









基于PARL教程的笔记
目录
基于策略梯度求解RL
策略近似、策略梯度
之前使用函数拟合价值,这次尝试直接使用函数拟合策略
对于DQN来说,使用函数拟合的是它的Q表,即它的状态价值函数
而在PG中,直接使用神经网络拟合策略,即输入状态,直接输出动作的方法
Value-Based & Policy-Based
基于价值的方法是确定性策略,通过给出一个确定性的状态-动作价值,选择相应的动作
- Value-Based先学习动作价值函数,将动作价值函数优化到最优,再根据动作价值函数选择动作。
- Policy-Based直接输出动作概率,动作选择不再依赖于价值函数,而是根据一个策略走到底。最后根据总收益决定动作是好还是坏。

图1.基于价值的方法
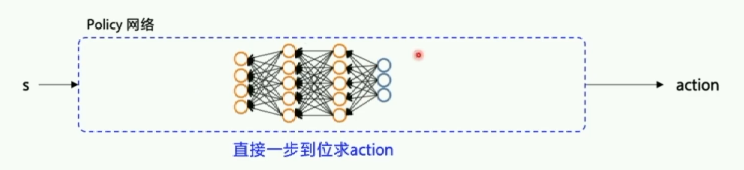
图2.基于策略的方法
policy-based可以得到一个随机性的策略,例如剪刀石头布游戏,确定性策略可能会一直出剪刀,而策略梯度最后可能会得到三个动作一样的概率
softmax函数
神经网络的输出长度为
n
n
n,第
i
i
i个的概率值为:
y
i
=
e
z
i
/
Σ
i
=
1
n
e
z
i
y_i = e^{z_i} / \Sigma_{i=1}^ne^{z_i}
yi=ezi/Σi=1nezi
softmax函数可以将多个神经元的输出,映射到(0,1)的区间内,可以看成概率来理解,可以输出不同动作的概率。

例如,在乒乓球游戏中:

幕 Episode(一回合游戏)
量化的优化目标:让每个episode的总reward尽可能大
R
=
∑
t
=
1
T
r
t
R = \sum_{t=1}^Tr_t
R=t=1∑Trt
轨迹 Trajectory
策略:智能体使用策略
π
\pi
π在状态
s
s
s下选择动作
a
a
a的概率是:
π
θ
(
a
∣
s
)
\pi_\theta(a|s)
πθ(a∣s)
状态转移概率:而环境在
(
s
,
a
)
(s,a)
(s,a)的状态下转移到状态
s
′
s'
s′的概率是:
p
(
s
′
∣
s
,
a
)
p(s'|s,a)
p(s′∣s,a)
我们需要优化的就是智能体的策略。
一个回合的轨迹就是一个回合中所有状态和动作的序列:
τ
=
{
s
1
,
a
1
,
s
2
,
a
2
,
.
.
.
s
T
,
a
T
}
\tau=\{s_1,a_1,s_2,a_2,...s_T,a_T\}
τ={s1,a1,s2,a2,...sT,aT}

那么,这条轨迹发生的概率是:
p
θ
(
τ
)
=
p
(
s
1
)
π
θ
(
a
1
∣
s
1
)
p
(
s
2
∣
s
1
,
a
1
)
π
θ
(
a
2
∣
s
2
)
p
(
s
3
∣
s
2
,
a
2
)
.
.
.
p_{\theta}(\tau) = p(s_1)\pi_\theta(a_1|s_1)p(s_2|s_1,a_1)\pi_\theta(a_2|s_2)p(s_3|s_2,a_2)...
pθ(τ)=p(s1)πθ(a1∣s1)p(s2∣s1,a1)πθ(a2∣s2)p(s3∣s2,a2)...
在轨迹
τ
\tau
τ下的总回报为:
R
(
τ
)
=
∑
t
=
1
T
r
t
R(\tau) = \sum_{t=1}^Tr_t
R(τ)=t=1∑Trt
在策略
π
\pi
π下有很多条轨迹,策略
π
θ
(
a
∣
s
)
\pi_\theta(a|s)
πθ(a∣s)的期望回报就是所有episode的平均回报:
R
θ
‾
=
∑
τ
R
(
τ
)
p
θ
(
τ
)
\overline{R_\theta} = \sum_\tau R(\tau)p_\theta(\tau)
Rθ=τ∑R(τ)pθ(τ)
我们无法得知状态转移概率,也无法穷举每一种可能的轨迹,所以,我们近似地求平均回报:
R
θ
‾
=
∑
τ
R
(
τ
)
p
θ
(
τ
)
≈
1
N
∑
n
=
1
N
R
(
τ
)
\overline{R_\theta} = \sum_\tau R(\tau)p_\theta(\tau)\approx\frac1N\sum_{n=1}^NR(\tau)
Rθ=τ∑R(τ)pθ(τ)≈N1n=1∑NR(τ)
采样N个episode来计算期望回报。
通过计算策略的期望回报,我们就能够看出当前使用的策略的好坏
优化策略函数 π θ ( s , a ) \pi_\theta(s, a) πθ(s,a)
DQN更新Q网络:
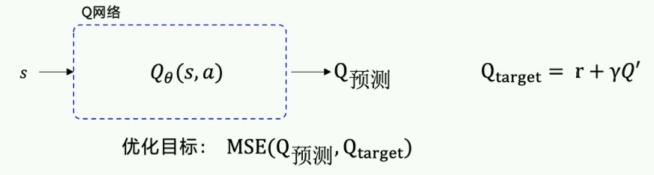
在DQN中,拥有一个 Q t a r g e t Q_{target} Qtarget能够对当前值进行指导,但是对于Policy的输出,没有相应的label指导。
所以使用期望奖励来优化函数,将策略网络朝着期望奖励增加的方向优化。
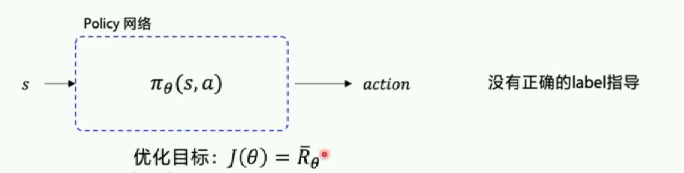
优化目标:
J
(
θ
)
=
R
‾
θ
J(\theta)=\overline{R}_\theta
J(θ)=Rθ
希望优化目标越大越好,梯度上升
神经网络需要梯度来决定其参数更新的方向,需要求解 R ‾ θ \overline{R}_\theta Rθ对 θ \theta θ的梯度
策略梯度
所以,我们需要得到N条轨迹,每一条轨迹都有其对应的奖励
R
(
τ
)
R(\tau)
R(τ),那么,
R
‾
θ
\overline{R}_\theta
Rθ对
θ
\theta
θ的梯度为:
∇
R
‾
θ
≈
1
N
∑
n
=
1
N
∑
t
=
1
T
n
R
(
τ
n
)
∇
log
π
θ
(
a
t
n
∣
s
t
n
)
\nabla\overline{R}_\theta\approx\frac1N\sum_{n=1}^N\sum_{t=1}^{T_n}R(\tau^n)\nabla\log\pi_\theta(a_t^n|s_t^n)
∇Rθ≈N1n=1∑Nt=1∑TnR(τn)∇logπθ(atn∣stn)
反推得到损失函数:
L
o
s
s
=
−
R
(
τ
)
log
π
θ
(
a
t
∣
s
t
)
Loss=-R(\tau)\log\pi_\theta(a_t|s_t)
Loss=−R(τ)logπθ(at∣st)
我们可以将损失函数送到优化器中,优化器会减小Loss。由于我们是想要扩大 R ‾ θ \overline{R}_\theta Rθ的,所以在Loss函数的前面有一个负号,以达到增加期望奖励的目的。
对
θ
\theta
θ的更新是这样的:
θ
⟵
θ
+
α
∇
R
‾
θ
\theta\longleftarrow\theta+\alpha\nabla\overline{R}_\theta
θ⟵θ+α∇Rθ
蒙特卡洛 MC 和时序差分 TD
蒙特卡洛(回合更新)
在每一个回合结束的时候,使用整个回合的数据进行学习learn(),我们可以很方便的计算某个状态的期望回报 G t G_t Gt
它的策略梯度是:
∇
R
‾
θ
≈
1
N
∑
n
=
1
N
∑
t
=
1
T
n
G
t
n
∇
log
π
θ
(
a
t
n
∣
s
t
n
)
\nabla\overline{R}_\theta\approx\frac1N\sum_{n=1}^N\sum_{t=1}^{T_n}G_t^n\nabla\log\pi_\theta(a_t^n|s_t^n)
∇Rθ≈N1n=1∑Nt=1∑TnGtn∇logπθ(atn∣stn)
时序差分(单步更新)
在每一步交互之后都进行学习,每个step()都会更新策略网络。此时,我们无法准确的得到每一步的期望回报 G t G_t Gt,所以使用 Q n ( s t n , a t n ) Q^n(s_t^n,a_t^n) Qn(stn,atn)来代替。
它的策略梯度是:
∇
R
‾
θ
≈
1
N
∑
n
=
1
N
∑
t
=
1
T
n
Q
n
(
s
t
n
,
a
t
n
)
∇
log
π
θ
(
a
t
n
∣
s
t
n
)
\nabla\overline{R}_\theta\approx\frac1N\sum_{n=1}^N\sum_{t=1}^{T_n}Q^n(s_t^n,a_t^n)\nabla\log\pi_\theta(a_t^n|s_t^n)
∇Rθ≈N1n=1∑Nt=1∑TnQn(stn,atn)∇logπθ(atn∣stn)
时序差分有一个经典算法:表演家-评论家(Actor-Critic),但是这里不作描述。
只讲蒙特卡洛最简单的REINFORCE算法。
蒙特卡洛 REINFORCE
在策略梯度公式中,我们需要计算期望回报 G t n G_t^n Gtn,在第n个轨迹中的时刻t。
G
t
G_t
Gt代表时刻t之后奖励和衰减因子乘积之和:
G
t
=
∑
t
=
k
+
1
T
γ
k
−
t
−
1
r
t
=
r
t
+
γ
G
t
+
1
G_t=\sum_{t=k+1}^T\gamma^{k-t-1}r_t\\ =r_t+\gamma G_{t+1}
Gt=t=k+1∑Tγk−t−1rt=rt+γGt+1
输入一次轨迹中每个回合的奖励,计算得到期望回报的代码:
def calc_reward_to_go(reward_list, gamma=1.0):
for i in range(len(reward_list)-2, -1, -1):
# G_t = r_t + gamma*r_(t+1)+... = r_t + gamma * G_(t+1)
reward_list[i] += gamma * reward_list[i+1]
return np.array(reward_list)
在代码中,从后向前计算。
PolicyGradient算法的代码逻辑如下图:

图中圈住的地方代表action对应的概率的对数。
然后,对每一个动作求出损失函数:
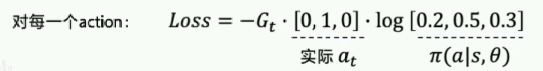
图片中实际 a t a_t at对应的[0,1,0]指的是:
- 有三个可选的动作(gym.Discrete(3))
- 选择动作1的概率为1,另外两个动作的概率为0(onehot编码)
交叉熵(Cross Entropy),计算两个概率分布之间的差值。
在监督学习中,需要计算神经网络输出( Y i Y_i Yi)和真实label( Y i ′ Y'_i Yi′)之间的差值,这时候就使用交叉熵。
− ∑ Y i ′ ⋅ log ( Y i ) -\sum Y'_i\cdot\log(Y_i) −∑Yi′⋅log(Yi)
类似地,在Policy Gradient中,有:
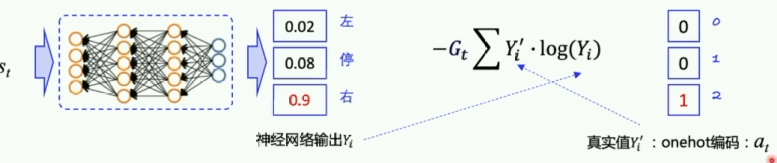
在公式中,我们计算相应的交叉熵送入损失函数之前,需要乘以一个 G t G_t Gt,因为在此时我们所选择的动作不一定是正确的,可以使用 G t G_t Gt作为权重,期望回报越高,权重越大。
所以,Policy Gradient的损失函数Loss指的是带有权重的交叉熵。
交叉熵是实际选择的动作和神经网络预测的动作概率的交叉熵。
在实现损失函数后,我们可以将损失函数喂给优化器,对神经网络进行优化。
def learn(self, obs, action, reward):
'''update the policy model self.model with policy gradient algorithm'''
act_prob = self.model(obs) # 神经网络输出的概率
# log_prob = layers.cross_entropy(act_prob, action)
# action = layers.one_hot(action, act_prob.shape[1])
log_prob = layers.reduce_sum(-1.0 * layers.log(act_prob) * layers.one_hot(action, act_prob.shape[1]), dim=1)
cost = log_prob * reward
cost = layers.reduce_mean(cost)
optimizer = fluid.optimizer.Adam(self.lr)
optimizer.minimize(cost)
return cost
REINFORCE流程图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4NjrMzmS-1620477624961)(/REINFORCE流程图.png)]
代码
model.py
import parl
from parl import layers
class Model(parl.Model):
def __init__(self, act_dim):
act_dim = act_dim
hid1_size = act_dim * 10
self.fc1 = layers.fc(size=hid1_size, act='tanh')
self.fc2 = layers.fc(size=act_dim, act='softmax')
def forward(self, obs):
out = self.fc1(obs)
out = self.fc2(out)
return out
algorithm.py
class PolicyGradient(parl.Algorithm):
def __init__(self, model, lr=None):
""" Policy Gradient algorithm
Args:
model (parl.Model):policy的前向网络
lr(float):学习率
"""
self.model = model
assert isinstance(lr, float)
self.lr = lr
def predict(self, obs):
return self.model.forward(obs)
def learn(self, obs, action, reward):
act_prob = self.model(obs)
# log_prob = layers.cross_entropy(act_prob, action)
log_prob = layers.reduce_sum(-1.0 * layers.log(act_prob)
* layers.one_hot(action, act_prob.shape[1]), dim=1)
cost = log_prob * reward
cost = layers.reduce_mean(cost)
optimizer = fluid.optimizer.Adam(self.lr)
optimizer.minimize(cost)
return cost
agent.py
class Agent(parl.Agent):
def __init__(self, algorithm, obs_dim, act_dim):
self.obs_dim = obs_dim
self.act_dim = act_dim
super(Agent, self).__init__(algorithm)
def build_program(self):
self.pred_program = fluid.Program()
self.learn_program = fluid.Program()
with fluid.program_guard(self.pred_program):
obs = layers.data(name='obs', shape=[self.obs_dim], dtype='float32')
self.act_prob = self.alg.predict(obs)
with fluid.program_guard(self.learn_program):
obs = layers.data(name='obs', shape=[self.obs_dim], dtype='float32')
act = layers.data(name='act', shape=[1], dtype='int64')
reward = layers.data(name='reward', shape=[], dtype='float32')
self.cost = self.alg.learn(obs, action, reward)
def learn(self, obs, act, reward):
act = np.expand_dims(act, axis=-1)
feed = {
'obs': obs.actype('float32'),
'act': act.astype('int64'),
'reward': reward.astype('float32')
}
cost = self.fluid_executor.run(
self.learn_program, feed=feed, fetch_list=[self.cost])[0]
return cost
def sample(self, obs):
obs = np.expand_dims(obs, axis=0)# 增加一维维度
act_prob = self.fluid_executor.run(self.pred_program,
feed={'obs': obs.astype('float32')},
fetch_list=[self.act_prob])[0]
act_prob = np.squeeze(act_prob, axis=0) # 减少一维维度
act = np.random.choice(range(self.act_dim), p=act_prob) # 根据动作概率选取动作
return act
def predict(self, obs):
obs = np.expand_dims(obs, axis=0)
act_prob = self.fluid_executor.run(self.pred_program,
feed={'obs': obs.astype('float32')},
fetch_list=[self.act_prob])[0]
act_prob = np.squeeze(act_prob, axis=0)
act = np.argmax(act_prob) # 根据动作概率选择概率最高的动作
return act
train.py
def main():
env = gym.make('CartPole-v0')
obs_dim = env.observation_space.shape[0]
act_dim = env.action_space.n
logger.info('obs_dim {}, act_dim {}'.format(obs_dim, act_dim))
model = Model(act_dim=act_dim)
alg = PolicyGradient(model, lr=LEARNING_RATE)
agent = Agent(alg, obs_dim=obs_dim, act_dim=act_dim)
for i in range(1000):
obs_list, action_list, reward_list = run_episode(env, agent)
if i % 10 == 0:
logger.info('Episode {}, Reward Sum {}.'.format(i, sum(reward_list)))
batch_obs = np.array(obs_list)
batch_action = np.array(action_list)
batch_reward = calc_reward_to_go(reward_list)
agent.learn(batch_obs, batch_action, batch_reward)
if (i + 1) % 100 == 0:
total_reward = evaluate(env, agent, render=True)
logger.info('Test reward: {}'.format(total_reward))















 717
717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









