









论文:Communication-Efficient Learning of Deep Networks
from Decentralized Data
原code
Reproducing
通过阅读帖子进行的了解。
联邦平均算法就是最典型的平均算法之一。将每个客户端上的本地随机梯度下降和执行模型的平均服务器结合在一起。
联邦优化问题
-
数据非独立同分布
-
数据分布的不平衡性
-
用户规模大
-
通信有限
联邦平均算法
客户端与服务器之间的通信代价比较大,文中提出两种方法降低通信成本:
-
增加并行性
-
增加每个客户端计算量
首先提出FedSGD算法,本地执行多次FedSGD,得到FedAvg算法。
-
选择一定比例客户端参与训练,而不是全部,因为全部的会比客户端的收敛速度慢,模型精度低
-
该算法将计算量放在了本地客户端,服务器只用于聚合平均,可在平均步骤之前进行多次局部模型的更新,过多的本地迭代轮次会造成过拟合
代码复现
IID、Non-IID的含义:
-
数据独立同分布,IID,Independent Identically Distribution,数据之间不相互影响,满足同一个分布。
独立同分布数据,说明训练的样本点具有较好的总体代表性。
-
非独立同分布,Non-IID,Non-Independent Identically Distribution,实际场景数据很难满足IID的前提假设。
依照帖子对代码文件的介绍,如下图所示:
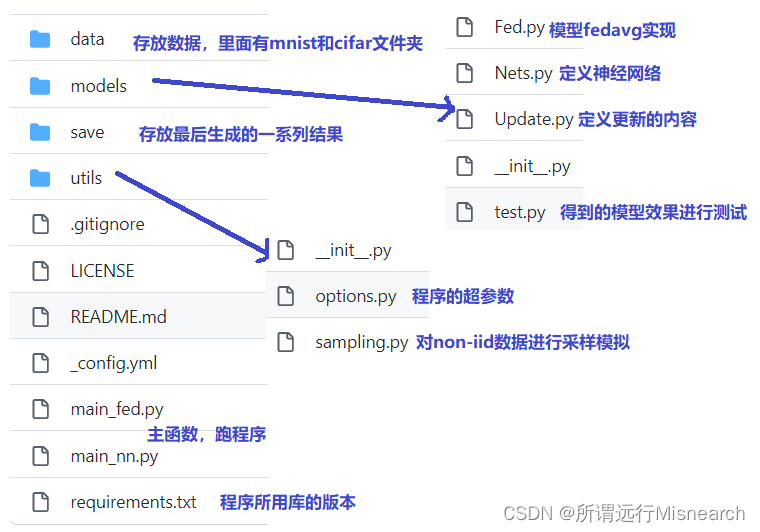
我的本地电脑:如下图所示:
main_fed.py
"""
FileName:
Author:
Version:
Date: 2024/6/1017:27
Description:
"""
# 导入工具包
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import copy
import numpy as np
from torchvision import datasets, transforms
import torch
from utils.sampling import mnist_iid, mnist_noniid, cifar_iid
from utils.options import args_parser
from models.Update import LocalUpdate
from models.Nets import MLP, CNNMnist, CNNCifar
from models.Fed import FedAvg
from models.test import test_img
# main函数
if __name__ == '__main__':
# parse args
args = args_parser()
args.device = torch.device('cuda:{}'.format(args.gpu) if torch.cuda.is_available() and args.gpu != -1 else 'cpu')
# load dataset and split users
if args.dataset == 'mnist':
# mnist数据集,将图片转为tentor,并进行归一化处理
trans_mnist = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
# 调用datasets库,下载训练、测试数据集
dataset_train = datasets.MNIST('../data/mnist/', train=True, download=True, transform=trans_mnist)
dataset_test = datasets.MNIST('../data/mnist/', train=False, download=True, transform=trans_mnist)
# sample users
if args.iid: # iid
dict_users = mnist_iid(dataset_train, args.num_users)
else: # non-iid
dict_users = mnist_noniid(dataset_train, args.num_users)
elif args.dataset == 'cifar':
trans_cifar = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])
#
dataset_train = datasets.CIFAR10('../data/cifar', train=True, download=True, transform=trans_cifar)
dataset_test = datasets.CIFAR10('../data/cifar', train=False, download=True, transform=trans_cifar)
if args.iid:
dict_users = cifar_iid(dataset_train, args.num_users)
else:
exit('Error: only consider IID setting in CIFAR10')
else:
exit('Error: unrecognized dataset')
img_size = dataset_train[0][0].shape
# build model
# net_glob全局模型?
if args.model == 'cnn' and args.dataset == 'cifar':
net_glob = CNNCifar(args=args).to(args.device)
elif args.model == 'cnn' and args.dataset == 'mnist':
net_glob = CNNMnist(args=args).to(args.device)
elif args.model == 'mlp':
len_in = 1
for x in img_size:
len_in *= x
net_glob = MLP(dim_in=len_in, dim_hidden=200, dim_out=args.num_classes).to(args.device)
else:
exit('Error: unrecognized model')
print(net_glob) # 打印具体网络结构
net_glob.train()
# copy weights 复制权重
w_glob = net_glob.state_dict()
# training,fedavg核心代码
loss_train = []
cv_loss, cv_acc = [], []
val_loss_pre, counter = 0, 0 # 预测损失,计数器
net_best = None
best_loss = None
val_acc_list, net_list = [], []
if args.all_clients:
print("Aggregation over all clients")
# 给参与训练的局部下发全局初始模型
w_locals = [w_glob for i in range(args.num_users)]
for iter in range(args.epochs): # 局部迭代轮次
loss_locals = [] # 局部预测损失
if not args.all_clients:
w_locals = []
m = max(int(args.frac * args.num_users), 1) # 每轮被选参与联邦学习的用户比例frac
# sample client
idxs_users = np.random.choice(range(args.num_users), m, replace=False)
for idx in idxs_users:
# 局部模型的训练
# 依据用户id,获取划分得到的用户id数据集部分,进行局部训练
local = LocalUpdate(args=args, dataset=dataset_train, idxs=dict_users[idx])
w, loss = local.train(net=copy.deepcopy(net_glob).to(args.device))
if args.all_clients:
w_locals[idx] = copy.deepcopy(w)
else:
w_locals.append(copy.deepcopy(w)) # w_locals汇总本地权重
loss_locals.append(copy.deepcopy(loss)) # 局部损失以列表形式往后添加
# 全局更新update global weights
w_glob = FedAvg(w_locals)
# copy weight to net_glob
net_glob.load_state_dict(w_glob) # 复制权重,以便下次
# print loss
loss_avg = sum(loss_locals) / len(loss_locals)
# plot loss curve
plt.figure()
plt.plot(range(len(loss_train)), loss_train)
plt.ylabel('train_loss')
# plt.show()
# testing
net_glob.eval() #eavl()函数 关闭batch normalization与dropout 处理
acc_train, loss_train = test_img(net_glob, dataset_train, args)
acc_test, loss_test = test_img(net_glob, dataset_test, args)
print("Training accuracy: {:.2f}".format(acc_train))
print("Testing accuracy: {:.2f}".format(acc_test))
Fed.py
关键原理:Fed.py中的权重平均聚合算法,
def FedAvg(w):
'''
:param w: 权重吗?是的,是包含多个用户端模型权重的列表,每个权重相当于一个字典,带有键值
:return:
'''
w_avg = copy.deepcopy(w[0]) # 利用深拷贝获取初始w[0]
for k in w_avg.keys(): # 遍历每个权重键
for i in range(1, len(w)):
w_avg[k] += w[i][k] # 累加
w_avg[k] = torch.div(w_avg[k], len(w)) # 平均
return w_avg
Update.py
"""
FileName:
Author:
Version:
Date: 2024/6/1021:11
Description:
"""
import torch
from torch import nn, autograd
from torch.utils.data import DataLoader, Dataset
import numpy as np
import random
from sklearn import metrics
class DatasetSplit(Dataset):
def __init__(self, dataset, idxs):
self.dataset = dataset
self.idxs = list(idxs)
def __len__(self):
return len(self.idxs)
def __getitem__(self, item):
image, label = self.dataset[self.idxs[item]]
return image, label
class LocalUpdate(object):
def __init__(self, args, dataset=None, idxs=None):
self.args = args
self.loss_func = nn.CrossEntropyLoss()
self.selected_clients = []
self.ldr_train = DataLoader(DatasetSplit(dataset, idxs), batch_size=self.args.local_bs, shuffle=True)
def train(self, net):
net.train()
# train and update
optimizer = torch.optim.SGD(net.parameters(), lr=self.args.lr, momentum=self.args.momentum)
epoch_loss = []
for iter in range(self.args.local_ep):
batch_loss = []
for batch_idx, (images, labels) in enumerate(self.ldr_train):
images, labels = images.to(self.args.device), labels.to(self.args.device)
net.zero_grad()
log_probs = net(images)
loss = self.loss_func(log_probs, labels)
loss.backward()
optimizer.step()
if self.args.verbose and batch_idx % 10 == 0:
print('Update Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
iter, batch_idx * len(images), len(self.ldr_train.dataset),
100. * batch_idx / len(self.ldr_train), loss.item()))
batch_loss.append(loss.item())
epoch_loss.append(sum(batch_loss)/len(batch_loss))
return net.state_dict(), sum(epoch_loss) / len(epoch_loss)















 570
570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









