







XPath Helper是一款免费的Chrome插件,专用于网页解析和爬虫辅助。它允许用户轻松获取网页数据的XPath,以便进行批量爬取。下载插件后,通过拖拽安装到Chrome浏览器,然后在网页上右键检查,复制XPath并输入到XPath Helper查询框,即可高亮显示对应元素。此外,插件还支持批量获取数据、链接和文本等功能,对于前端开发者和爬虫工程师来说非常实用。
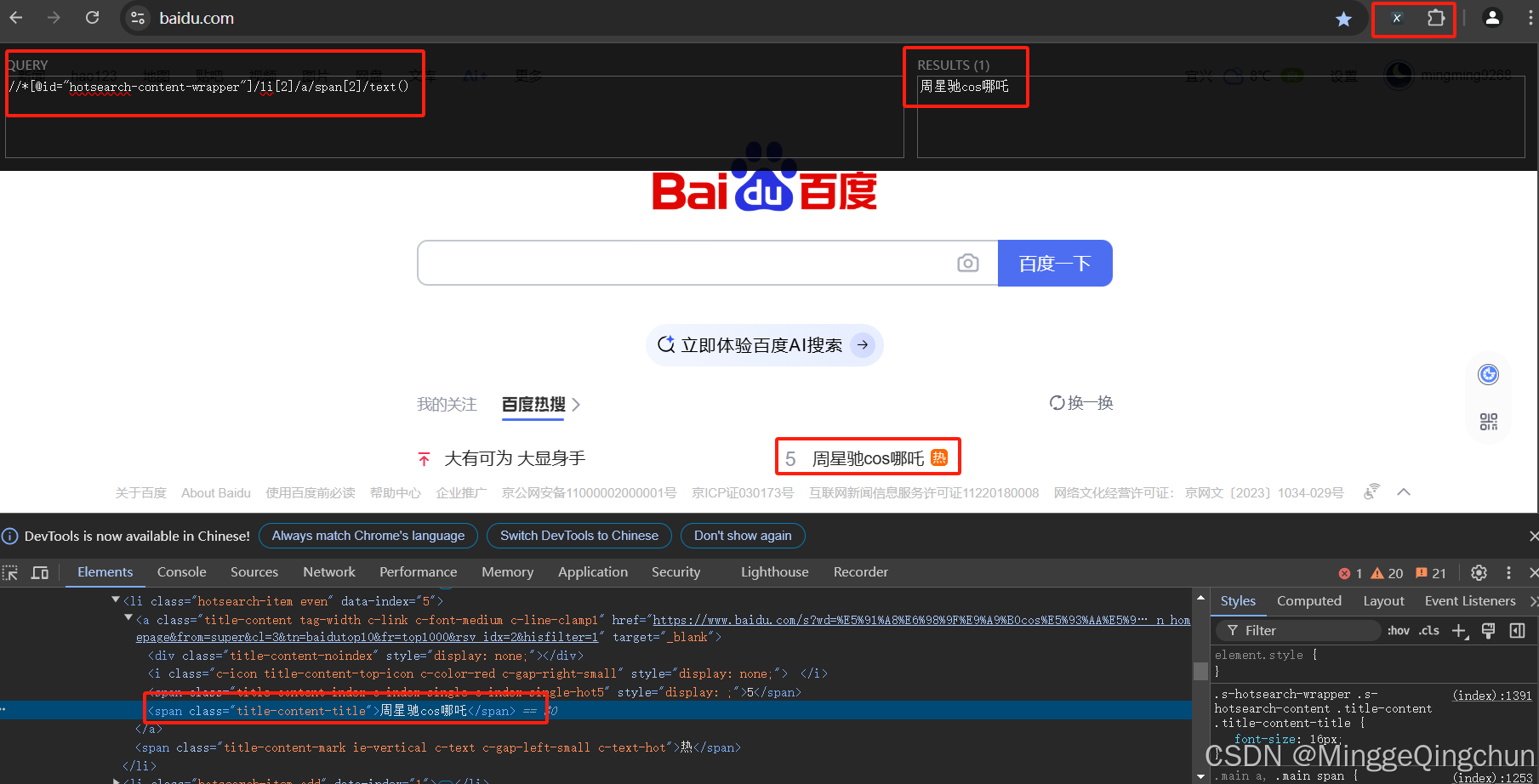
如下图所示,在QUERY输入框中写XPath代码,右侧文本框会显示查找到的xpath结果,在网页中也会高亮度显示xpath所在的位置。
一、下载XPath Helper
XPath Helper下载:XPath Helper_2.0.2_Chrome插件下载_极简插件

1、进入并点击 ‘推荐下载’ 即可下载出压缩包,打开文件下载位置为一个zip文
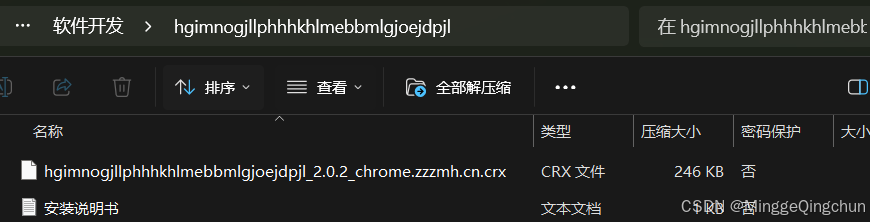
2、将压缩包解压, 有两个文件
二、加载XPath Helper插件至谷歌浏览器
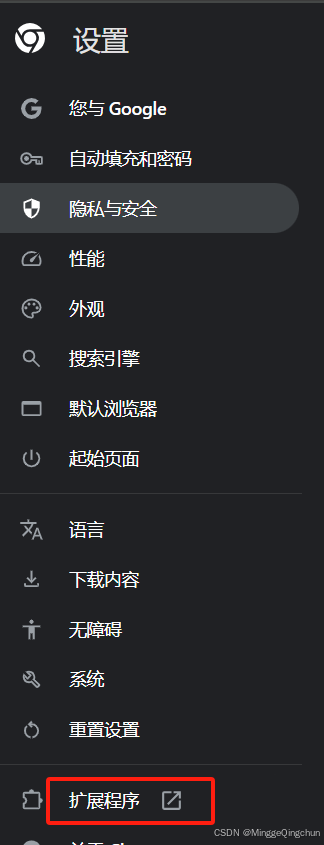
1、使用谷歌浏览器,打开设置(Settings)
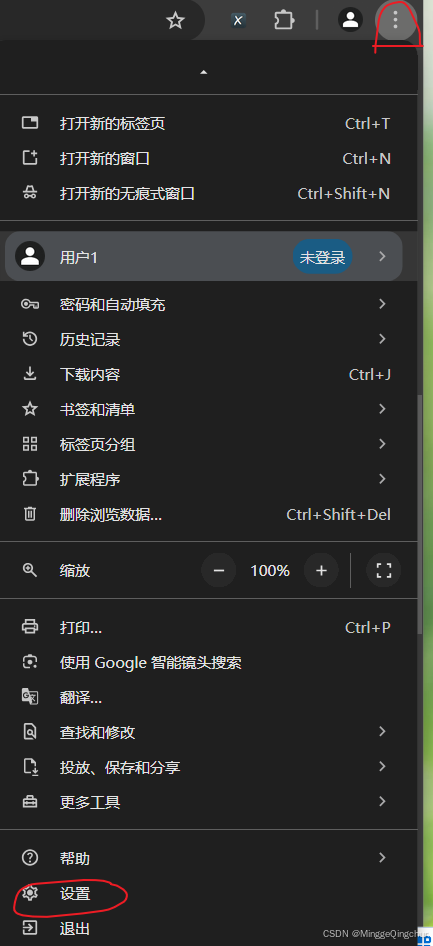
2、点击扩展程序(Extensions)
3、打开 开发者模式(Developer mode)

4、将名为 ’hgimnogjllphhhkhlmebbmlgjoejdpjl_2.0.2_chrome.zzzmh.cn.crx‘ 的文件拖拽复制到chrome浏览器
5、点击弹窗中 ‘Add extension’ (添加扩展) 按钮;到此已将 Xpath Helper 插件已添加至谷歌浏览器
6、将 Xpath Helper 钉( pin ) 在主页上, 便于后期插件的使用
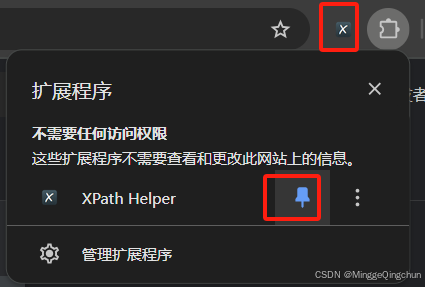
三、Xpath Helper使用
这里以 www.baidu.com 页面热搜为例
1、右键热搜链接,点击检查(inspect)
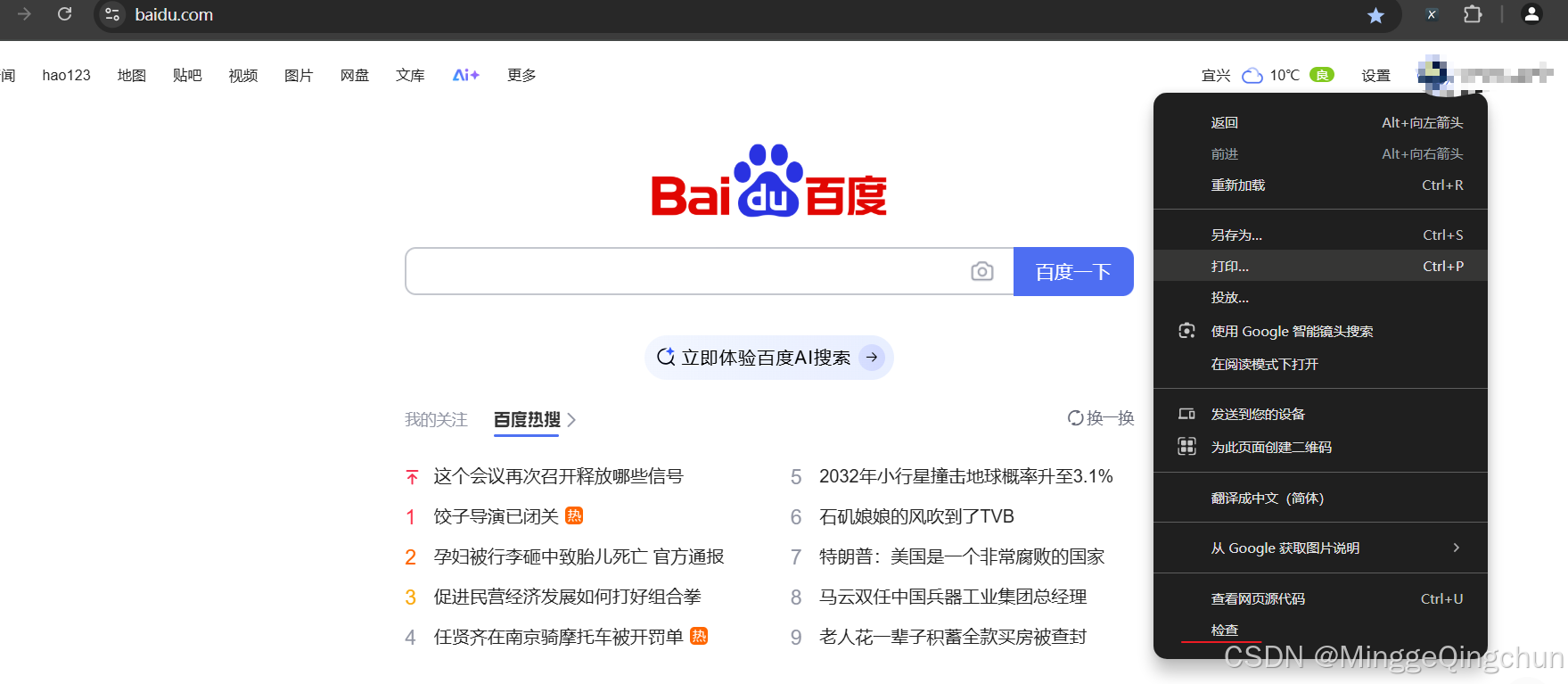
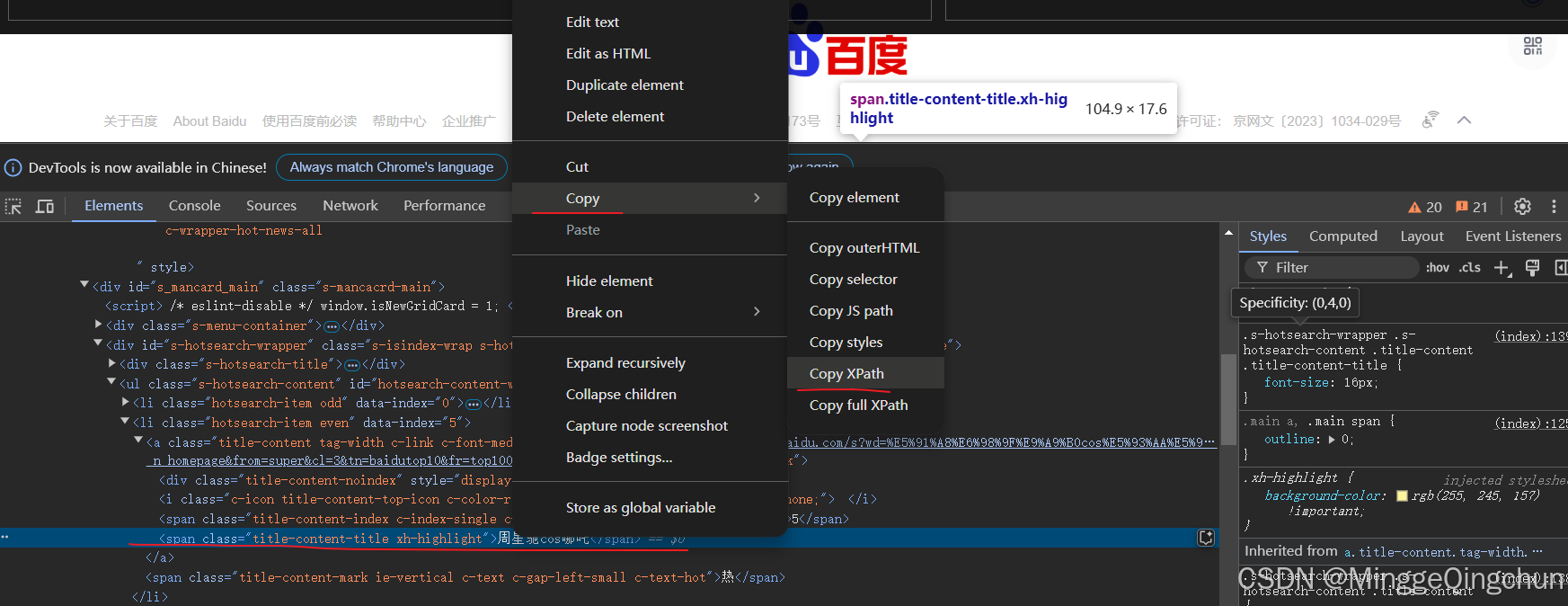
2、在弹出的 开发者工具栏 复制 Xpath (Copy Xpath) , 并点击上方 xpath helper 插件
3、点击插件后, 将刚复制的 xpath 粘贴至查询框
xpath正确,则结果框中显示网页中相应元素,且网页中相应数据高亮显示
//*[@id="hotsearch-content-wrapper"]/li[2]/a/span[2]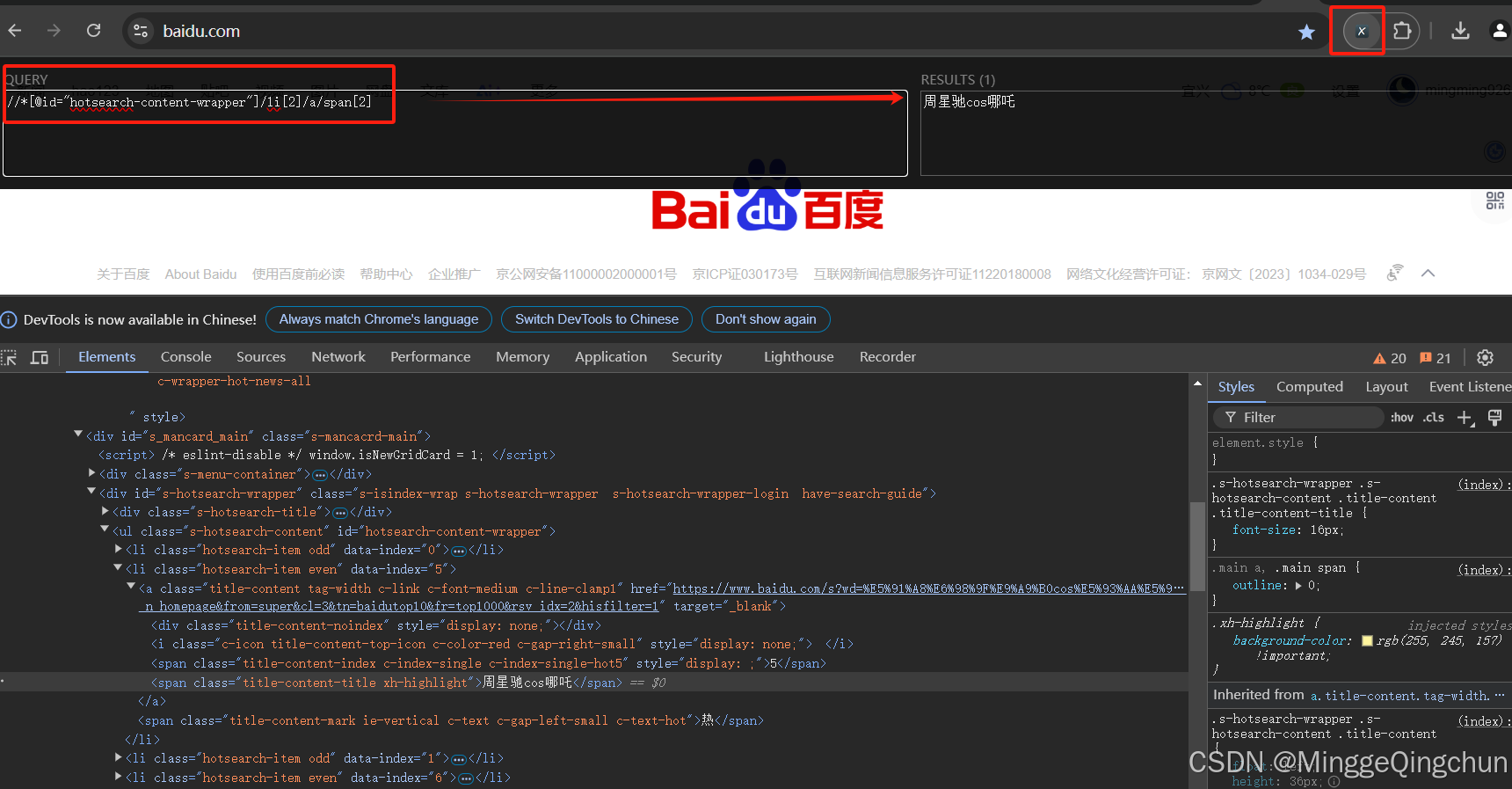
//*[@id="hotsearch-content-wrapper"]/li[2]/a/span[2]/text()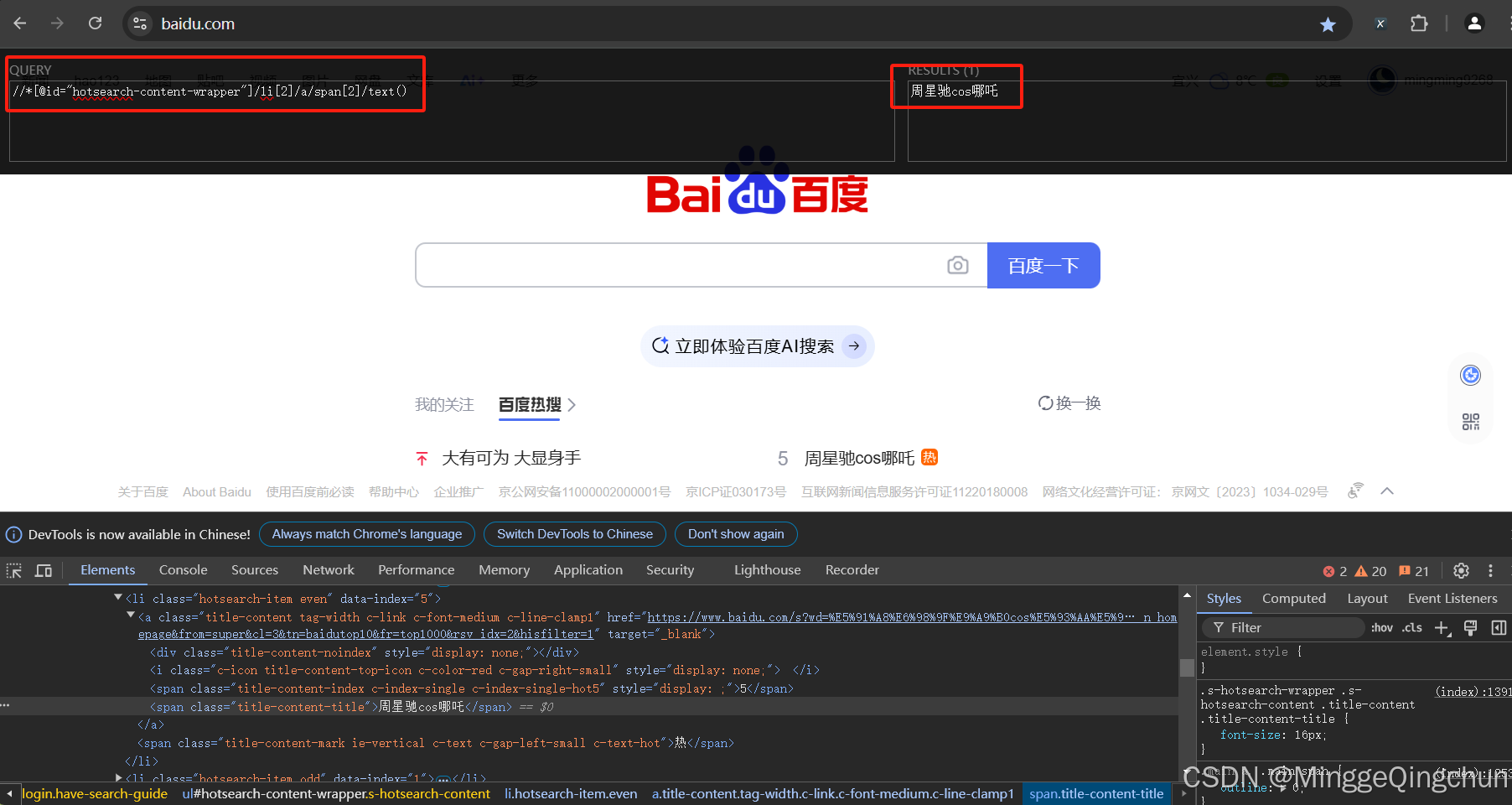
4、批量获取数据
//*[@id="hotsearch-content-wrapper"]/li/a/span[2] 5、获取链接
5、获取链接
//*[@id="hotsearch-content-wrapper"]/li/a/@href
6、获取文本
//*[@id="hotsearch-content-wrapper"]/li/a/span[2]/text()

















 622
622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









