








我们前面讲的所有东西都没有把 数据的noise 考虑进去。即都是假设x是服从未知的
P(X)
分布(分布不用知道),用最标准的目标函数f(f不用知道的),得到其对应的y,然后从中抽取N个数据训练模型(其他的我们数据也不知道)。
可是如果数据有noise的话,我们并不能确定我们手里的y就是正确的(即是f给的)。那我们该怎么处理呢??方法就是认为y是一个目标分布,
即原来是
现在是

我们可以认为真正的y=‘ideal mini-target’+noise
比如
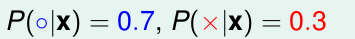
我们就认为这个x的“ideal mini-target”y=0.7.他的noise 为 0.3.
误差评估
如果是分类的话,用0/1 error(有很多,这里先只说一种)

如果是回归的话,可以用平方误差(有很多,这里先只说一种)

比如
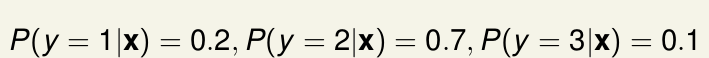
如果用 0/1 error 做

总结得到,用0/1 error 选出来的f(x),为
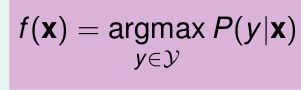
如果用 平方error来做

总结得到,用平方 error 选出来的f(x),为
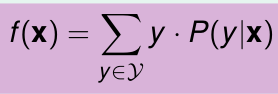
所以,当我们的评比方式不同的时候,得到的结果也是不同的。所以选择时,要慎重。
错误代价框图
看下图

里面填的值为对应所引起的代价值!!!
比如,当f=1且g=1,没有错误,代价为0
f=-1且g=-1,没有错误,代价为0
f=-1且g=+1,发生错误,代价为 false accept
f=+1且g=-1,发生错误,代价为 false reject
其实,有的时候false accept和false reject的值是不一样的。比如,这是一个用指纹识别来是否允许开启电脑的系统,对于机密机构,他肯定是,宁可让本可以用的人不能用,也不想不能用的人可以使用。即宁可false accept高于false reject。那么假设false accept的代价值为1000,false reject的代价值为1.
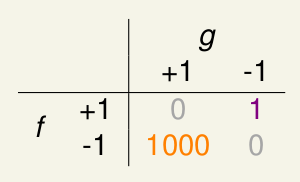
那么如果我们用分类器来训练模型的话,使用的
Ein
应该为
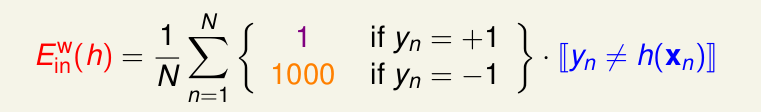
这里我们用
Ewin
表示,表示是加权的分类器。
我们用先前提到的 packet algorithm来做。

这个好像不好做,那么我们能否把表达式
Ewin
转化为
Ein
呢??
方法很简单
我们的问题是

下面的D表示数据。
由于y=-1且h=1的代价为1000,那么我们能否把每个y=-1的数据拷贝1000份。转化为下面的情况

这样,y=-1且h=1的代价就可以扩大1000倍,而y=-1且h=-1由于本就是所以没有影响。
那么现在我们就可以用原来的packet algorithm了。
可是这样做的话,把数据增加这么多,而且还是一样的,同时伴随着数据拷贝,读写的操作,那模型的运算量会不会很大???
解决的方法就是,我不把y=-1数据拷贝1000份,
由于packet algorithm是随机抽取数据,那么,我们就使y=-1的被选中 的 概率 扩大1000倍即可。
















 362
362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









