









 本文介绍了一个使用深度学习实现的项目,针对50种环境声音进行分类,包括数据提取、特征转换、数据增强及模型构建。通过ESC-50数据集训练,采用Mel-Spectrogram并应用多种数据增强技术提升模型性能。
本文介绍了一个使用深度学习实现的项目,针对50种环境声音进行分类,包括数据提取、特征转换、数据增强及模型构建。通过ESC-50数据集训练,采用Mel-Spectrogram并应用多种数据增强技术提升模型性能。
【人工智能项目】深度学习实现50种环境声音分类

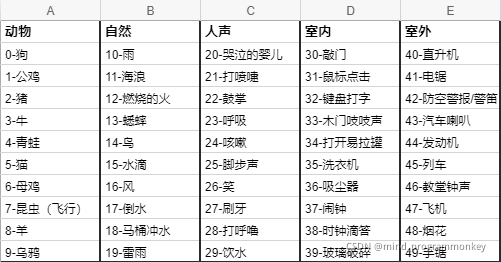
任务说明
本次准确识别5种大类,共计50种小类的音频。每个音频文件时长5秒,格式为wav。
数据集来自freesound.org公开项目,从中手动提取。训练集共计1600个,测试集400个。
导包
import os
import random
import numpy as np
import pandas as pd
import librosa
import librosa.display
import matplotlib.pyplot as plt
import seaborn as sn
from sklearn import model_selection
from sklearn import preprocessing
import IPython.display as ipd
前期准备
# define directories
base_dir = "."
esc_dir = os.path.join(base_dir, "ESC-50-master")
meta_file = os.path.join(esc_dir, "esc50.csv")
audio_dir = os.path.join(esc_dir, "audio/audio/")
# load metadata
meta_data = pd.read_csv(meta_file,header=None,names=["filename","target"])
meta_data
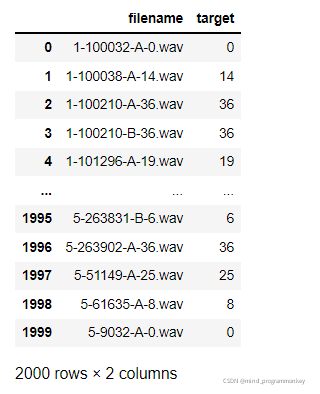
# get data size
data_size = meta_data.shape
print(data_size)
(2000, 2)
加载数据
# load a wave data
def load_wave_data(audio_dir, file_name):
file_path = os.path.join(audio_dir, file_name)
x, fs = librosa.load(file_path, sr=44100)
return x,fs
# change wave data to mel-stft
def calculate_melsp(x, n_fft=1024, hop_length=128):
stft = np.abs(librosa.stft(x, n_fft=n_fft, hop_length=hop_length))**2
log_stft = librosa.power_to_db(stft)
melsp = librosa.feature.melspectrogram(S=log_stft,n_mels=128)
return melsp
# display wave in plots
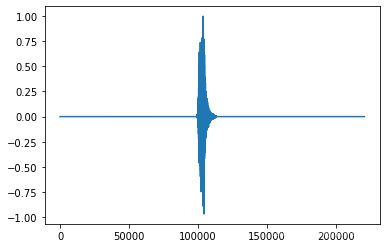
def show_wave(x):
plt.plot(x)
plt.show()
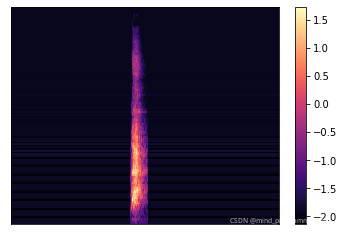
# display wave in heatmap
def show_melsp(melsp, fs):
librosa.display.specshow(melsp, sr=fs)
plt.colorbar()
plt.show()
# example data
x, fs = load_wave_data(audio_dir, meta_data.loc[0,"filename"])
melsp = calculate_melsp(x)
print("wave size:{0}\nmelsp size:{1}\nsamping rate:{2}".format(x.shape, melsp.shape, fs))
show_wave(x)
show_melsp(melsp, fs)
wave size:(220500,)
melsp size:(128, 1723)
samping rate:44100
ipd.Audio(x, rate=fs)
augment audio data
# data augmentation: add white noise
def add_white_noise(x, rate=0.002):
return x + rate*np.random.randn(len(x))
x_wn = add_white_noise(x)
melsp = calculate_melsp(x_wn)
print("wave size:{0}\nmelsp size:{1}\nsamping rate:{2}".format(x_wn.shape, melsp.shape, fs))
show_wave(x_wn)
show_melsp(melsp, fs)
wave size:(220500,)
melsp size:(128, 1723)
samping rate:44100
ipd.Audio(x_wn, rate=fs)
# data augmentation: shift sound in timeframe
def shift_sound(x, rate=2):
return np.roll(x, int(len(x)//rate))
x_ss = shift_sound(x)
melsp = calculate_melsp(x_ss)
print("wave size:{0}\nmelsp size:{1}\nsamping rate:{2}".format(x_ss.shape, melsp.shape, fs))
show_wave(x_ss)
show_melsp(melsp, fs)
melsp size:(128, 1723)
samping rate:44100

ipd.Audio(x_ss, rate=fs)
# data augmentation: stretch sound
def stretch_sound(x, rate=1.1):
input_length = len(x)
x = librosa.effects.time_stretch(x, rate)
if len(x)>input_length:
return x[:input_length]
else:
return np.pad(x, (0, max(0, input_length - len(x))), "constant")
x_st = stretch_sound(x)
melsp = calculate_melsp(x_st)
print("wave size:{0}\nmelsp size:{1}\nsamping rate:{2}".format(x_st.shape, melsp.shape, fs))
show_wave(x_st)
show_melsp(melsp, fs)
wave size:(220500,)
melsp size:(128, 1723)
samping rate:44100
ipd.Audio(x_st, rate=fs)
Split training dataset and test dataset
# get training dataset and target dataset
x = list(meta_data.loc[:,"filename"])
y = list(meta_data.loc[:, "target"])
x_train, x_test, y_train, y_test = model_selection.train_test_split(x, y, test_size=0.2, stratify=y)
print("x train:{0}\ny train:{1}\nx test:{2}\ny test:{3}".format(len(x_train),
len(y_train),
len(x_test),
len(y_test)))
x train:1600
y train:1600
x test:400
y test:400
Transform wav data to mel-stft array
freq = 128
time = 1723
# save wave data in npz, with augmentation
def save_np_data(filename, x, y, aug=None, rates=None):
np_data = np.zeros(freq*time*len(x)).reshape(len(x), freq, time)
np_targets = np.zeros(len(y))
for i in range(len(y)):
_x, fs = load_wave_data(audio_dir, x[i])
if aug is not None:
_x = aug(x=_x, rate=rates[i])
_x = calculate_melsp(_x)
np_data[i] = _x
np_targets[i] = y[i]
np.savez(filename, x=np_data, y=np_targets)
# save raw training dataset
if not os.path.exists("esc_melsp_all_train_raw.npz"):
save_np_data("esc_melsp_all_train_raw.npz", x_train, y_train)
# save test dataset
if not os.path.exists("esc_melsp_all_test.npz"):
save_np_data("esc_melsp_all_test.npz", x_test, y_test)
# save training dataset with white noise
if not os.path.exists("esc_melsp_train_white_noise.npz"):
rates = np.random.randint(1,50,len(x_train))/10000
save_np_data("esc_melsp_train_white_noise.npz", x_train, y_train, aug=add_white_noise, rates=rates)
# save training dataset with sound shift
if not os.path.exists("esc_melsp_train_shift_sound.npz"):
rates = np.random.choice(np.arange(2,6),len(y_train))
save_np_data("esc_melsp_train_shift_sound.npz", x_train, y_train, aug=shift_sound, rates=rates)
# save training dataset with stretch
if not os.path.exists("esc_melsp_train_stretch_sound.npz"):
rates = np.random.choice(np.arange(80,120),len(y_train))/100
save_np_data("esc_melsp_train_stretch_sound.npz", x_train, y_train, aug=stretch_sound, rates=rates)
# save training dataset with combination of white noise and shift or stretch
if not os.path.exists("esc_melsp_train_combination.npz"):
np_data = np.zeros(freq*time*len(x_train)).reshape(len(x_train), freq, time)
np_targets = np.zeros(len(y_train))
for i in range(len(y_train)):
x, fs = load_wave_data(audio_dir, x_train[i])
x = add_white_noise(x=x, rate=np.random.randint(1,50)/1000)
if np.random.choice((True,False)):
x = shift_sound(x=x, rate=np.random.choice(np.arange(2,6)))
else:
x = stretch_sound(x=x, rate=np.random.choice(np.arange(80,120))/100)
x = calculate_melsp(x)
np_data[i] = x
np_targets[i] = y_train[i]
np.savez("esc_melsp_train_combination.npz", x=np_data, y=np_targets)
Audio classification with deep learning
Preparation for deep learning
import keras
from keras.models import Model
from keras.layers import Input, Dense, Dropout, Activation
from keras.layers import Conv2D, GlobalAveragePooling2D
from keras.layers import BatchNormalization, Add
from keras.callbacks import EarlyStopping, ModelCheckpoint,ReduceLROnPlateau
from keras.models import load_model
import warnings
warnings.filterwarnings("ignore")
# dataset files
train_files = ["esc_melsp_all_train_raw.npz"]
test_file = "esc_melsp_all_test.npz"
train_num = len(x_train)
test_num = len(x_test)
print(train_num)
print(test_num)
1600
400
# define dataset placeholders
x_train = np.zeros(freq*time*train_num*len(train_files)).reshape(train_num*len(train_files), freq, time)
y_train = np.zeros(train_num*len(train_files))
# load dataset
for i in range(len(train_files)):
data = np.load(train_files[i])
x_train[i*train_num:(i+1)*train_num] = data["x"]
y_train[i*train_num:(i+1)*train_num] = data["y"]
# load test dataset
test_data = np.load(test_file)
x_test = test_data["x"]
y_test = test_data["y"]
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
(1600, 128, 1723)
(1600,)
(400, 128, 1723)
(400,)
# redefine target data into one hot vector
classes = 50
y_train = keras.utils.to_categorical(y_train, classes)
y_test = keras.utils.to_categorical(y_test, classes)
# reshape training dataset
x_train = x_train.reshape(train_num*1, freq, time, 1)
x_test = x_test.reshape(test_num, freq, time, 1)
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
(1600, 128, 1723, 1)
(1600, 50)
(400, 128, 1723, 1)
(400, 50)
print("x train:{0}\ny train:{1}\nx test:{2}\ny test:{3}".format(x_train.shape,
y_train.shape,
x_test.shape,
y_test.shape))
x train:(1600, 128, 1723, 1)
y train:(1600, 50)
x test:(400, 128, 1723, 1)
y test:(400, 50)
Define convolutional neural network
def cba(inputs, filters, kernel_size, strides):
x = Conv2D(filters, kernel_size=kernel_size, strides=strides, padding='same')(inputs)
x = BatchNormalization()(x)
x = Activation("relu")(x)
return x
# define CNN
inputs = Input(shape=(x_train.shape[1:]))
x_1 = cba(inputs, filters=32, kernel_size=(1,8), strides=(1,2))
x_1 = cba(x_1, filters=32, kernel_size=(8,1), strides=(2,1))
x_1 = cba(x_1, filters=64, kernel_size=(1,8), strides=(1,2))
x_1 = cba(x_1, filters=64, kernel_size=(8,1), strides=(2,1))
x_2 = cba(inputs, filters=32, kernel_size=(1,16), strides=(1,2))
x_2 = cba(x_2, filters=32, kernel_size=(16,1), strides=(2,1))
x_2 = cba(x_2, filters=64, kernel_size=(1,16), strides=(1,2))
x_2 = cba(x_2, filters=64, kernel_size=(16,1), strides=(2,1))
x_3 = cba(inputs, filters=32, kernel_size=(1,32), strides=(1,2))
x_3 = cba(x_3, filters=32, kernel_size=(32,1), strides=(2,1))
x_3 = cba(x_3, filters=64, kernel_size=(1,32), strides=(1,2))
x_3 = cba(x_3, filters=64, kernel_size=(32,1), strides=(2,1))
x_4 = cba(inputs, filters=32, kernel_size=(1,64), strides=(1,2))
x_4 = cba(x_4, filters=32, kernel_size=(64,1), strides=(2,1))
x_4 = cba(x_4, filters=64, kernel_size=(1,64), strides=(1,2))
x_4 = cba(x_4, filters=64, kernel_size=(64,1), strides=(2,1))
x = Add()([x_1, x_2, x_3, x_4])
x = cba(x, filters=128, kernel_size=(1,16), strides=(1,2))
x = cba(x, filters=128, kernel_size=(16,1), strides=(2,1))
x = GlobalAveragePooling2D()(x)
x = Dense(classes)(x)
x = Activation("softmax")(x)
model = Model(inputs, x)
model.summary()
Optimization and callbacks
# initiate Adam optimizer
opt = keras.optimizers.adam(lr=0.0001, decay=1e-6, amsgrad=True)
# Let's train the model using Adam with amsgrad
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
# directory for model checkpoints
model_dir = "./models"
if not os.path.exists(model_dir):
os.mkdir(model_dir)
# early stopping and model checkpoint# early
es_cb = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True,verbose=1, mode='min')
chkpt = os.path.join(model_dir, 'esc50_.{epoch:02d}_{val_loss:.4f}_{val_acc:.4f}.hdf5')
cp_cb = ModelCheckpoint(filepath = chkpt, monitor='val_loss', verbose=1, save_best_only=True, mode='min')
reduce_lr = ReduceLROnPlateau(monitor="val_loss",factor=0.6,patience=3,verbose=1,mode="min")
Train CNN model with between class dataset
# between class data generator
class MixupGenerator():
def __init__(self, x_train, y_train, batch_size=16, alpha=0.2, shuffle=True):
self.x_train = x_train
self.y_train = y_train
self.batch_size = batch_size
self.alpha = alpha
self.shuffle = shuffle
self.sample_num = len(x_train)
def __call__(self):
while True:
indexes = self.__get_exploration_order()
itr_num = int(len(indexes) // (self.batch_size * 2))
for i in range(itr_num):
batch_ids = indexes[i * self.batch_size * 2:(i + 1) * self.batch_size * 2]
x, y = self.__data_generation(batch_ids)
yield x, y
def __get_exploration_order(self):
indexes = np.arange(self.sample_num)
if self.shuffle:
np.random.shuffle(indexes)
return indexes
def __data_generation(self, batch_ids):
_, h, w, c = self.x_train.shape
_, class_num = self.y_train.shape
x1 = self.x_train[batch_ids[:self.batch_size]]
x2 = self.x_train[batch_ids[self.batch_size:]]
y1 = self.y_train[batch_ids[:self.batch_size]]
y2 = self.y_train[batch_ids[self.batch_size:]]
l = np.random.beta(self.alpha, self.alpha, self.batch_size)
x_l = l.reshape(self.batch_size, 1, 1, 1)
y_l = l.reshape(self.batch_size, 1)
x = x1 * x_l + x2 * (1 - x_l)
y = y1 * y_l + y2 * (1 - y_l)
return x, y
# train model
batch_size = 16
epochs = 1000
training_generator = MixupGenerator(x_train, y_train)()
model.fit_generator(generator=training_generator,
steps_per_epoch=x_train.shape[0] // batch_size,
validation_data=(x_test, y_test),
epochs=epochs,
verbose=1,
shuffle=True,
callbacks=[es_cb, cp_cb,reduce_lr])

evaluation = model.evaluate(x_test, y_test)
evaluation = model.evaluate(x_test, y_test)
print(evaluation)
320/320 [==============================] - 48s 151ms/step
[1.4442142248153687, 0.675]
prediction
freq = 128
time = 1723
predict_audio_dir = os.path.join(esc_dir, "audio/test/")
predict_file = os.path.join(esc_dir,"test.csv")
predict_data = pd.read_csv("test.csv",header=None,names=["filename"])
predict_data

predict_data.shape[0]
400
predict = list(predict_data.loc[:,"filename"])
# save wave data in npz, with augmentation
def save_np_data(filename, x, aug=None, rates=None):
np_data = np.zeros(freq*time*len(x)).reshape(len(x), freq, time)
for i in range(len(predict)):
_x, fs = load_wave_data(predict_audio_dir, x[i])
if aug is not None:
_x = aug(x=_x, rate=rates[i])
_x = calculate_melsp(_x)
np_data[i] = _x
np.savez(filename, x=np_data)
# save raw training dataset
if not os.path.exists("esc_melsp_predict_raw.npz"):
save_np_data("esc_melsp_predict_raw.npz", predict)
predict_file = "esc_melsp_predict_raw.npz"
# load test dataset
predict = np.load(predict_file)
x_predict = predict["x"]
x_predict = x_predict.reshape(predict_data.shape[0],freq,time,1)
pred = None
for model_path in ["models/esc50_.14_1.3803_0.7312.hdf5","models/esc50_.18_1.2065_0.7000.hdf5","models/esc50_.20_1.1664_0.7594.hdf5"]:
model = load_model(model_path)
if pred is None:
pred = model.predict(x_predict)
else:
pred += model.predict(x_predict)
print(pred.shape)
res = np.argmax(pred,axis=1)
print(res[:5])
import pandas as pd
df = pd.DataFrame({"img_path":predict_data["filename"], "tags":res})
df.to_csv("submit.csv",index=None,header=None)
小结
下次见!!!



















 1313
1313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











