







芯片原厂必学课程 - 第十篇章 - 基于 RISC-V SoC 的 1024 点 FFT 设计
10-02-06 高性能 RISC-V 内核的硬件设计
新芯设计:专注,积累,探索,挑战
文章目录
引言
本次项目主要设计了一个基于 RISC-V 指令集架构的 SoC,这是一个具有 1024 点的时频转换功能的 FFT 系统。在理想情况下,只要指令存储器和数据存储器的容量足够大,基本上可以实现任意点的 FFT。本章《基于 RISC-V SoC 的 1024 点 FFT 设计》针对 1024 点的 FFT,首先给出了 FFT 系统的整体架构和 RISC-V 内核的硬件设计。接着,对于 RISCV 交叉编译环境的搭建进行了相关的概述。最终,针对基于 RISC-V SoC 的 FFT 设计,构造了基于软硬件协同仿真验证的 UVM 框架,证实了大点数 FFT 的 C 软件程序及其 RISC-V 硬件设计系统功能的正确性。
NOTES:本文来自《芯片原厂必学课程 - 第十篇章 - 基于 RISC-V SoC 的 1024 点 FFT 设计》技术专栏
🌏 一、CPU 内核的硬件设计
对于 FFT 系统,其 RISC-V 内核的设计决定了整个系统的功能,其 RISC-V 内核的性能也决定了整个系统的性能。本次设计就是按照如下的 RISC-V CPU 的硬件架构设计图来实现的。
这里,按照流水级数的划分,对 RISC-V CPU 的各个设计阶段及其具体模块功能进行了详细的描述,如下所示。

✅ 1. 取指阶段:取指模块是基于异步复位的时序逻辑来设计的,能够对指令存储器进行取指操作,同时也具有地址自增和复位置位的逻辑功能。同时,在控制器的操纵之下,也可以实现相应的地址跳转和流水暂停的功能等等。
✅ 2. 译码阶段:译码模块主要是基于不存在优先级的查找表的组合逻辑来设计的,对基本整数指令和标准乘法指令进行译码操作,从而得到相应的指令操作码 opcode、寄存器读地址 raddr、寄存器读数据 rdata、寄存器写使能 wea、寄存器写地址 waddr、立即数 imm 和偏移量 shamt 等等。其中,通用寄存器堆在第二级流水设计中,提供了一组 32 个 32 位宽的寄存器集合,以同步写、异步读的方式来实现数据的暂存功能。
✅ 3. 执行阶段:执行模块是基于各种不同的计算单元以及数据选择器的组合逻辑来设计的。其中,计算单元集成了高密度的高性能硬件逻辑单元以及基于 DSP 的专用乘法器等等,进而提高了内核数据的实时处理性能。另外,对于 FFT 的设计中,以 C 软件程序的优化设计来消除可能存在的除法指令,以逻辑左移或者倒数乘法的方式来替代可能存在的除法操作。同样的,通过加法器的补码求和的实现方式,也可以代替减法器的硬件实现。
此外,对于访存来说,访存会在执行阶段才能够识别出访存指令的相关信息,通过向总线发出内存访问请求,从而与外部的存储器进行数据交互。对于写回而言,在执行阶段结束的下一个时钟的上升沿,就可以把数据结果存储到存储器中或者写回到寄存器中。当结束了这一系列操作的时候,PC 指针就会自增或者跳转等等,为下一步的程序做准备。对于 PC 指针的跳转以及流水的暂停,是通过 RISC-V 内核中的专用控制器来实现的。这里,也给出了 RISC-V 处理器的 RTL 电路图

🌏 二、CPU 内核的时序分析
在 Vivado 中,以 RISC-V CPU 为顶层,分别对工程进行综合和对 CPU 的工作时钟进行时序约束。主要是通过 Vivado 的 GUI(Graphical User Interface,图形用户界面)添加的时序约束,约束 CPU 主时钟的工作周期为 11.165ns。
create_clock -period 11.165 -name clk -waveform {0.000 5.583} clk
在点击“Create Clock”并应用之后,会产生相应的 XDC(Xilinx Design Constraints,赛灵思设计约束)命令,即“create_clock -period 11.165 -name clk -
waveform {0.000 5.583} clk”。通过时序约束 RISC-V 内核的时钟频率,最终产生的设
计时序概要如下所示。
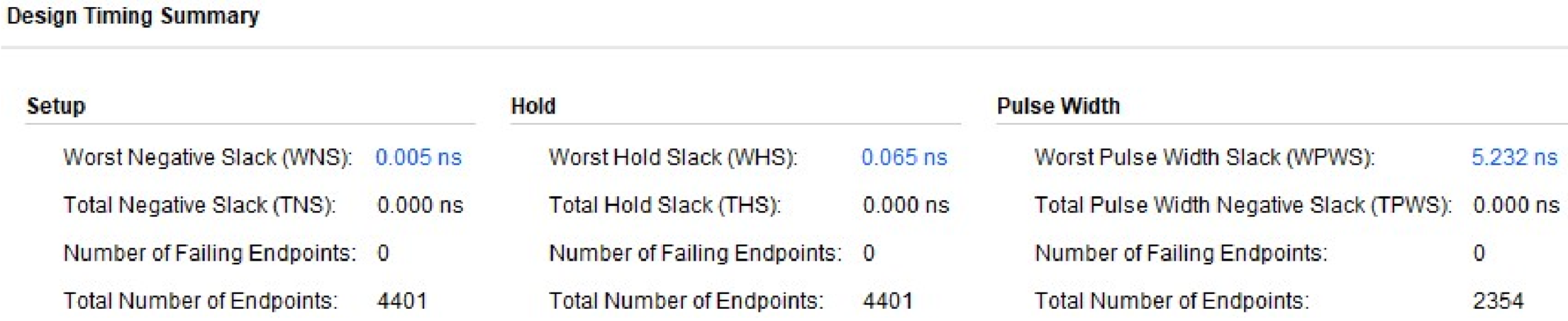
可以发现,在建立时间和保持时间达到边界值的时候,RISC-V 处理器最高可运行的时钟频率约为 89.57 MHz。由此可知,本次工作在追求小面积低功耗的同时,依旧保持着处理器良好的性能,达到了良好的 PPA(Power、Performance and Area,PPA)折衷设计节点。
追根溯源,其折衷设计主要分为两点。其一,由于指令存储器和数据存储器放置在 CPU 之外,这就避免了内存读写操作导致的时序恶化。其二,加法器和乘法器都是经过逻辑优化的。对于较为复杂的计算单元,采用了超前进位加法器和专用的 DSP 乘法器,以高性能数字信号处理 IP 来有效地减少了 CPU 的关键路径,从而极大地提高了处理器的主频,实现了高性能的 RISC-V 内核的硬件设计。
















 2173
2173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











