = time.time()
print("%s 开始执行,进程号为%d" % (msg,os.getpid()))
# random.random()随机生成 0~1 之间的浮点数
time.sleep(random.random()*2)
t_stop = time.time()
print(msg,"执行完毕,耗时%0.2f" % (t_stop-t_start))
if __name__ == '__main__':
po = Pool(3) # 定义一个进程池,最大进程数 3
for i in range(0,10):
# Pool().apply_async(要调用的目标,(传递给目标的参数元祖,))
# 每次循环将会用空闲出来的子进程去调用目标
po.apply_async(worker,(i,))
print("----start----")
po.close() # 关闭进程池,关闭后 po 不再接收新的请求
po.join() # 等待 po 中所有子进程执行完成,必须放在 close 语句之后
print("-----end-----")
常用函数解析:
| 常用函数 | 说明 |
|---|---|
| apply_async(func[, args[, kwds]]) | 使用非阻塞方式调用 func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args 为传递给 func的参数列表,kwds 为传递给 func 的关键字参数列表 |
| close() | 关闭 Pool,使其不再接受新的任务 |
| terminate() | 不管任务是否完成,立即终止 |
| join() | 主进程阻塞,等待子进程的退出, 必须在 close 或 terminate 之后使用 |
进程池中的Queue
如果要使用 Pool 创建进程,就需要使用 multiprocessing.Manager()中的
Queue(),而不是 multiprocessing.Queue
给一个使用进程池时,进程间如何通信的例子:
from multiprocessing import Manager,Pool
import os,time,random
def reader(q):
print("reader 启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in range(q.qsize()):
print("reader 从 Queue 获取到消息:%s" % q.get(True))
def writer(q):
print("writer 启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in "helloworld":
q.put(i)
if __name__=="__main__":
print("(%s) start" % os.getpid())
q = Manager().Queue() # 使用 Manager 中的 Queue
po = Pool()
po.apply_async(writer, (q,))
time.sleep(1) # 先让上面的任务向 Queue 存入数据,然后再让下面的任务开始从中取数据
po.apply_async(reader, (q,))
po.close()
po.join()
print("(%s) End" % os.getpid()
示例:文件夹 copy 器(多进程)
import multiprocessing
import os
import time
import random
def copy_file(queue, file_name,source_folder_name, dest_folder_name):
"""copy 文件到指定的路径"""
f_read = open(source_folder_name + "/" + file_name, "rb")
f_write = open(dest_folder_name + "/" + file_name, "wb")
while True:
time.sleep(random.random())
content = f_read.read(1024)
if content:
f_write.write(content)
else:
break
f_read.close()
f_write.close()
# 发送已经拷贝完毕的文件名字
queue.put(file_name)
def main():
# 获取要复制的文件夹
source_folder_name = input("请输入要复制文件夹名字:")
# 整理目标文件夹
dest_folder_name = source_folder_name + "[副本]"
# 创建目标文件夹
try:
os.mkdir(dest_folder_name)
except:
pass # 如果文件夹已经存在,那么创建会失败
# 获取这个文件夹中所有的普通文件名
file_names = os.listdir(source_folder_name)
# 创建 Queue
queue = multiprocessing.Manager().Queue()
# 创建进程池
pool = multiprocessing.Pool(3)
for file_name in file_names:
# 向进程池中添加任务
pool.apply_async(copy_file, args=(queue, file_name, source_folder_name, dest_folder_name))
# 主进程显示进度
pool.close()
all_file_num = len(file_names)
while True:
file_name = queue.get()
if file_name in file_names:
file_names.remove(file_name)
copy_rate = (all_file_num-len(file_names))*100/all_file_num
print("\r%.2f...(%s)" % (copy_rate, file_name) + " "*50, end="")
if copy_rate >= 100:
break
print()
if __name__ == "__main__":
main()
后语(常见问题与补充)
进程的封装
- 此篇文章缺少对于进程的封装,关于封装的思路实际上就是和线程的思路相同,详情见链接
想要两个进程的先后运行,我们该如何进行操作
我们可以在这个进程中增加一个queue,当前一个该运行的进程运行结束,就传一个字符过去给后一个进程,从而进行控制进程的先后执行。















 1202
1202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









