







 本文深入探讨了K-means算法在虹膜识别中的作用,详细阐述了K-means算法的定义、过程,以及关键点如K值选择、初始化中心和距离度量。介绍了K值选择的肘部法则,并讨论了算法的优缺点,强调了其对噪声和异常点的敏感性。
本文深入探讨了K-means算法在虹膜识别中的作用,详细阐述了K-means算法的定义、过程,以及关键点如K值选择、初始化中心和距离度量。介绍了K值选择的肘部法则,并讨论了算法的优缺点,强调了其对噪声和异常点的敏感性。
本博客是对虹膜识别中需要用到的K-means算法的学习。
一、聚类
聚类本身是无监督问题,实际上就是把已有的一部分数据,按照其相似度分为不同的簇,将相似度高的分为一簇,而相异度高的分为不同簇。
二、K-means算法的定义
Kmeans聚类算法算得上是最著名的聚类方法。K-means算法实际上是一个重复移动簇中心点的过程,把簇的中心点,移动到其包含成员的平均位置,然后重新划分其内部成员,多次重复此步骤,即可完成聚类。
关于k:
1)k表示簇的数量;
2)k-means可以自动分配样本到不同的簇,但是不能决定究竟要分几个簇;
3)k必须是一个比训练集样本数小的正整数;
4)有时,k的值是由问题内容指定的。例如,一个鞋厂有三种新款式,它想知道每种新款式都有哪些潜在客户,于是它调研客户,然后从数据里找出三类,k为3。也有一些问题没有指定聚类的数量,最优的聚类数量是不确定的。【1】
三、K-means的过程
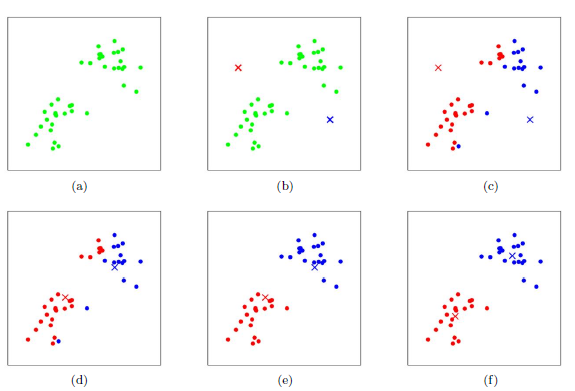
这个图其实可以很好的表示K-means的过程【2】。
1)确定K值,这里是两类,及红色和蓝色两类,两个X号分别为两类的初始化中心点,记为C1,C2;
2)根据C1和C2所在位置,计算各个数据与C1、C2的距离,将所有数据分为蓝红两类,如图C;
3)在分完类后,在根据现在两个类的分布,分别计算现在两个类的中心点C1'和C2';
4)接着重复第二步,计算各个数据与与C1、C2的距离,将所有数据分为新的蓝红两类;
5)再重复第三步,再计算新的两个类的中心点C1''和C2'';
6)接着继续重复……
7)最终我们得到最终的结果,如图f,结束的条件是新的中心的位置和原来中心的位置的距
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7141
7141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









