







本系列参考视频:吴恩达的machine-learing 可去coursera官网查看
链接
然后就是比较偏向的是个人笔记,具体就是个人的理解能力以及复盘能力有所差异,这边仅当做个参考,做个笔记式的学习。
这边有看到有别的up进行搬运,这边就也一并粘贴出来:
链接
Week1
Neurons and brain
在这一小节当中,大概讲解了为什么要使用logistic以及多层网络作为我们的神经网络模型,原因就是我们来模仿人类的脑神经的结构进行的构造。
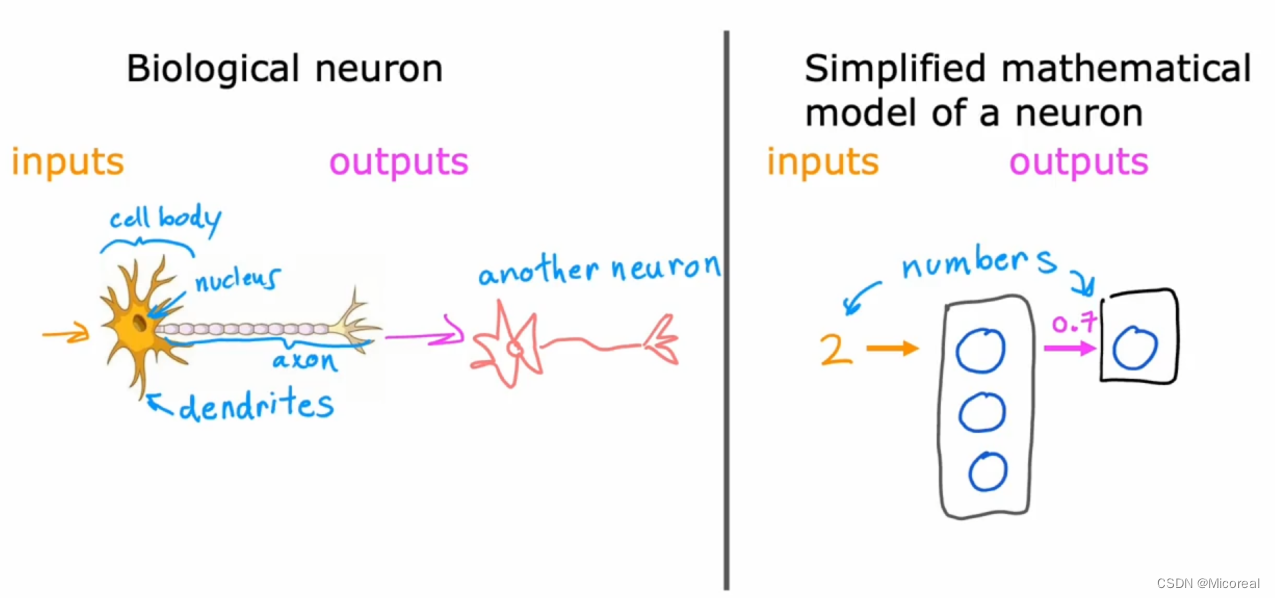
我们会发现生物信息经过神经元的流动是从一头输入,然后细胞核通过分析生物电流的情况是兴奋还是抑制,然后继续向后传导,这个流程就相当于我们右边的简化版本的数学模型,我们输入一个数据,然后接上三个神经元units(在神经元的相接中可能是一对多或者多对一或者多对多都有可能),然后分别计算之后,再经由激活函数sigmoid(模拟那个检测是兴奋还是抑制),然后输出给下一个神经元或者下一组神经元。以此类推,当然层数是可以不断增加的,这也就是deep-learning的由来。
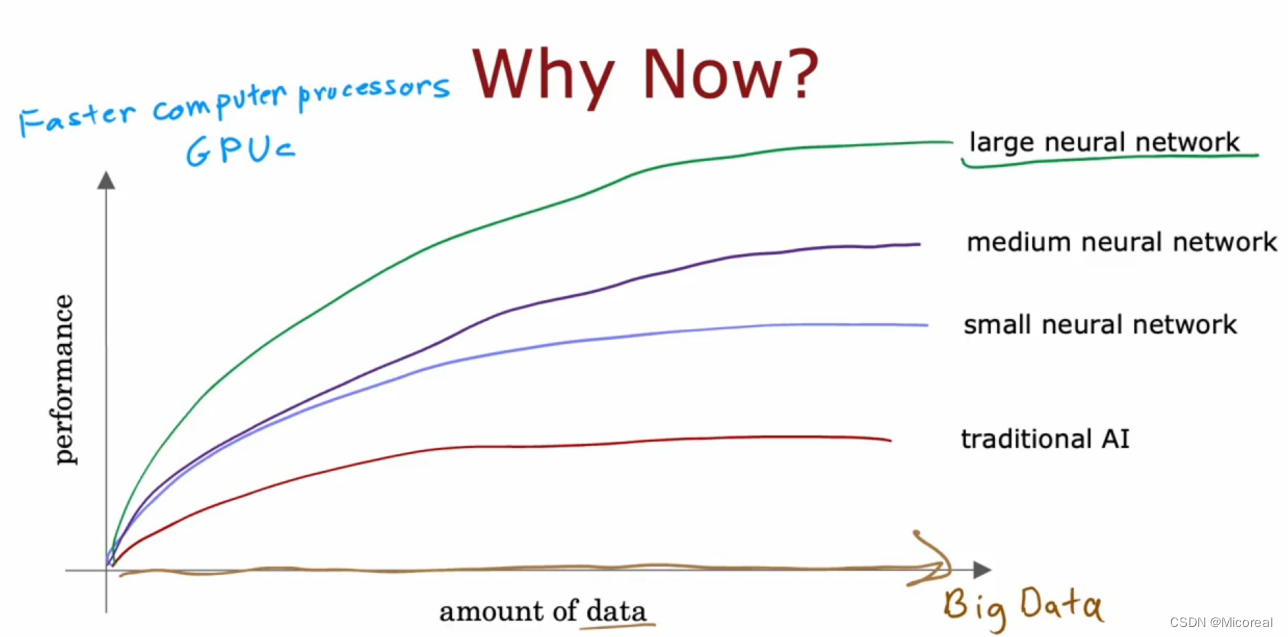
然后文末探讨了,神经元的多少和数据的关系,(wide or deep,有兴趣可以看看这边论文),下面这张图证明了当连接的神经元越多,以及数据量越多的情况下,最后预测的准确性就会越高,也就是更趋向于more wide
Neural network layer
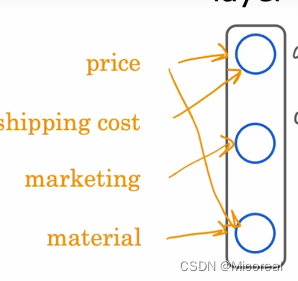
在介绍神经网络之前,我们先介绍一些直觉性的东西,让我们进行理解,假设我们的输入的向量特征是(price,shipping cost,marketing,material),然后我们后面要预测输出的是这套房子被卖掉的可能性,然后我们的一个思考可能可以是,降维度思考,我们认为这套房子被首卖掉的可能性取决于(affordability,awareness,perceived quality)这三个可能,而这三个特征可以由上面四个特征的关系得出,所以对于这套建模,我们理解了,就大概可以理解神经元的基本流程
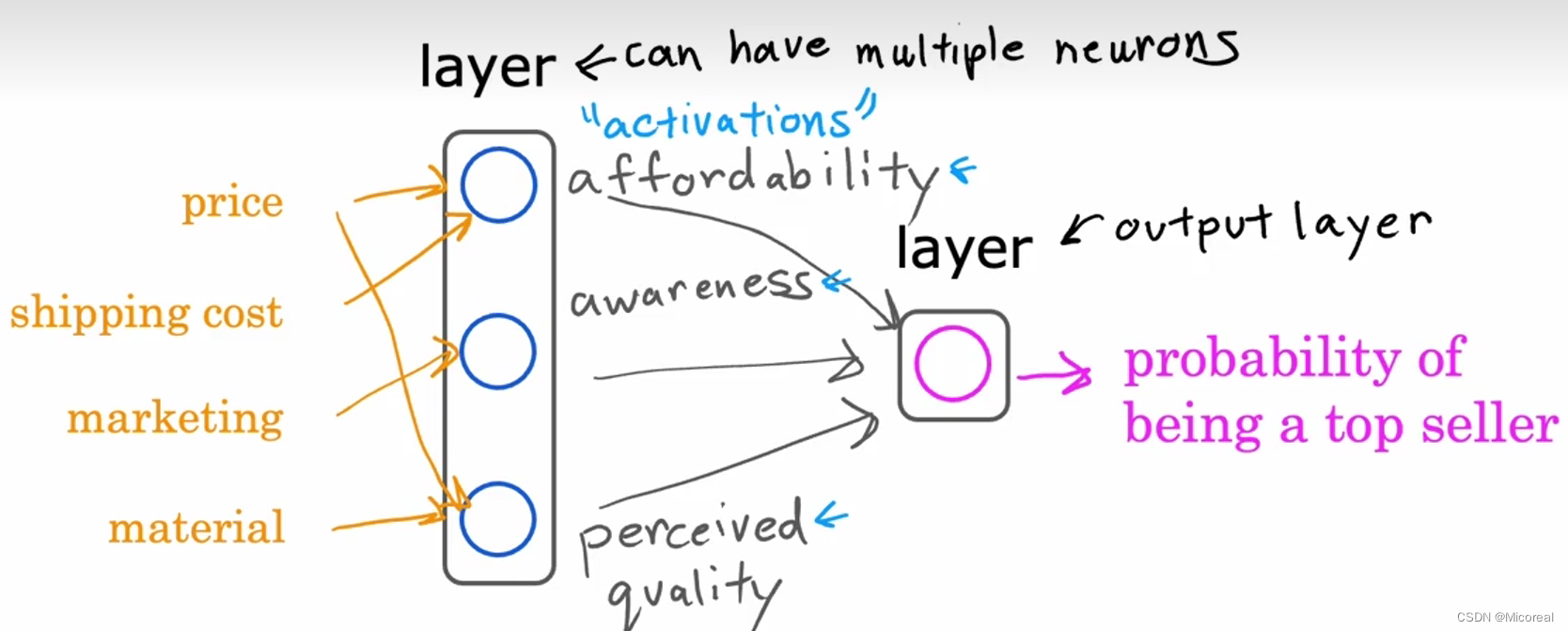
我们一般把最左边的叫做input-layer 中间的叫做hidden-layer 后面的输出叫做 output-layer。
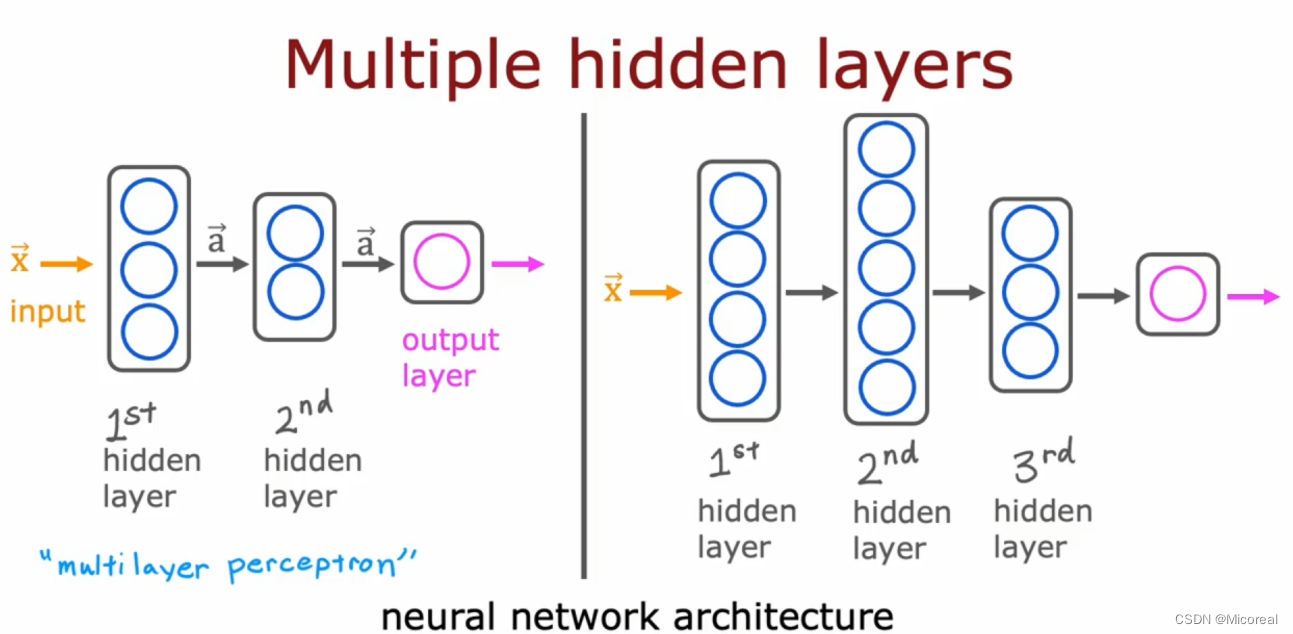
但是这样子的分析明显不够,我们可以朝深度或者宽度去发展(在我们上面推荐的宽度或者深度的那篇论文中其实介绍了对于),我们可以朝更深的方向去发展。
然后我们可以理解一下每一层学到的信息都是什么,我们拿图像识别来进行说明:
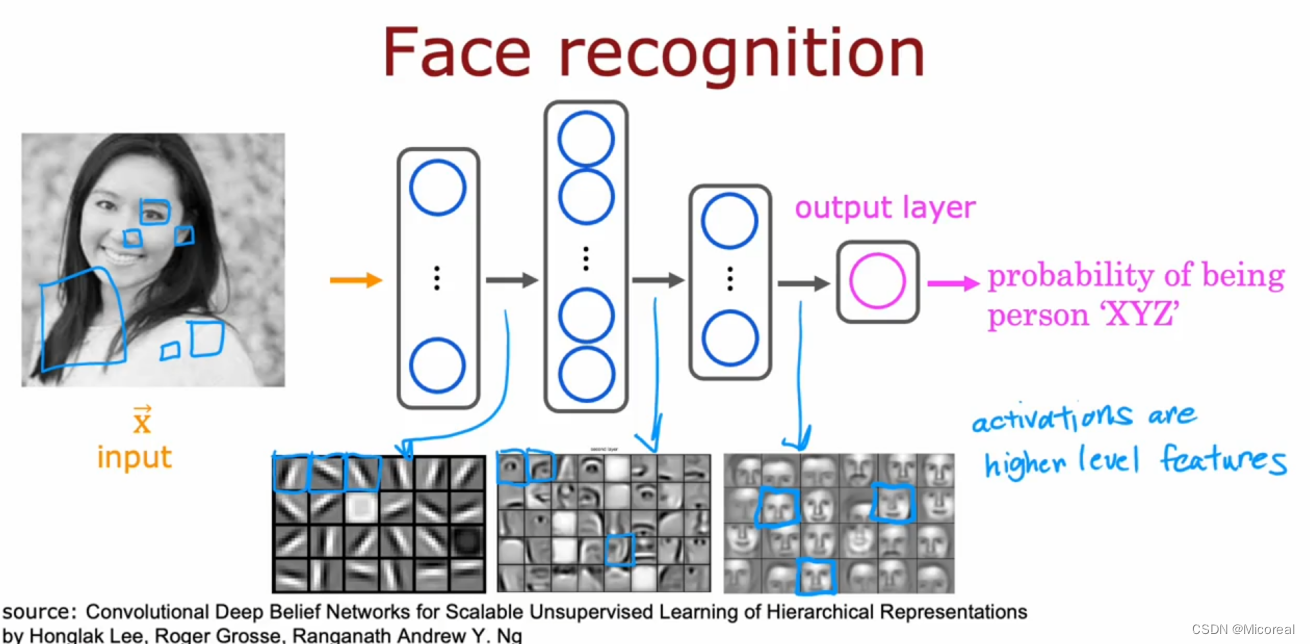
我们会发现在第一层中我们每一个神经元实际上学到的只是人脸当中的一条线,第二部分就是将线进行组合,学到了一个眼睛,鼻子之类的,后面以此类推。
但是现在又有一个问题就是,我们该怎么知道下图的映射关系,因为在绝大多数情况下,我们不想动脑,于是直接全部连接起来,相当于让机器去做决定哪些线重要,我们只需要控制右边的神经元有多少个即可,这也就是全连接层的来源。hh
而关于这个矩阵运算见下即可,甚至我们可以直接表示为矩阵运算,不用按照下边的进行描述,下面的就是比较详细的解释罢了。
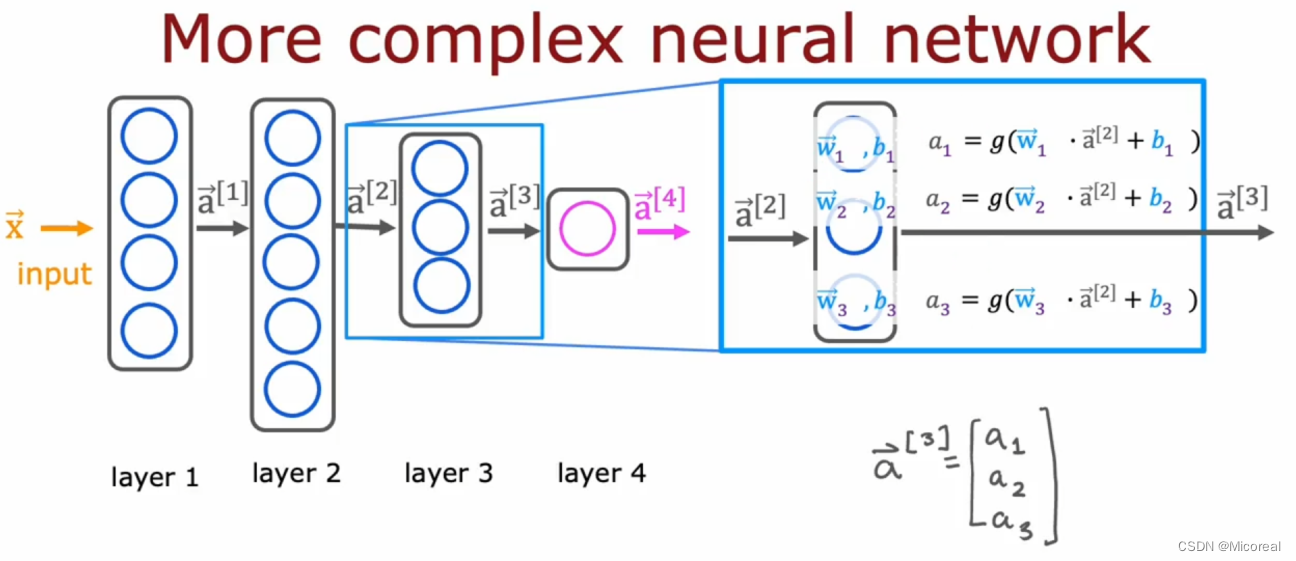
w * a + b 就是拿自己的w乘上之前输出的a向量形状为(n,1)然后得到一个新的a,这应该也能理解。
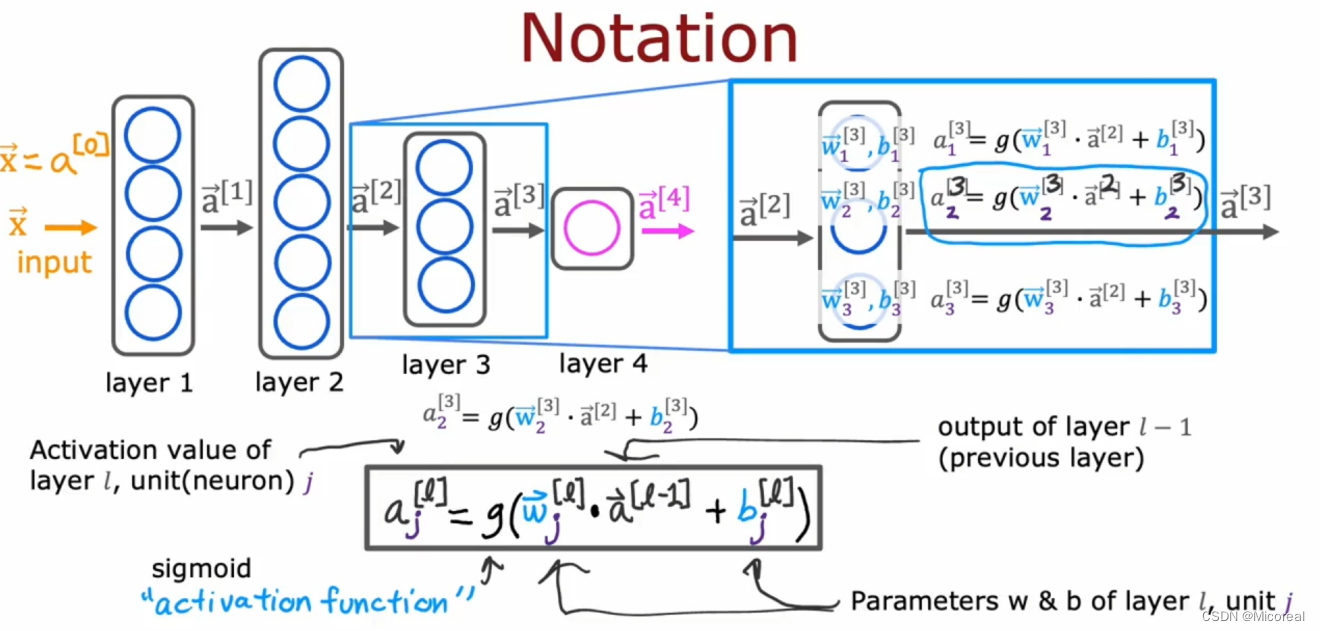
Forward propagation
前向传播的流程就是按照我们上文说的流程
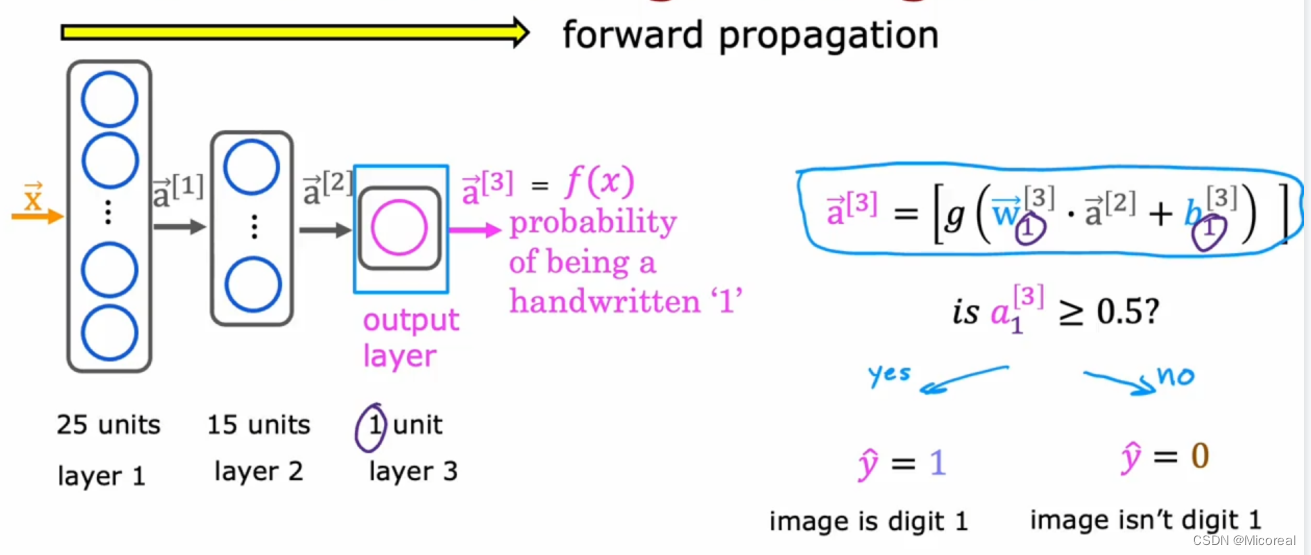
最后得到一个是某个东西的可能性。
Build a netural network ------code
由于视频还是在谷歌那边录的,所以吴恩达采用的张量流是采用tensorflow框架进行的实现,这边了解即可,我之前也介绍过tensorflow框架,而此篇更注意的是关于概念项的查缺补漏,所以这边就不再介绍这个框架,默认大家有一定的基础。
对于这么一个流程的神经网络训练,预测,正向传播的流程:

而这边大家需要记忆的不但是这些函数的基本组织方式,还有就是关于x 和 y的形状,比如说x的形状是(2,n),代表的就是有2个数据,n个属性,而y的默认输入却是(2),而非(2,1)这样子的格式的,这就需要我们注意力,说明在内部他有相关的自动转化机制。
而相对应的上文是关于tensorflow当中的实现,下面是关于python的实现:

上面的照片是在模拟简单的神经元计算,虽然这么定义有点麻烦,之后会再用别的方式进行加快速度。

上面这张照片就是我们自行去写一个模拟dense层的实现,这边注意一下我们构建的w矩阵的形状,我们需要想一下为什么要构建成(2,3)形状大小的w参数,为什么不是(3,2)大小的,这是很有说法的,为了之后的并行运算(这一部分还没用上并行运算),或者你也可以用矩阵来进行理解我们输入的x的形状是(1,2),我们想要输出的wx 的形状应该是a的形状,而a的形状很简单,取决于神经元的数量,故其形状应该是(1,3),所以(1,2)乘什么形状的矩阵会是(1,3),当然只有(2,3)。这个算一个小的剧透,所以来说w的构建需要这么构建,然后内部的计算自然就懂了吧。
AGI
这一部分主要就是科普向,可跳,没有什么知识向,主要讲解的是,对于人工智能未来发展的一些可能,吴恩达认为,未来的发展可能从模型的角度进行优化,原因就是我们使用的logistics相对于大脑的结构来说说,还是过于简单了,所以未来的发展可能朝向的更新角度就是提出新型的建模,其次就是在原有的训练方式上进行更新。
Matrix multiplication ------code
这个就是根据上文的实现方式的进行的修改,转而使用矩阵乘法替代掉dot product 点乘,因为如果存粹使用点乘的话,实际上实现的效率还是太低。
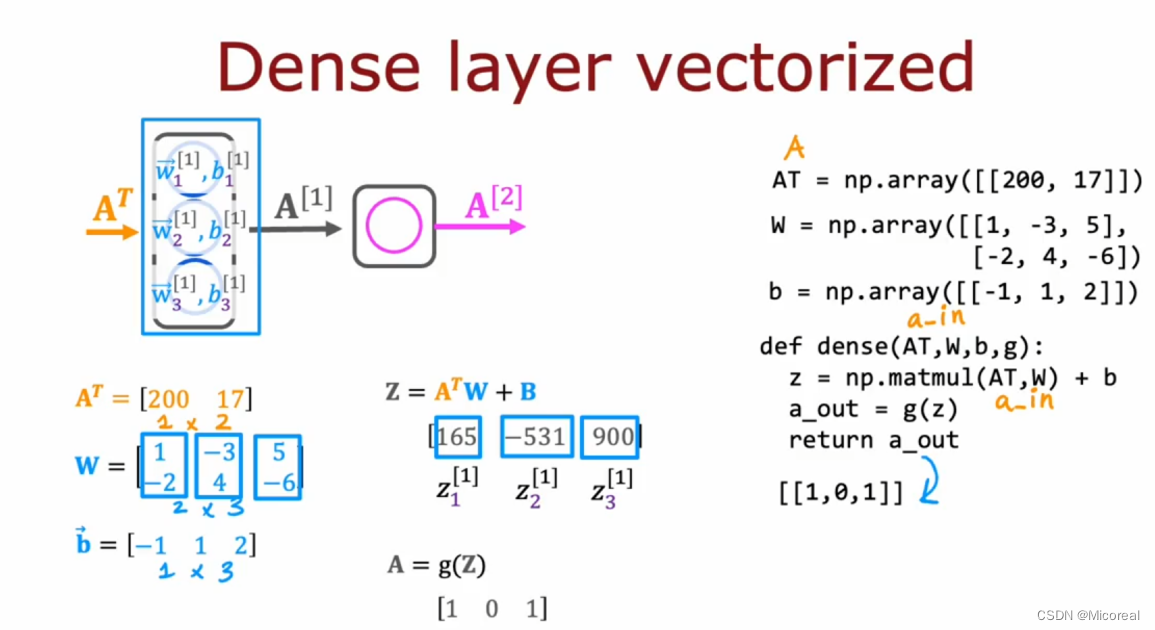
默认大家是已经学习过线性代数了,所以这边就不进行仔细的讲解。
Week2
Tensorflow— training details
这边主要讲解的就是tensorflow框架训练的主要流程:
比较简单的流程:
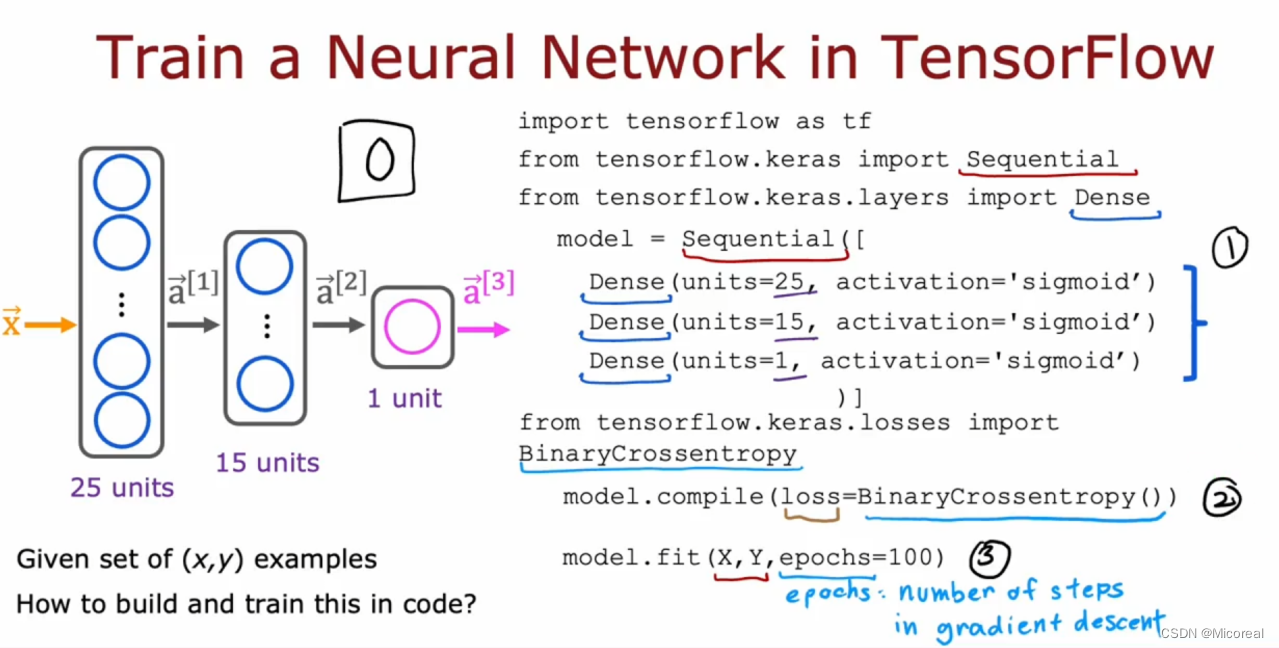
比较详细的:

用自己的话来说呢?第一步一般都是先根据需求与设计写一个模型,第二步就是写对应的loss函数,第三步就是开始训练,训练的时候会进行梯度下降,有个印象即可。
activation functions
这一部分就是对于激活函数的解释,首先在之前我们就已经学习过了sigmoid这一个激活函数,我们明白使用激活函数的目的是为了将数据映射到某一个区域之内避免梯度爆炸,其实也有一点batch-normalization的意思,但重要的并不是这个,这边给出相关的介绍:
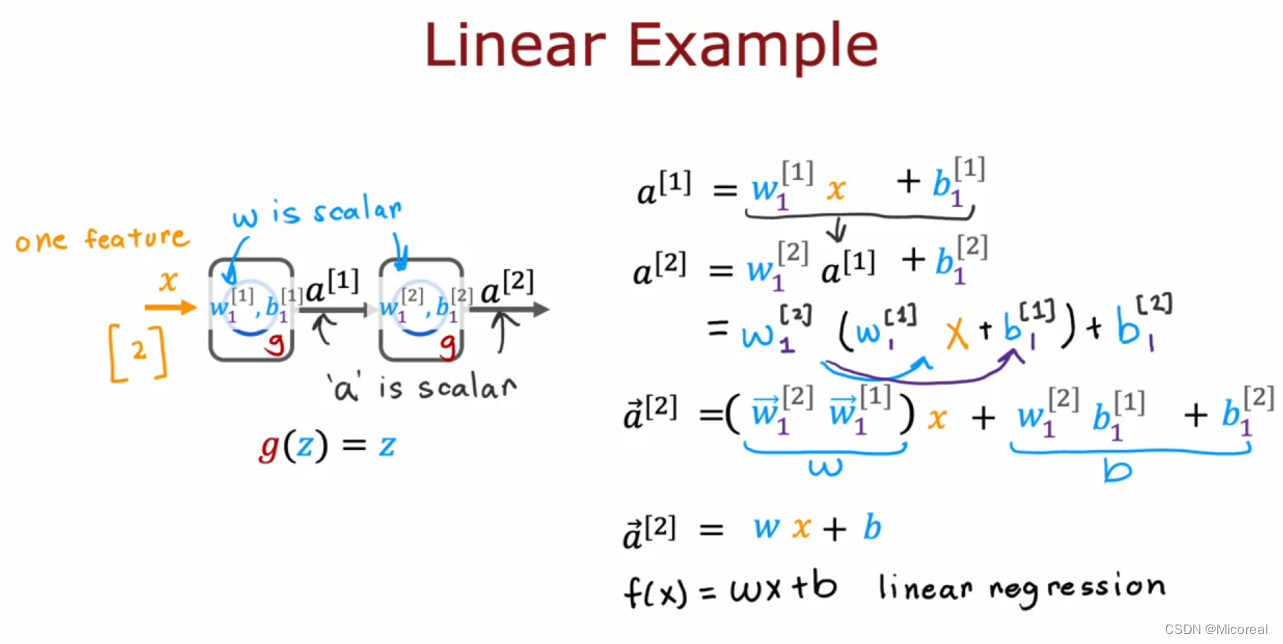
我们会发现当我们在没有使用激活函数的时候,或者使用线性激活函数的时候,经过化简之后,仍然可以化简成f(x) = w * x + b 这一个线性函数,这代表着我们在不使用激活函数的时候,不论使用多少层,最后模拟出来的曲线都还是一层,这是很不好的,所以需要采用激活函数。
但是使用激活函数又是一个很有技巧性的东西,吴恩达这边介绍了一种新的激活函数relu。
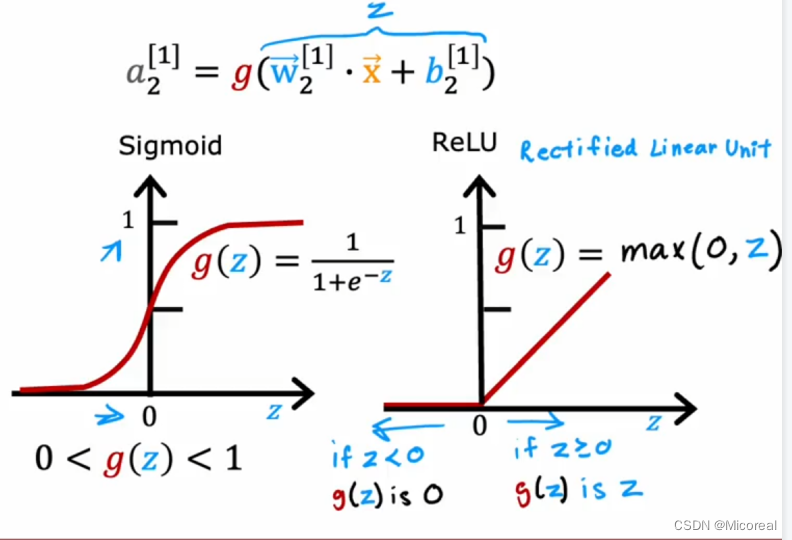
相比于sigmoid来说他平的地方只有靠左边的一侧,而sigmoid两侧都有,所以relu更不容易梯度消失,而relu由于梯度靠右侧都是1,故也不会发生梯度爆炸,所以吴恩达教授提出了一个比较常见的模型,在hidden-layyer当中使用relu激活函数,但是在output层使用的激活函数就需要根据自己想要的结果进行求取。
这边他的推荐是采用:
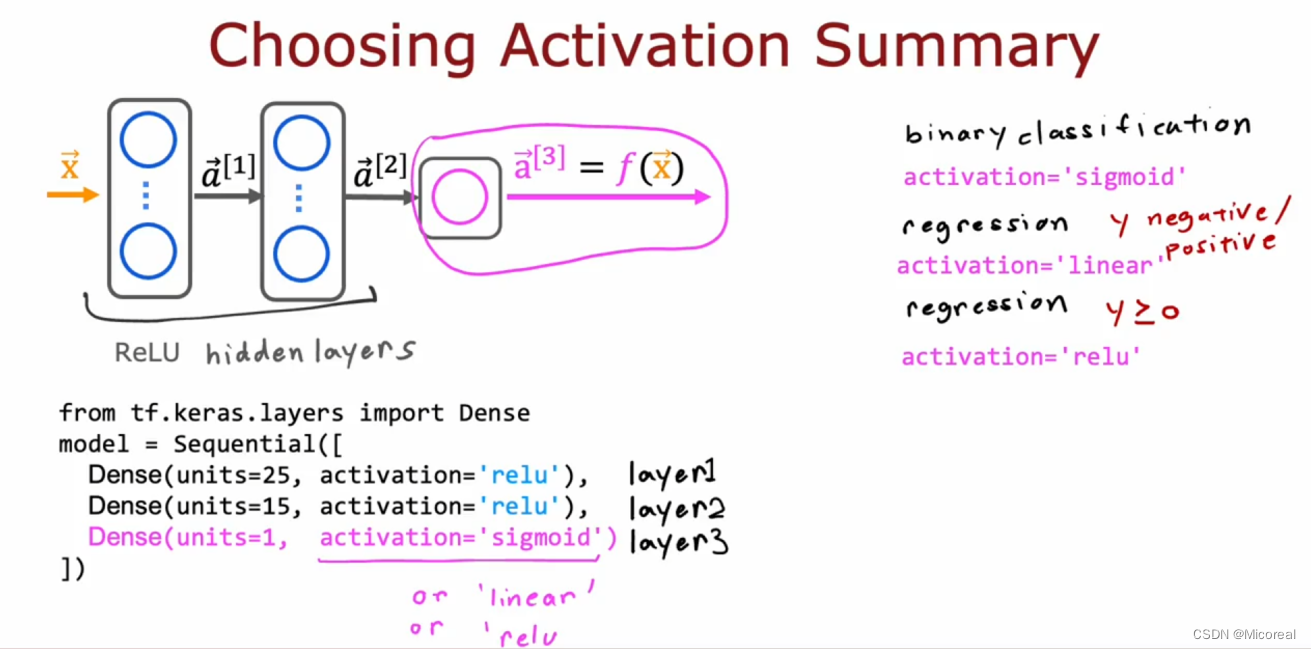
- sigmoid :适合的是二分类问题(binary classification)
- linear:适合regression当中输出既有负数也有正数(使用linear 也就是单层的dense)
- relu:适合regression中输出的值只有正数的情况。
Multclass and Softmax
首先为什么会存在softmax,这边就需要引入多分类问题,在之前我们讨论的分类都是二分类问题,这也就导致我们设置的最后一层的神经元只需要使用一个即可,而如果面对下面的这种情况,我们该怎么去写呢?

假设我们在做手写数字识别,我们希望他显示出来的是0-9对应的就是这些数字,这是关键的,我们该怎么去实现呢?
这边需要注意和多标签的区别,这个多标签后面会介绍,二者对比学习。
对于这一多类,我们希望他预测出来的数据输出是:
[[是0的概率,是1的概率,是2的概率,······是9的概率]]这样子的(1,10)的张量流。
所以对于我们的操作就很简单了

我们只需要采用这样子即可,至于激活函数为什么遮住,这边我们就需要再介绍一个新的激活函数了 softmax
首先我们先回想一下之前我们计算二分类的loss损失函数的时候,我们的公式是什么:

我们计算的过程中loss,我们实际上可以再等效回去,就是loss实际上等于-log(对应分类的概率),忘记的可以回去回顾一下【这边可以理解一下,当概率为0.5的时候loss比较大,当概率为1的时候loss为0】,而在这个式子当中我们是把输出默认当成概率的,但是我们的多分类问题可以吗?想了一下我们可以控制他输出在0-1之间(sigmoid),那还有没有什么条件吗?
解答一下:是不行的,原因是我们使用sigmoid只能让这些数据停留在0-1之间,但是还有一个条件是这些概率的和相加起来应该是1,但是sigmoid没办法进行控制,所以这些数据没办法看成是概率,这就需要我们再经过一层softmax激活函数来让这些数据变成真正的概率。
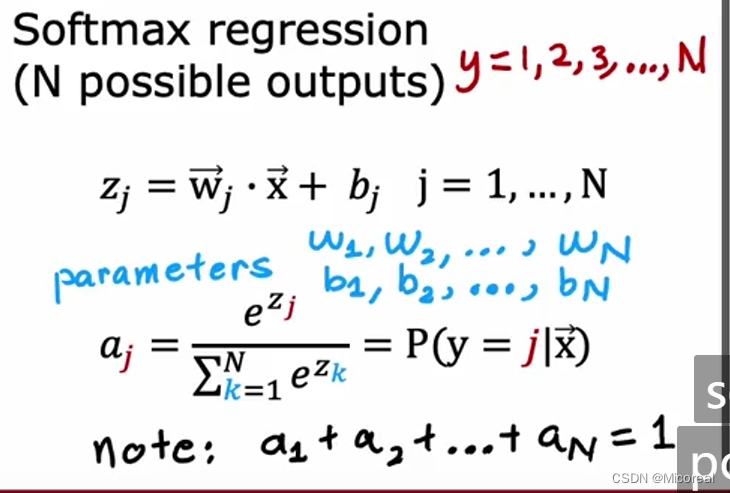
这就是softmax的式子,他将一层的输出都取exp,然后每一个数除以所有的数据,得到其概率。
然后这边给出多分类问题的loss函数

以及给出我们比较可视化的模型搭建流程:

但实际上我们还需要对其进行优化,在上面的模型搭建中,我们会发现很好理解,但是,在实际上的使用中,我们都会把softmax with loss 一起搭配使用。

原因见下:
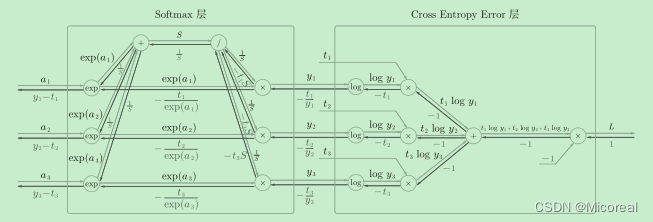
二者一旦结合,就会出现“魔术”般的效果:可以看到,Softmax层的反向传播得到了(y1−t1, y2−t2, y3−t3)这样“漂亮”的结果,这也是softmax函数所谓的“优雅的数学属性”。在tensorflow库中,一般也推荐使用统一的接口,而不是单独使用Softmax函数与交叉熵损失函数。
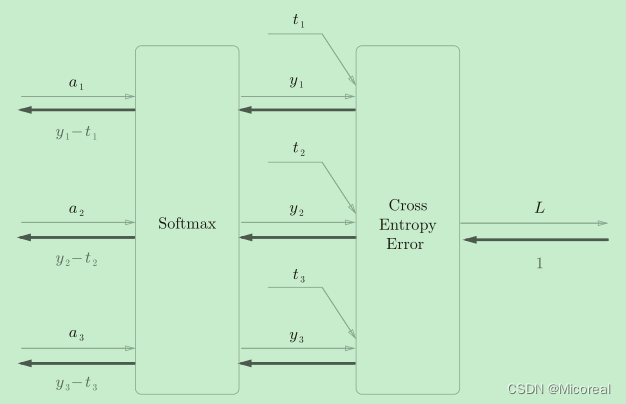
方便运算。
此处参照:链接
Classification with multiple outputs
对于多标签分类的理解呢?我们先区分一下和多类分类的区别:

比如上面就是一个简单的多标签分类问题,我们想要的输出是判断这张照片中是否存在car,bus,pedestrian。明显这是一个多标签的二分类问题。理解多类和多标签的区别之后,我们也才能知道什么时候需要使用softmax,什么时候不需要使用,而不是乱用。
而对于这个多标签的二分类问题loss采用之前的 binary_crossentropy 即可。
Adam
这边就不讲解具体的数学公式了,这个数学方向上的解释,在之前的系列已经讲解过,这边就聊一些感性的东西:
总而言之:
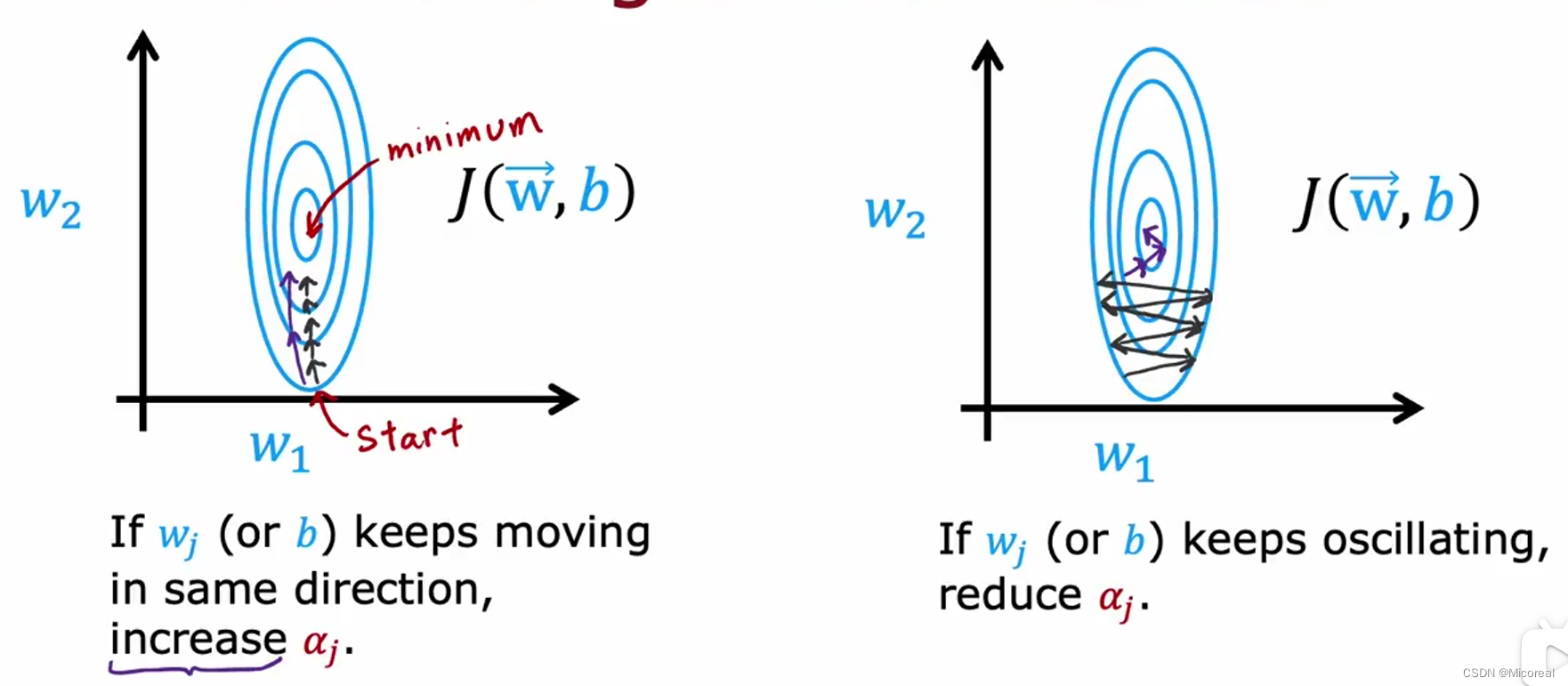
Adam你可以理解上在原本的梯度上加上了惯性,比如左侧的例子,我们原本是一小步一小步的朝中间走,但是使用了Adam之后,我们可以两步跨越,实际上就是我们这一步走的等效于本来的梯度下降加上上一次运动的量,也即惯性,相同的对于右侧图片的理解就是我们朝左朝右走很烦,我们只需要加上惯性力,就能使他左右动的很少,比较直的向上走。
具体的使用:

CNN(很简略,但是有点注意力机制的意思)
这边很感叹的是,吴恩达在讲解CNN思想的时候所才用的讲解居然是注意力机制,hh。
这边仅当一个科普
首先我们知道我们前面学习的dense,也就是FC全连接层
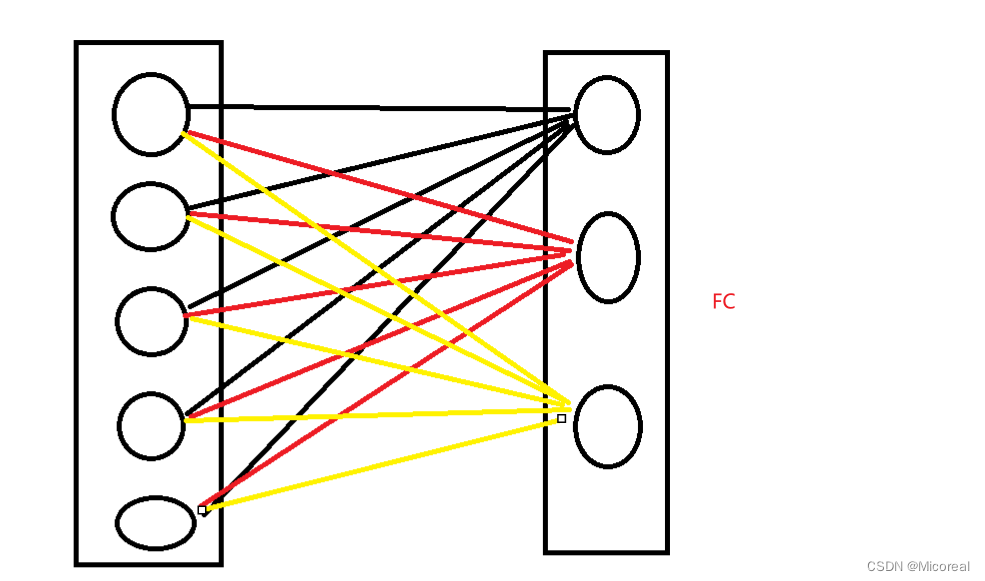
他实际上后面的一个神经元是前面一层所有神经元的输出作为x,然后和自己的w向量进行相乘,然后得到的,也就是说我一个输出的神经元实际上是关注到了前面5个或者说所有的神经元而输出的结果,但这么关注真的好吗?
CNN采用的就是带有限制性的关注:
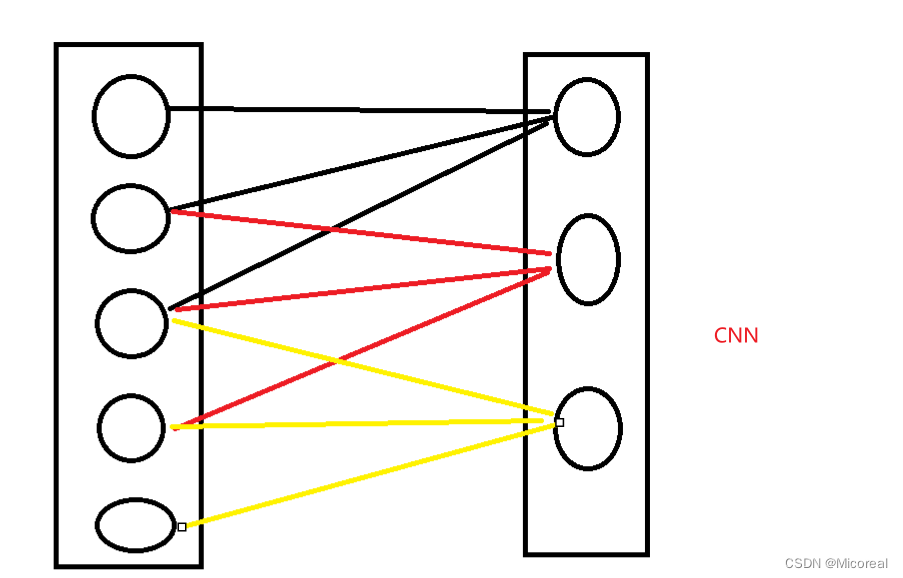
这个所采用的就是CNN。
这么做的好处:

训练更快,参数更少,需求的数据量更少,更不会产生overfitting。
而具体的CNN原理介绍,我想我就等之后的篇章再尽心介绍吧,或者可以先看我之前给出的相关的介绍。
Week3
Evaluating and choosing models
现在在上面的介绍当中,我们已经了解了一个模型训练的基本流程,以及基本的概念,那么现在这一步就是需要了解一下,当模型在训练的时候我们该怎么去挑选相关的模型呢?或者说在调整相关的超参数的时候,如何选择合适的一个超参数使得,这个模型是最好的。
这边直接给出结论吧,视频中吴恩达花了三个视频进行解释,这边直接进行讲解结论:

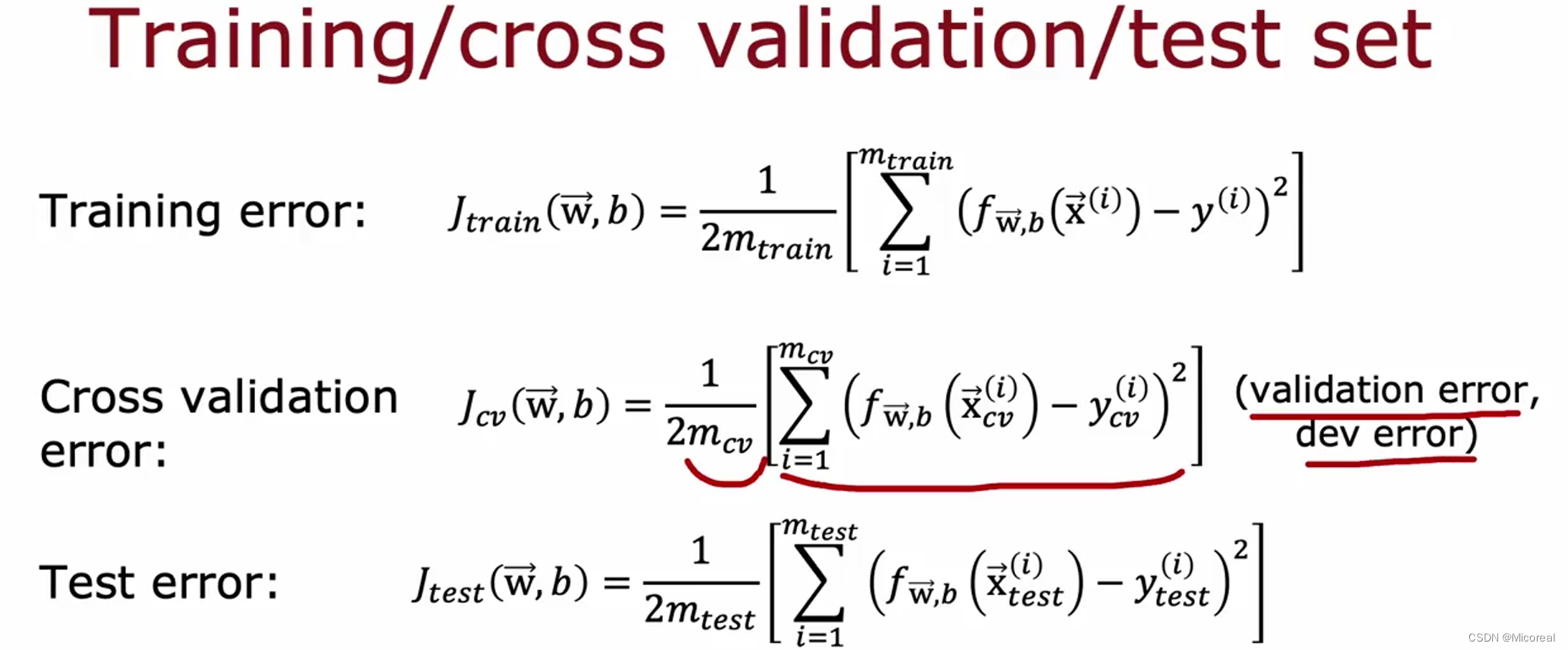
他将数据集进行划分,划分成三个部分:训练集(0.6),验证集(0.2),测试集(0.2),这三个部分,(先不考虑几折交叉验证),这边只考虑这些集合分别的作用,训练集,自然就是用来训练的,验证集,就是对训练好的model进行测试评分,最后根据多个model的valid的验证成果之后,挑选出最正确的model,然后拿这个模型去和test测试集进行检测,检测出后的结果就是你这个model的分数。
为什么要这么做呢?在以前的人们的做法都是只存在一个train和test两个集合,我们拿训练集训练数据,然后到测试集当中测试得到分数,最后多个model测试之后的分数再拿来对比,得到我们最优的test得分,然后作为我们模型的对应正确率去向外公布,但实际上这样子是很不好的,原因就是在这种传统的做法当中,我们实际上每一次模型的挑选过程中,我们是看了他在test测试集上的训练成果,然后判断是好的坏的,这实际上存在着信息泄露,我们人为的干涉了模型面向一个重未接触过的数据集上的训练成果明显之下,这是很不好的。
bias and variance
这一部分主要讲解的就是通过偏差和方差训练进行理解,首先先回顾一下之前展示的这张图:
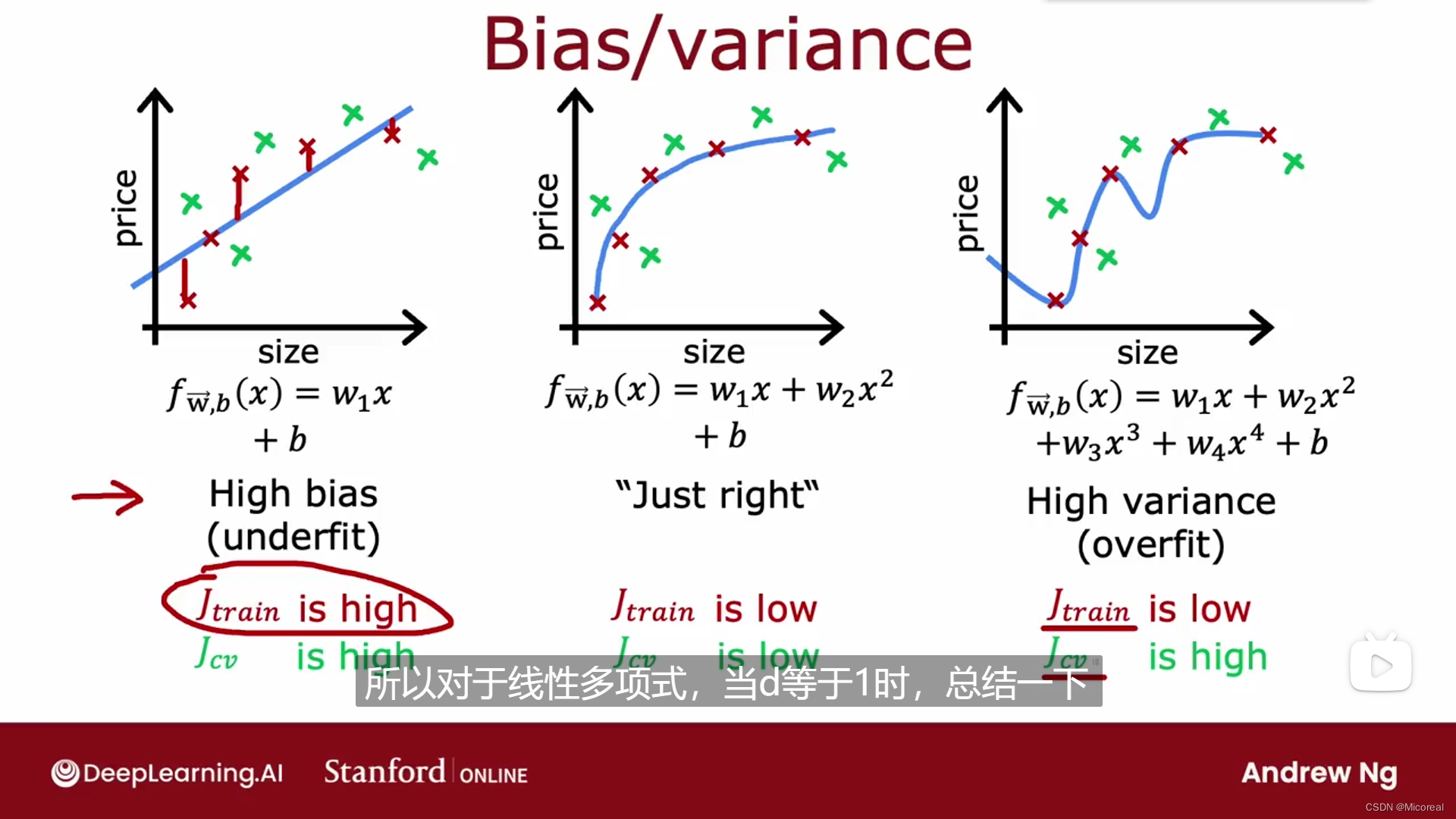
对于最左边的这张图我们之前说的是underfit,这一个的特征就是model下train和test的loss都很大,至于什么是大,之后会在讲解,这取决于你的任务,而对于第三张图,过拟合的train比较小,test集上比较大,对于这里先进行小小的回顾一下,然后我们把第一种情况称之为高bias,第三种情况叫做高variance。
然后就是我们对于多项式画出来的图,随着多项式的次数的增长而进行变化,我们可以理解一下过拟合,欠拟合产生的原因,欠拟合是我们定义的多项式的次数实在太低了,导致原本应该是二次函数的,我们拿一次函数去学习,这样子理解之下,我们不论怎么训练都没办法达到好的效果,而过拟合则是,我们多项式的参数太大了,数据量太小,导致他学习到的参数太多,只适用于训练集。
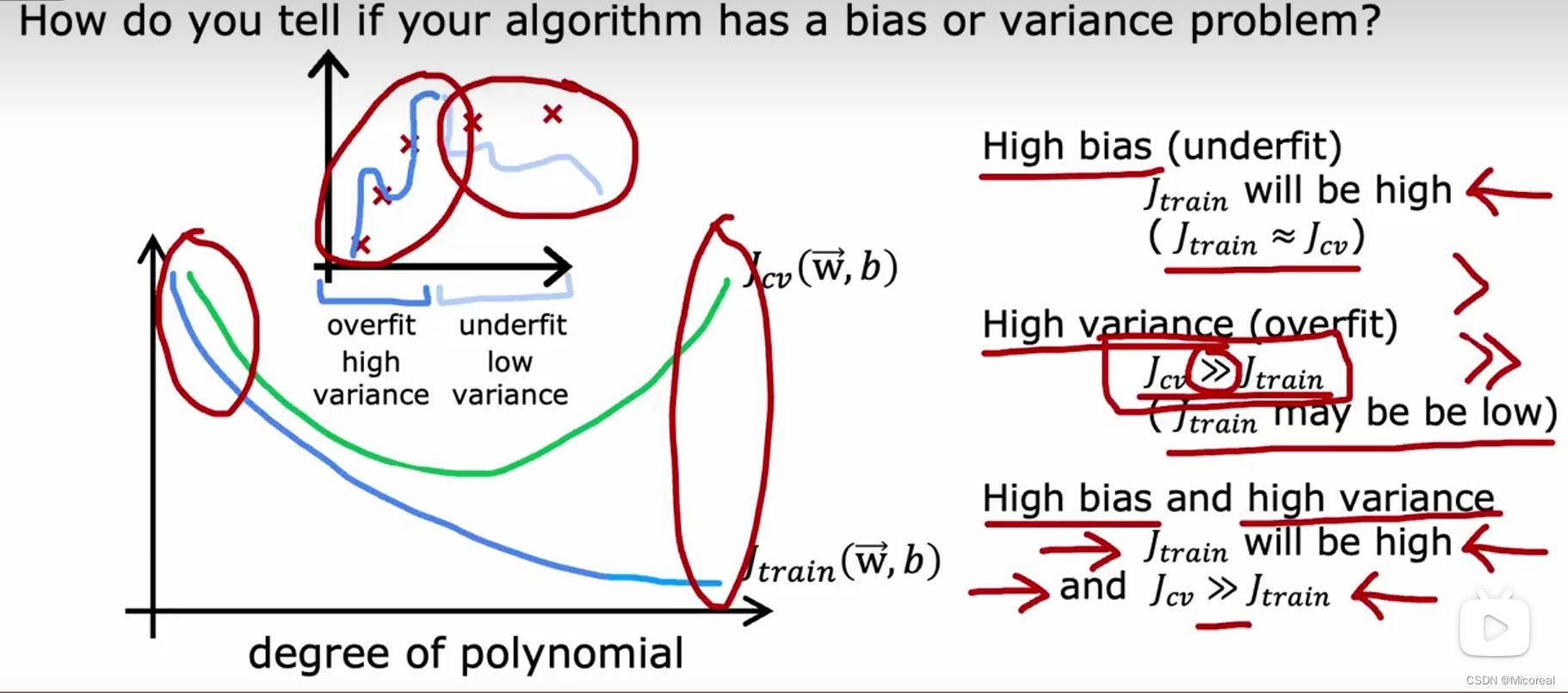
然后一般会出现三种情况:
- 高偏差bias:就是欠拟合,在这个时候J_train ≈ J_cv 。
- 高方差variance:过拟合,在这个时候J_train很小,J_cv会相对于大很多
- 高偏差和高方差:此时就是模型本身就有问题了,所以不论怎么训练都有问题,此时训练和测试的损失都很大,但是J_cv 远大于 J_train。
而如何进行选择合适的多项式的次数现在就是一个很大的问题,在机器学习当中一般多项式次数多一些并搭配正则化进行使用,这边看一下多项式的作用:
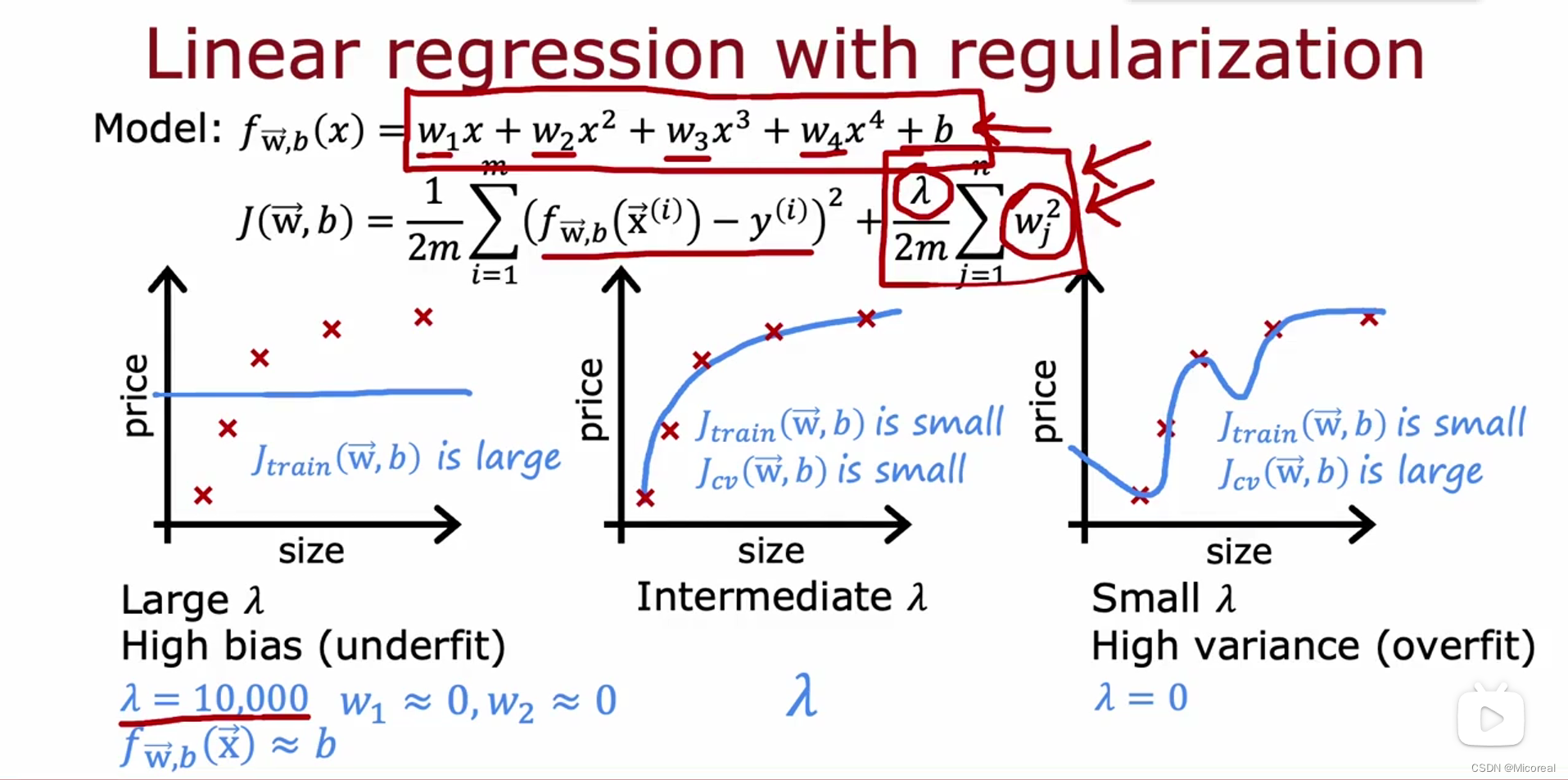
首先先感性的进行了解一下,正则化的力度产生的影响,对于正则化力度很大的到时候,实际上就是几乎所有的w都是0,肯定造成的就是underfit,而正则化力度太小造成的效果就是overfit。
而感性理解之后,我们看看具体的:
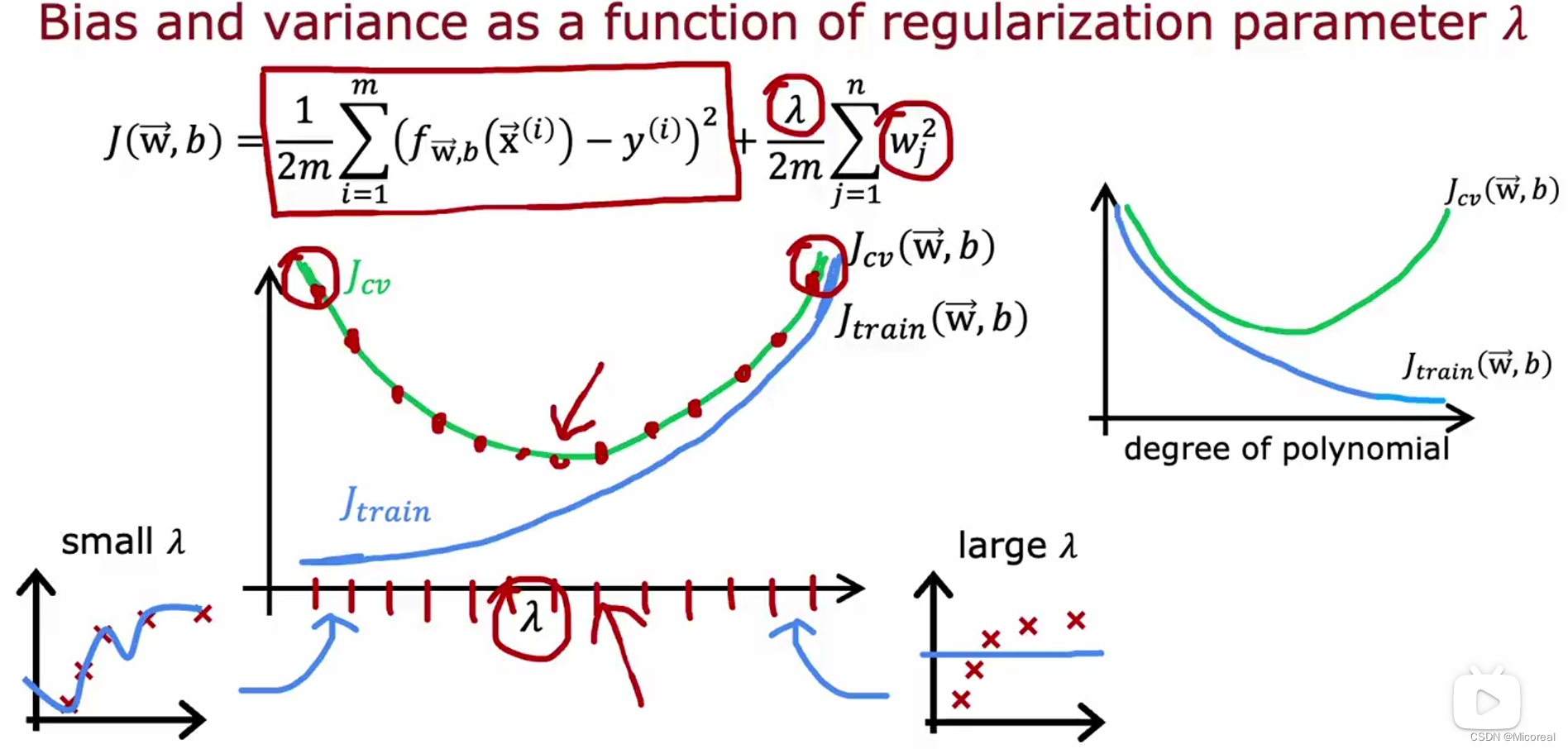
我们会发现随着正则化力度越大,实际上就是原本的J的镜像过程,但是为什么要使用正则化呢?原因就是更好去调整,相比于没有正则化来说。
这边讲一下什么是大,什么是小,重点就是要建立一个合理的标准:

而baseline 基本上采用的就是人类本身对于这项任务的表现,或者你想对比的那一个任务对于这一项任务的表现,或者就是你预期的表现,相比之下,才能比较出二者的大小区别。
然后这边讲解一下,数据量对于损失的影响:
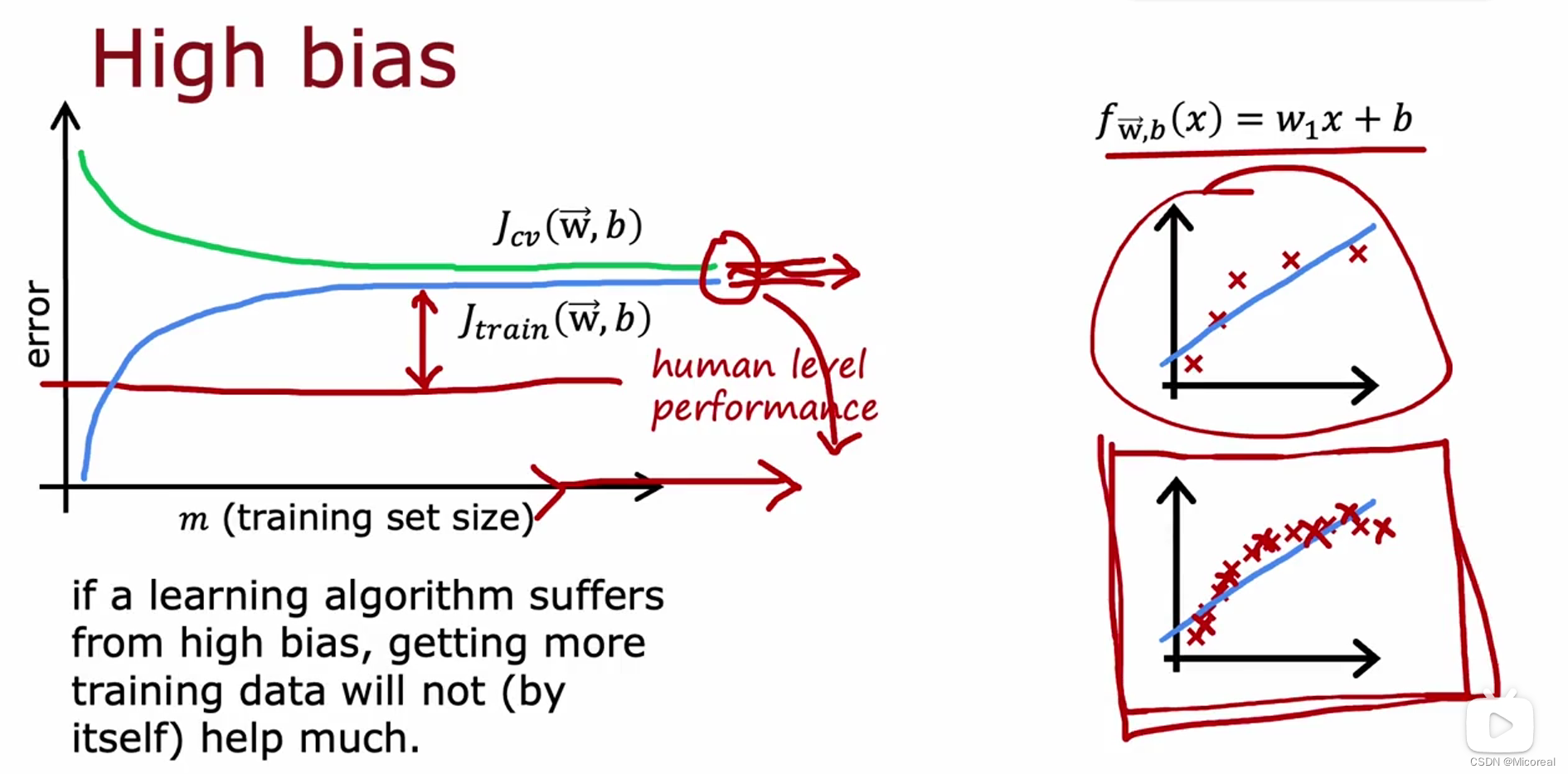
在高偏差的情况下,我们会发现不论怎么去设置训练集的数量,不断增加,都没办法降低损失。
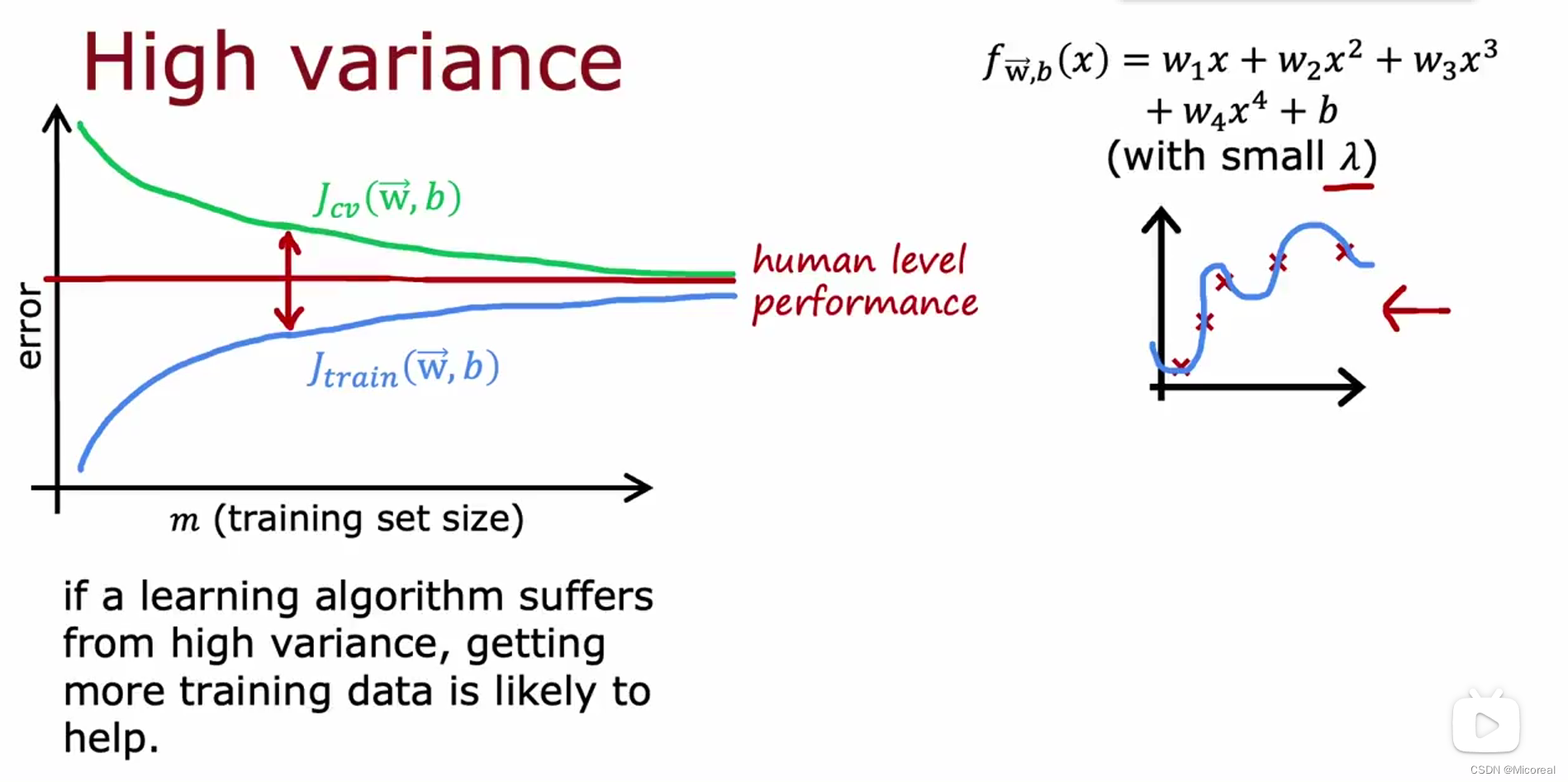
而相同的在高方差的情况下,数据集的增加是可以改善这种情况的。
然后下面就是关于高偏差与高方差之下,我们该怎么处理

高偏差(underfit):
- 增加特征数量
- 增加特征的多项式次数(到神经网络中就是加层数)
- 减少正则化力度
高方差(overfit):
- 获取更多的数据样本
- 减少特征的数量
- 增加正则化的力度
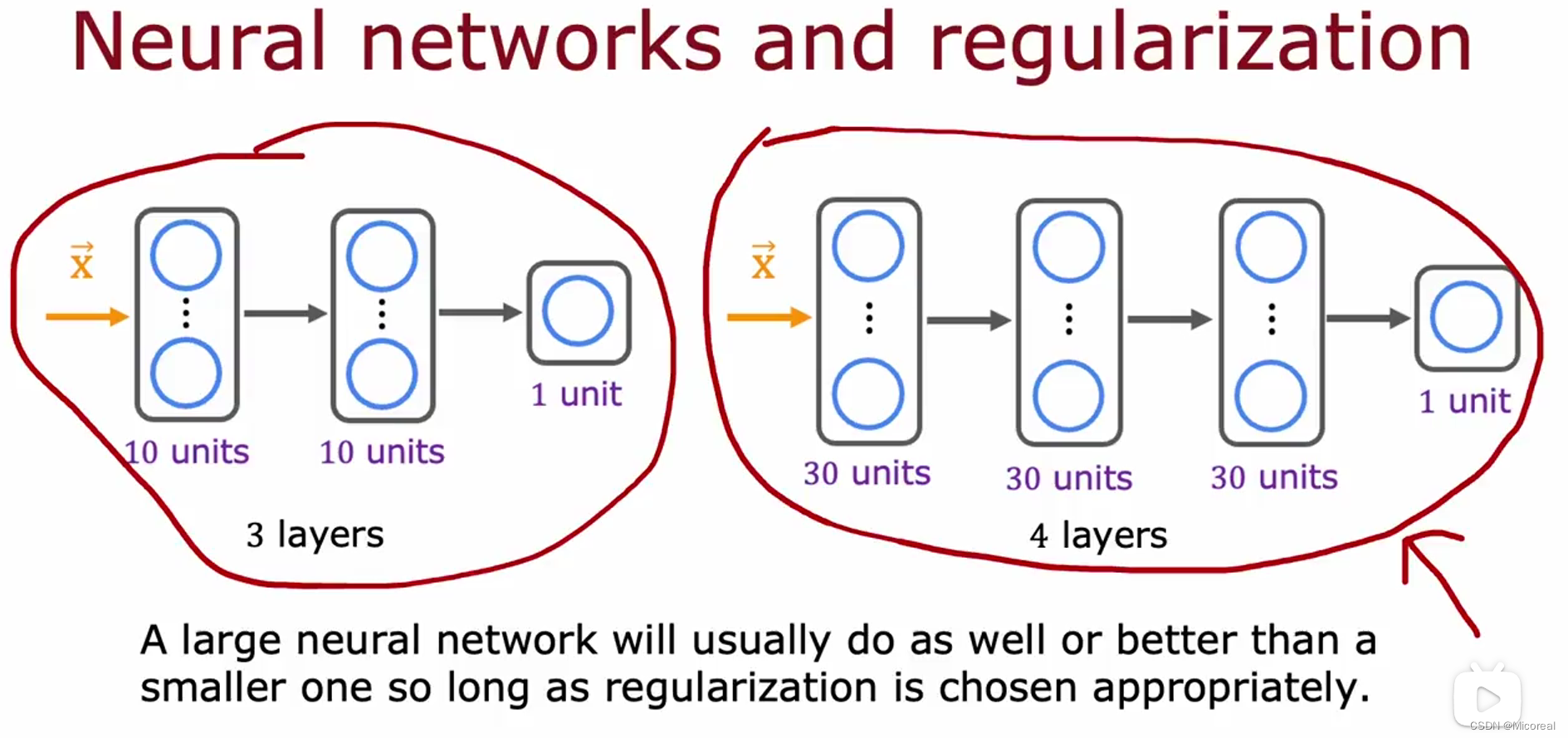
而面对多层神经网络来说,经过实验发现更大更深的神经网络搭配正则化也可以解决相关的问题,而几乎没有坏处,除了训练时长。
这边采用的是L2正则化,也就是我们之前讲解的正则化方式,而L1正则化,这边不进行理论介绍,只进行结论介绍,L1正则化解决的是让高项式的多项式次数为0,而不是L2的趋近于0.

Machine Learning development process
一般来说机器学习的整个流程:
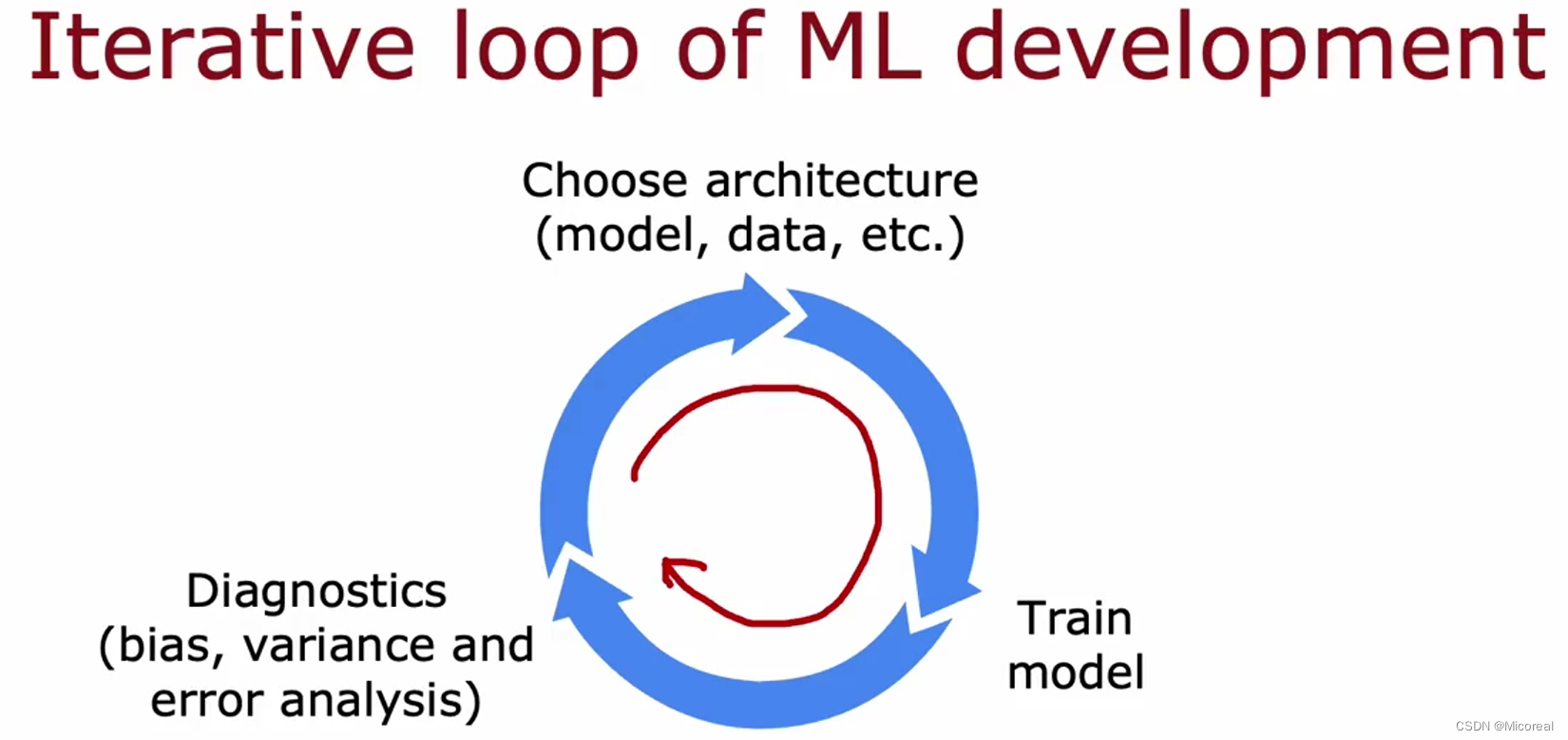
大概是这样子一个环,先准备最基础的model结构和一定的数据量,让后再训练一下,然后评估训练出来的效果的bias,variance 或者是对于error的分析,error分析等一下会进行讲解的,然后根据这一些,再去调整模型,然后接着训练,评估,不断循环往复。
然后这边主要讲解一下这些的区别:
- bias:主要看的就是你预估出来的效果 和 你model训练出来的效果相比之下,差距怎么样。如果差距较大就是bias,如果还好就接着看variance,判断一下验证集的预测正确率 和 训练集预测的正确率之间的差值,然后与,训练集的差值和baseline之间的标杆的差值,来判断variance。
- variance: 见上。
- error analysis:这个分析见下面的讲解。
error analysis
对于error analysis,来说一般做的就是统计工作,根据统计结果来进行分析:

这边举一个例子,吴恩达举的是一个判断是不是垃圾邮件的例子,随机取出100个分析出来是错误的例子,然后进行归类统计,比如分成下面的这四个类:
- 存在制药信息当中
- 拼写错误的
- 不常见的email地址来源
- 存在钓鱼信息的盗取密码的
- 图片中存在垃圾信息的
然后统计出来,1的有21个,2的有3个,3有7个,4有18个,5有5个。
通过上面的分析之后,我们可以发现重点错误在1和4当中,所以解决方法:

寻找更多相关于制药或钓鱼信息的垃圾邮件,或者选取更多的特征(和制药与钓鱼信息)来进行训练。
adding data
这边讲解的就是比较概念,我们可以人为的增加一些,主要是为了延续上文的内容,我们增加数据量,可以从调整data的角度来进行,通过调整X,但是Y不变。
比如说图像方面的图像增强,这也是比较经典的:
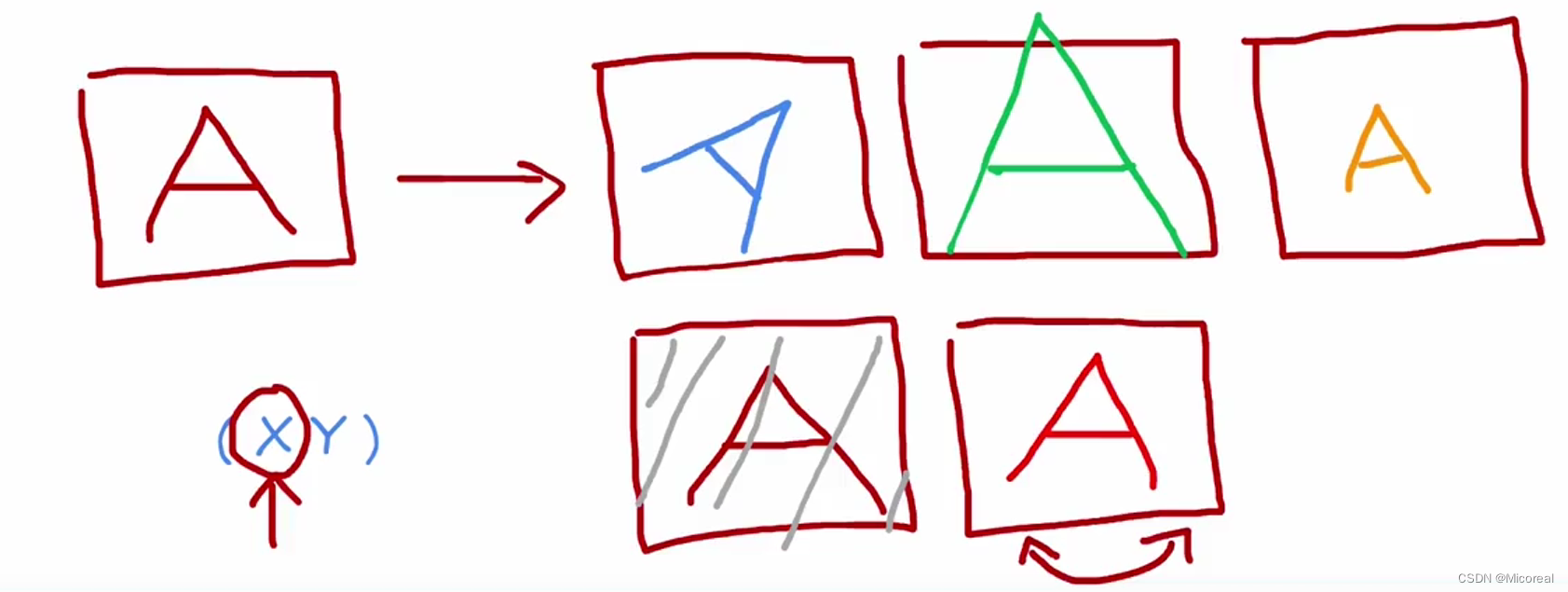
而相同的数据增强还有:

对数据进行扭曲处理,这往往是有用的,但是对于下面的那种对于其进行每个像素都加上噪点这种的,一般往往没什么效果,原因就是,在现实的识别当中,往往不会有这样子的识别出现。
还有就是面对语音的处理上:

我们可以给他加上一些环境音,这也是一种方式。
但这个方向一般都是图像领域才有这种方式的处理,或者说再举一个例子:比如关于OCR的训练上,我们想要让OCR去识别各种文字,在训练的前期,我们实际上是可以通过代码的方式进行合成出一系列的图片,来给他进行识别,通过不同字体,不同颜色,等等的方式来创造。
Transfer learning
迁移学习:就是先拿一个已经训练好的模型,别人已经做好的模型来进行fine-tune处理,得到我们自己想要的东西,比如文中我们实际上想做的是一个识别0-9数字的任务,但是我们的做法是先拿别人训练好的模型,然后去掉最后一层,换成我们自己的分类,然后再投入我们的image进行训练,这个时候可以选择只训练最后一层参数(数据量小),也可以选择训练所有层的参数(数据量大的话)。
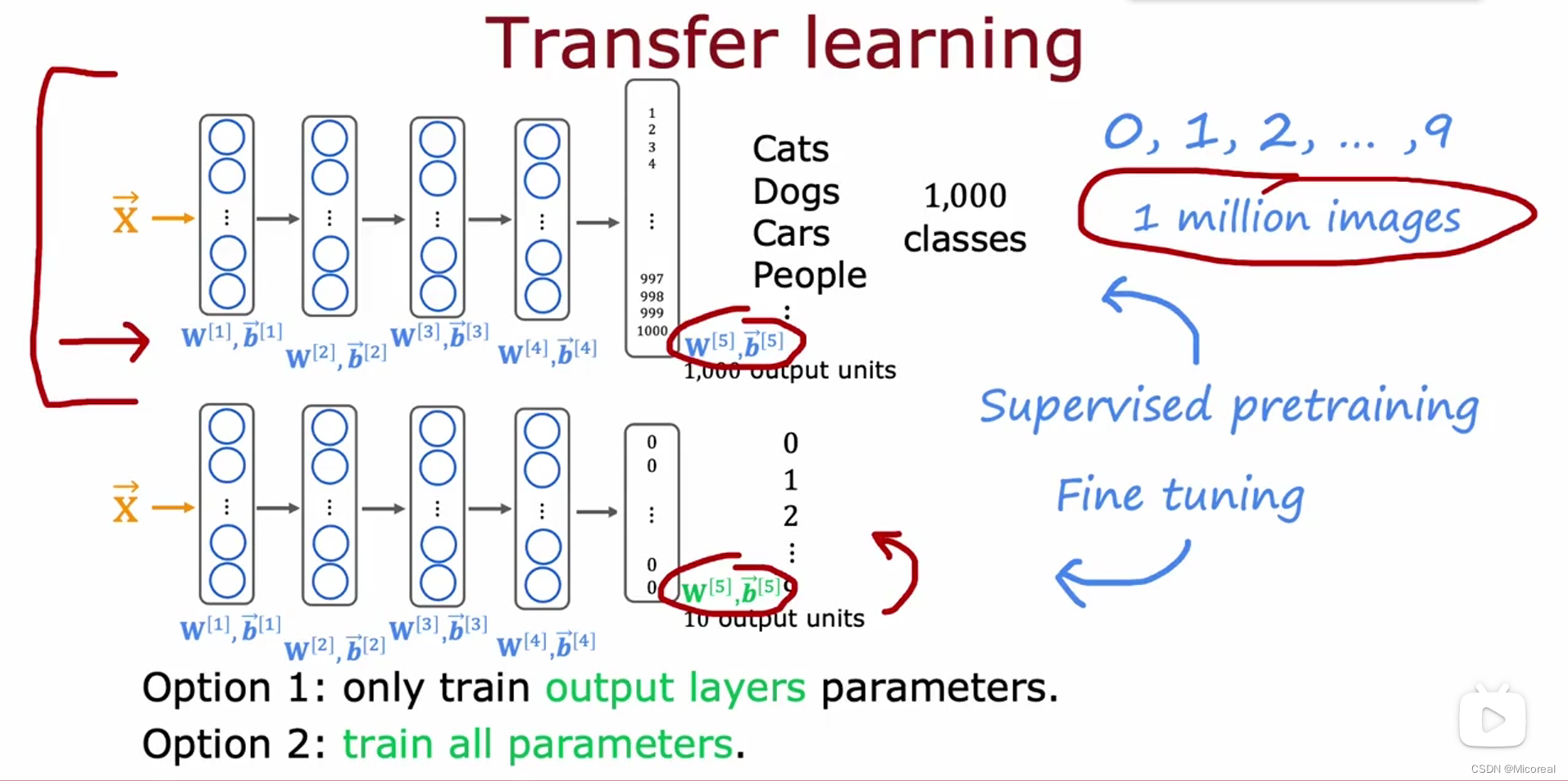
但对于transfer-learning来说,局限之处在于:我们的数据准备需要和原本的下载的那个模型一样,以及预处理方面也需要跟那个一样。
project
至于现在这一部分主要讲解的就是关于人工智能项目一些部署之类的,还有伦理上的问题,但他也没提出什么通用的解决办法,这就需要我们边检测,边添加相关的东西的防止了。
skewed datasets
当你的训练集达到正确的标签和错误的标签并不是很平分,也就是各个标签的差距很大,比如说我们判断一个人是否有病这么一个机器学习训练器之下,有时候由于这种病非常罕见,1000个人当中说不定只有5个人有,那么数据集收集好了,可能达到的效果是99.5%的没病标签,0.5%的有病标签,在这种情况下,我们拿去训练,最后的效果可能是让机器学到,不管有没有病,全部预测成没病,就会有99.5的正确率,这是非常可怕的。
原因就是对于医学来说,我们更希望的是不管有没有病,比较不确定的都预测为有病,以防万一,毕竟得了这些类型的病,不及时治疗,基本就等于死亡。
所以对于这种类型的带有倾斜数据的机器学习,我们便需要另外一种方式来辅助判断(混淆矩阵,精准度(precision),回归率(recall))

回归矩阵就是列出上述的四种可能,然后比较重要的是计算:(1一般代表那个比较rare 罕见的类别)
- precision(精确度):含义就是在真实(有病,没病)的情况下预测成有病的,这个反应的一般是预测的准确性。
- recall(召回率):含义就是在真实有病的例子中,我们预测的正确率,这个往往就是我们比较关注的,可以看这个值,来看出到底是不是一直预测某一种结果。
然后自然就是关于权衡精确率和召唤率,我们这边才用的是F1-score,下面先是关于介绍如何调整精确度和召唤率的:

我们可以通过手动调整阈值来调整,当阈值调高就是精准度上升,但是回归率会下降,当阈值下降,精准度下降,但回归率会上升。

而这边选择采用F1-score来进行综合评测,二者的综合属性,这个实际上趋向于二者都比较平均。
Week4
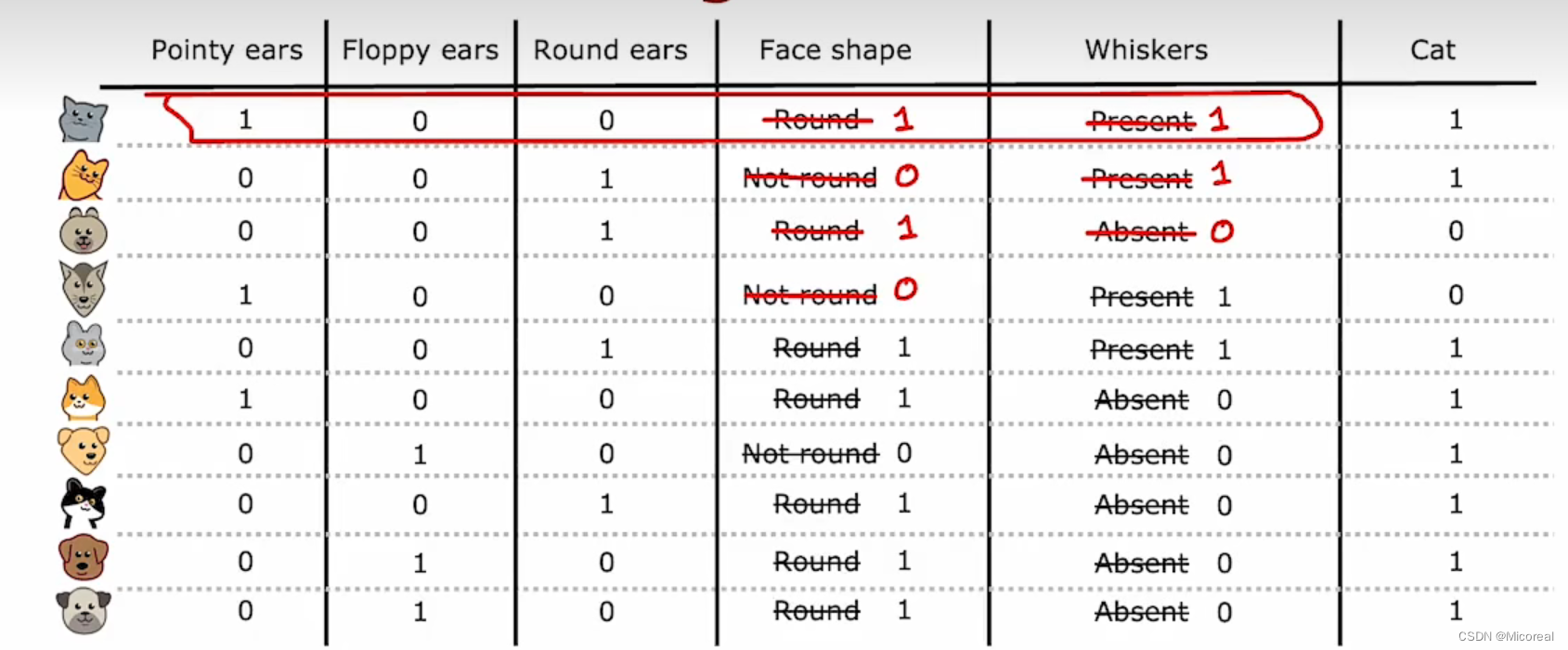
one-hot
具体见下:
补充:
当一个特征比如说上面的耳朵,拥有不止两种特征,比如pointy,floppy,round,三种特征,我们可以改变思路从三种也就是0,1,2表示变成(1,0,0),(0,1,0),(0,0,1)这样子的,也就是sparse到one-hot的变化,这一点到之后学习embedding还是很重要的。
Decision Trees
这个模型实际上,我们可以将其当作类似if-else 这种的嵌套条件,然后这种进去不断的判断,最后得到一个结果的这种就是决策树的相关的形状,当然还有串行决策森林,并行决策森林这种的说法,这个我之前也写过相关的代码,在另一个专栏,这边就先不进行解释。
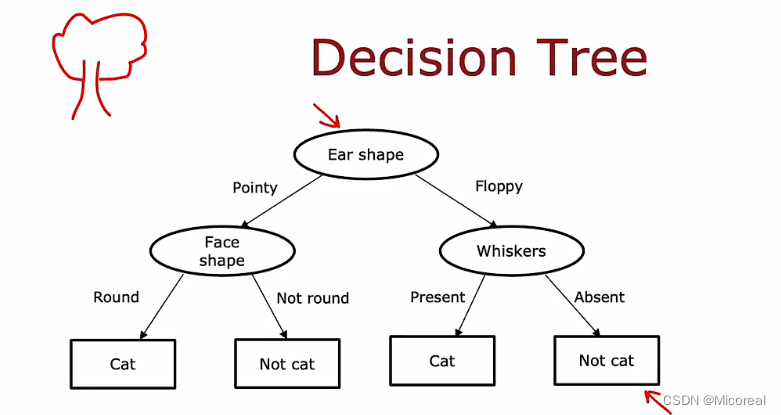
而评价这一堆的评价标准,我们采用的就是信息熵,如下,你应该会觉得很数据,当然多类的情况下也是和我们之前的sparse一样,当然我之前的专栏还介绍过Gini也是一种分类手段,但是这边就不进行介绍了,懂得大概的手段方式即可。

信息熵,越大代表着这一类的杂乱程度越大,而我们建立信息熵的标准就是,让信息熵变化最大的,更趋向于稳定的选项摆在比较高的层次,这样子就可以减少分类的次数,更容易分层更纯净的类别堆,于是你自然可以理解下面的图例,我们把这种计算得到的东西叫做信息增益:


而训练,自然就是在不断比较这个大小,不断往下递归建立的过程,这边就不细说了,需要关注的是:当你建立的最大深度max_depth越大实际上就类比于我们机器学习的多项式次数越大,或者说是神经网络结构越大(更深,更大)这样子的,而为了避免overfitting,我们能采用的就是束缚住他的发展,比如信息增益的阈值多少不变化,比如说最大深度设置为多大,等等一系列方法,当然,具体还是得我们到时候进行误差分析,以及损失分析。
而这个时候你会发现,我们上面的划分都是默认特征值是离散值,通过离散值的0-1,进行分堆,然后计算信息增益,那么对于连续值如何进行划分,或者说计算他的信息增益呢?(比如说划分猫和非猫这个决策树当中,我们选择了体重这一个特征,明显体重是一个连续值)
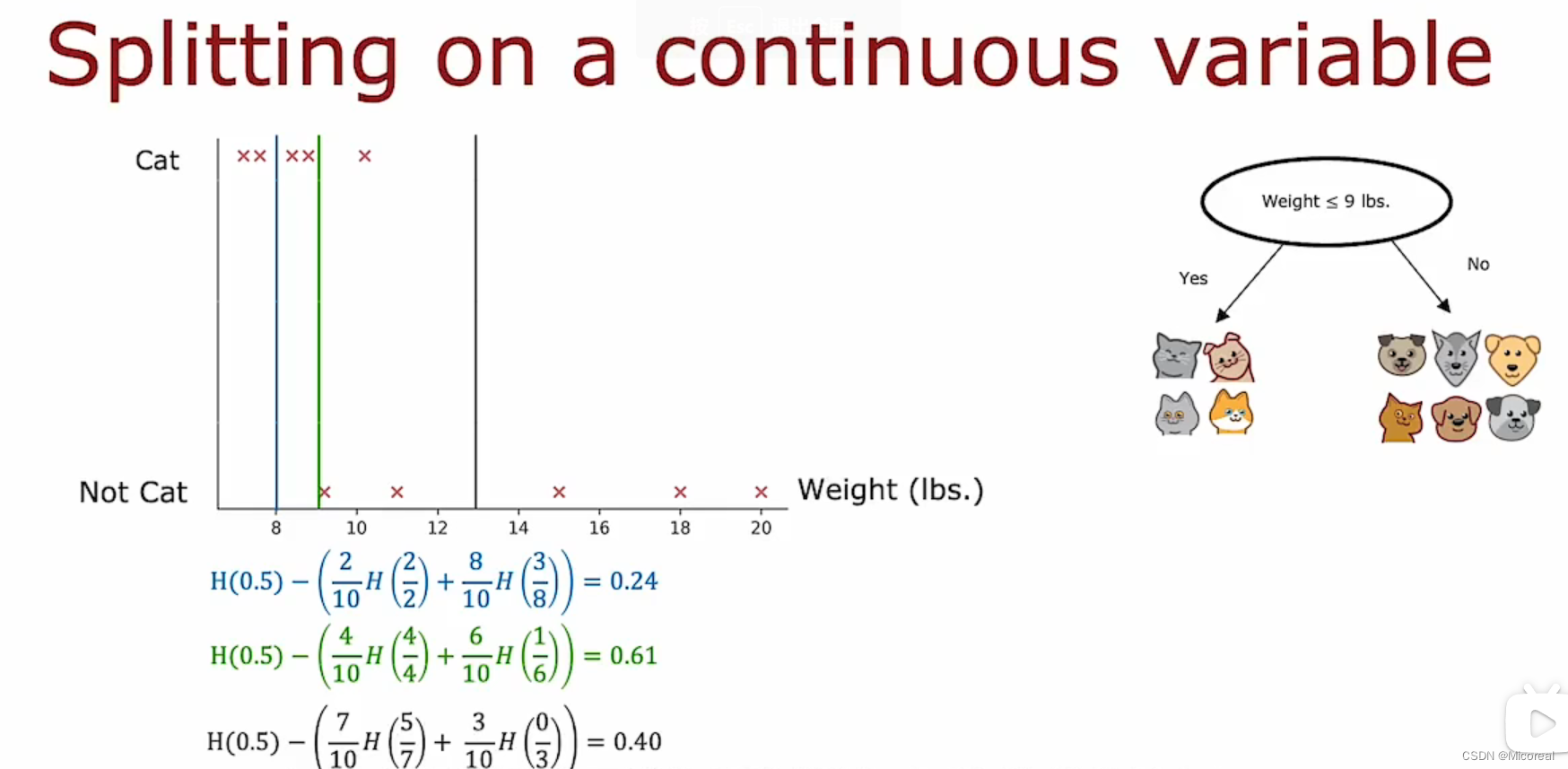
面对这个体重这个连续值,我们的计算方式是选一个值进行划分,然后不断计算他的信息增益,当信息增益达到最大的时候就按照这个来进行划分。
Regression Tree
上面介绍的是分类树,现在介绍一下回归树,实际上思想差不多:

只是在计算信息熵的时候便化成了计算variance(方差)。
multiple decision trees
使用多棵决策树(注意和决策森林还是有所不一样的,决策森林和多棵决策树之间的差别个人觉得一个比较重点的就是数据集,后面可以看到)
使用上面的决策树,大概率是有一定的坏处的,原因就是这种决策树对于树的高度的变化非常敏感,而为了不让他那么敏感,有一个方法就是建立多颗决策树,替代原本的一棵决策树。
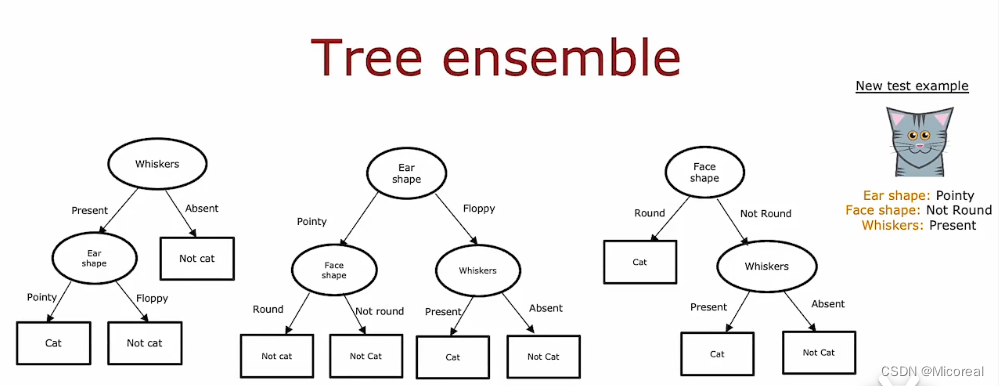
然后建树的细节就是,我们第一层直接分别以不同的特征开始,替代掉之前的,从第一层就开始算信息增益,最后自然可以得到多棵不同的树,而在这种情况下,我们的做法就是让这些树分别对这张照片进行预测,最后根据少数服从多数,得到最后的答案,在这种情况下,虽然每一棵树的能力小于上面的决策树,但是综合起来森林的能力却大过单单一棵树。
Sampling with replacement
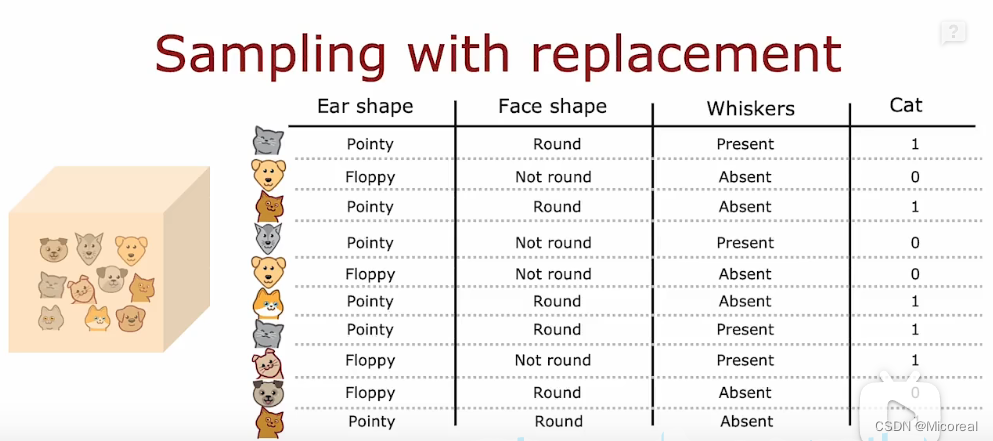
一般来说我们训练决策森林的时候所才用的都是有放回抽取,(就算抽到相同的数据也没有关系),这个如果要说数学理论的话,个人倒是没觉得有啥理论,估计是怕抽光数据吧,然后我们训练决策森林的时候所采用的并不是一棵树训练所有的数据集,而是一棵树训练其中一些数据,然后按照信息增益的方式进行生成树,由于数据选取比较少,所以大概率不会出现过拟合现象,而能力就会比正常的树来的差,但是我们采用的还是投票的这种方法,来让多棵树大于一棵树。
随机森林
实际上上面已经进行了讲解:

我们一般会选择B次,也就是造B棵树然后每一次都进行有放回的随机从数据集当中获取相关的数据,然后进行计算决策树的生成,共生成B棵,这样子的效果在相比于单棵树,是非常好的。而且事实证明,B的数量在大于100以上之后,就没有太大的改变了,仅仅只会增加训练时间,也就是说我们更希望当训练的树的棵树到达100棵之后,我们的优化更希望的是从别处优化,别再从数目这个超参数进行优化了。
然后还有这边还有一个随机的小技巧:

相同的我们也可以选择随机特征加入训练了,我们可以选择k的子集加入训练,而非k的全集,然后随机选取一个k<n的子集,这样子也可以做到让树完全不一样,而当特征的数量达到了好几十个的时候,一个方法是取k = 根号n,来进行随机。
而这个就是一个比较经典的集成学习中的并行思想(投票思想)Bagging。
XGBoost
相同的在集成学习当中还有一个Boosting(并行)的思想,这个的思想来源于我们的生活,在生活当中我们学习一件事情,往往先学一个大概,然后根据错误的再多次学习,XGBoost就是这种思路,带有一种刻意练习的感觉。
而在这种算法采用的有点类似残差的意思,或者就是说残差学习这种说法。

Decision Trees vs Neural Networks

对于神经网络和决策树的选择来说,吴恩达的讲解上,他对比了两种方法的不同:
我这边进行简单的总结:
- 决策树适合结构化的数据,比如可以直接用一个excel表示起来的,可解释性强,训练迅速
- 神经网络适合各种样式的数据,一般相比于决策树来说优势在于图片,语音,文字,但是训练上很慢,好处是可以使用迁移学习的思想,建立一个更宽广的随时可以fine-tune的模型,不像决策树每种用途都需要重新训练。















 1017
1017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









