







算法设计与分析
编辑时间:2023/10/11
程序设计=算法+数据结构
算法设计思想
1.问题建模
2.选择什么算法
3.求最优解并且证明正确性
4.分析算法效率性
排序算法
1.算法
算法 最坏情况 平均情况
插入排序 n的平方 n的平方
冒泡排序 n的平方 n的平方
快速排序 n的平方 nlogn
堆排序 nlogn nlogn
二分归并排序 nlogn nlogn
2.插入排序:
3.冒牌排序:n-1和n巡回交换
4.快速排序:
5.二分归并:
货郎问题和计算复杂性理论
问题分析:
建模与算法:
2.01背包问题:
3.双机调度:
问题以及实例
1.问题:需要回答一般性体温,通常含有若干参数
2.问题描述:
定义问题参数(集合,变量,函数,序列等)
说明问题的每个参数的取值范围以及参数间的3.关系
定义问题的解
说明满足的条件(优化目标和约束条件)
算法
1.算法:有限指令的序列
这个指令序列确定了解决某个问题的一系列运算或操作
2.算法A解决问题P:把问题P的任何实例作为算法A的输入
每步计算是确定性的
A能够在有限步停机
输出该实例的正确的解
基本运算和输入规模
算法时间复杂度:针对指定基本运算,计数算法所做的运算次数
基本运算:比较,加法,乘法,置指针,交换… …
输入规模:输入串编码长度,通常用下述参数度量:数组元素多少,调度问题的任务个数,图的顶点数与边数等。
算法基本运算次数可表示为输入规模的函数,给定问题和基本运算就决定了一个算法类。
输入规模
排序:数组中元素个数n
检索:被检索数组的元素个数n
整数乘法:两个整数的位数mn
矩阵相乘:矩阵的行列数ijk
图的遍历:图的顶点数n边数m
基本运算
排序:元素之间的比较
检索:被检索的元素x与数组元素的比较
整数乘法:每位数字相乘(位乘)1次 m位和n位整数相乘要做mn次位乘
矩阵相乘:每对元素乘1次,ixj矩阵与jxk矩阵相乘要做ijk次乘法
图的遍历:置指针
算法两种时间复杂度
最坏情况下的时间复杂度W(n)
平均情况下的平均复杂度A(n)
算法的伪码描述
赋值语句:<—
分支语句:if…then…[else]
循环语句:while,for,repeat,until
转向语句:goto
输出语句:return
调用:直接写过程的名字
注释://…
注意伪码允许过程调用。
函数的渐进的界
常用的函数
大O符号
定义:设f和g是定义域为自然集N上的函数,若存在正数c和No使得对一切N>No有
0≤f(n)≤cg(n)
成立,则称为f(n)的渐近上界为g(n),记作
f(n)=O(g(n))
例子:设f(n)=n²+n则f(n)=O(n²),取c=2,n₀=1即可;f(n)=O(n³),取c=1,n₀=2即可;
1.f(n)=O(g(n)),f(n)的阶不高于g(n)的阶。
2.可能存在多个正数c,只要指出一个即可。
3.对前面有限个值可以不满足不等式。
4.常函数可以写作O(1)。
大Ω符号
定义:设f和g是定义域为自然集N上的函数,若存在正数c和No使得对一切N≥No有
0≤cg(n)≤f(n)成立,则称为f(n)的渐近下界为g(n),记作f(n)=Ω(g(n))
例子:设f(n)=n²+n则f(n)=Ω(n²),取c=1,n₀=1即可;f(n)=Ω(100n),取c=1/100,n₀=1即可;
1.f(n)=Ω(g(n)),f(n)的阶不低于g(n)的阶。
2.可能存在多个正数c,只要指出一个即可。
3.对前面有限个n值可以不满足上述不等式。
小o符号
定义:设f和g是定义域为自然集N上的函数,若存在正数c和No使得对一切N≥No有
0≤f(n)<cg(n)成立,记作f(n)=o(g(n))
例子:设f(n)=n²+n则f(n)=Ω(n²)
取c≥1显然成立,因为n²+n<cn³(n₀=2)任给1>c>0,取n₀>[2/c]即可。因为cn≥cn₀>2(当n≥n₀)
n²+n<2n²<cn³
1.f(n)=o(g(n)),f(n)的阶降低于g(n)的阶。
2.对于不同正数c,n₀不一样,c越小n₀越大。
3.对前面有限个n值可以不满足不等式。
小ω符号
定义:设f和g是定义域为自然集N上的函数,若对于任意正数c都存在No,使得对一切N≥No有0≤cg(n)<f(n)成立,记作f(n)=ω(g(n))。
例子:设f(n)=n²+n则f(n)=ω(n)
1.f(n)=ω(g(n)),f(n)的阶高于g(n)的阶。
2.对于不同的正数c,c越大N₀越大。
3.对前面有限个n值可以不满足不等式。
Õ符号
若f(n)=O(g(n))且f(n)=Ω(g(n)),记作f(n)=Õ(g(n))
例子:若f(n)=n²+n,g(n)=100n²,那么则f(n)=Õ(g(n))
1.f(n)的阶与g(n)的阶相等。
2.对前面有限个n值可以不满足条件。
序列求和方法
等差数列,等比数列与调和级数的求和公式
估计序列和 放大法求上界 用积分做和式的渐近的界
递推方程
斐波那契数列
汉诺塔问题
插入排序的迭代算法
迭代法
1、不断用递推方程的右部替换左部
2、每次替换随着n的降低在和式中多出一项
3、直到出现初值停止迭代
4、将初值代入并对和式求和
5、数学归纳法求解正确性
换元迭代
1、将对n的递归式换成其它变元k的递推式
2、对k迭代
3、将k的函数换为n的函数
差消法化简高阶递推方程
1.对于高阶递推方程先用差消发化简为一阶方程
2.迭代求解
递归树的概念
- 递归树是迭代的模型
- 递归树的生成过程与迭代过程一致
- 递归树上所有项恰好是迭代之后产生和式中的项
- 对递归树上的项求和就是迭代后方程的解
迭代在递归树的表示
如果递归树上某个节点标记为W(m)
W(m)=W(m1)+…+W(mt)+f(m)+…+g(m),m1…,mt<m
其中W(m1)… …W(mt)称为函数项

递归树的生成规则
- 初始递归树只有根节点,其值为W(n)
- 不断继续下述过程:
将函数项叶结点的迭代式W(m)表示为二层子树,用该子树替换成该叶子结点 - 继续递归树的生成,直到树中无函数项(只有初值)为止。
主定理应用背景

主定理定义



分治策略
1.将原始问题划分或者归结为规模较小的子问题
2.递归或迭代求解每个子问题
3.将子问题的解综合得到原问题的解
注意
1.子问题与原始问题的性质完全一样
2.子问题之间可彼此独立的求解
3.递归停止时子问题可直接求解
算法设计思想
1、将原问题归结为规模为n-1的2个子问题。
2、继续归约,将原问题归结为规模为n-2的4个子问题,继续…,当子问题规模为1时,归约过程截止。
3、从规模1到n-1的解。直到规模为n。
二分检索算法设计思想
- 通过x与中位数的比较,将原问题归结为规模减半的子问题,如果x小于中位数,则子问题由小于x的数构成,否则子问题由大于x的数构成
- 对于子问题进行二分检索
- 当子问题规模为1时,直接比较x与T[m],若相等则返回m,否则返回0。
二分检索时间复杂度分析
二分检索问题最坏情况下时间复杂度W(n)=W([n/2])+1
W(1)=1
可以解出
W(n)=[logn]+1
二分归并排序设计思想
- 划分将原问题归结为规模为n/2的2个子问题
- 继续划分,将原问题归结为规模为n/4的4个子问题,继续…,当子问题规模为1时,划分结束。
- 从规模1到n/2,陆续归并排好序的两个子数组,每归并一次,数组规模扩大到一倍,直到原始数组。
二分归并排序时间复杂度分析
假设n为2的幂,二分归并排序最坏的情况下时间复杂度
W(n)=2W(n/2)+n-1
W(1)=0
可以解出
W(n)=nlogn-n+1
分治算法的一般描述
划分或规约为批次的里的子问题分别求解每个子问题的解,给出递归或迭代的计算的终止条件,如何由子问题的解得到原问题的解。
 设计要点
设计要点
- 原问题可以划分或者过约为规模较小的子问题
子问题与原问题具有相同的性质
子问题的求解彼此独立
划分时子问题的国模尽可能的均衡 - 子问题规模足够小时可直接求解
- 子问题的解综合得到原问题的解
- 算法实现:递归或迭代
分治算法时间分析
求解时间复杂度的递推方程,常用的递推方程的解。

两类常见的递推方程

递推方程的求解


快速排序基本思想:
- 假设A[p…r]的元素彼此不等,以首元素A[1]对数组A[p…r]划分,使得:小于x的元素放在A[p…q-1],大于x的元素放在A[q+1…r]。
- 递归对A[p…q-1]和A[q+1…r]排序。直到子问题的规模为1为止。
- 工作量:子问题工作量+划分工作
- 小结:
1.分治策略
2.子问题划分是由首元素决定的
3.最坏情况下时间O(n平方)
4.平均情况下时间O(nlogn)



改进分治算法之减少子问题数目
适用于:子问题个数多,划分和综合工作量不太大,时间复杂度为W(n)=O(n的logba次方)
利用子问题依赖关系,用某些子问题的解的代数表达式表示另一些子问题的解,减少独立计算子问题个数。
综合解的工作量可能会增加,但增加的工作量不影响W(n)的阶。
改进分治算法的途径之增加预处理
依据:W(n)=aW(n/b)+f(n)
增加预处理减少f(n)
最短路径问题
问题:
输入:
起点集合{s1,s2,…,sn},
终点集合{T1,T2,…,Tn},
中间结点集,边集E,对于任意e有长度
输出:一条从起点到终点的最短路径
最短路径算法设计
蛮力算法:
考察每一条从某个起点到某个终点的路径,计算程度,从其中找出最短路径。
动态规划算法:
多阶段决策过程。每步求解的问题是后面阶段求解问题的子问题。每部决策讲义俩以前步骤的决策结果。
优化原则:最优子结构
优化函数的特点:任何最短路的子路径相对于子问题始、终点最短。

优化原则:一个最优决策序列的任何子序列本身一定是相对于子序列的初始和结束状态的最有决策序列。
动态规划
- 求解过程事多阶段决策过程,每步处理是一个子问题,可用于求解组合优化问题。
- 适用条件:问题要满足优化原则或最优子结构性质,即:一个最优决策序列的任何子序列本身一定是相对于子序列的初始和结束状态的最优决策序列。
动态规划设计要素
- 问题建模,优化目标函数、约束条件是什么?
- 如何划分子问题(边界)?
- 问题的优化函数值与子问题的优化函数值存在什么依赖关系(递推方程)?
- 是否满足优化原则?
- 最小问题怎么界定?其优化函数值,即初值等于什么?
动态规划算法
- 多阶段决策过程,没不出力一个子问题,界定子问题的边界
- 列出优化函数的递推方程及初值
- 问题满足优化原则或最优子结构性质,即:一个最优决策序列的任何子序列本身一定是相对于子序列的初始和结束状态的最优决策序列。





动态规划算法的递归实现
- 与蛮力算法相比较,动态规划算法利用了子问题优化函数见得依赖关系,时间复杂度降低。
- 动态规划算法的递归实现效率不高,原因在于同一个子问题多次重复出现,每次出现都需要重新计算一遍。
- 采用空间换时间策略,记录每个子问题首次计算结果。后面再用时就直接取值,每个子问题只算一次。
迭代计算的关键
- 每个子问题计算一次
- 迭代过程:
1.从最小子问题算起
2.考虑就算顺序,以保证后面用到的值前面以及计算好
3.存储结构保存计算结果——备忘录 - 解的追踪:
1.设计标记函数标记每步的决策
2.考虑根据标记函数追踪解的算法
实现比较
-
递归实现:时间复杂性高,空间较小。
迭代实现:时间复杂性低,空间消耗多。 -
原因:递归实现子问题多次重复计算,子问计算次数呈指数增长,迭代实现每个子问题计算一次。
-
动态规划时间复杂度:
备忘录各项计算之和+追踪工作量
通常追踪工作量不超过计算工作量,是问题规模的多项式函数。
动态规划算法的要素:
- 划分子问题,确定子问题的边界,将问题求解转变为多步判断的过程。
- 定义优化函数,已改函数极大或者极小值作为依据,确定是否满足优化原则。
- 列优化函数的递推方程和边界条件
- 自底向上计算,设计备忘录(表格)
- 考虑是否需要设立标记函数
- 用递推方程或备忘录估计时间复杂度
最优二叉检索树
二叉检索树:集合为S为排序的n个元素,x1<x2<…<xn将这些元素存储在一棵二叉树的结点上,以查找x是否在这些数中,如果x不在,确定x在那个空隙中(方结点)。
二叉树检索方法
1、初始,x与根元素比较;
2、x小于根元素,递归进入左子树
3、x大于根元素,递归进入右子树
4、x等于根元素,算法停止,输出x
5、x到叶结点算法停止,输出x不在数组。
动态规划算法的设计要点
1、 引入参数来界定子问题的边界,注意子问题的重叠程度
2、 给出带边界参数的优化函数定义与优化函数的递推关系,找出递推关系的初值。
3、判断优化问题是否满足优化原则
4、考虑是否标记函数
5、采用自底向上的实现技术,从小的子问题开始迭代计算,计算过程中用备忘录保留优化函数和标记函数的值。
6、 动态规划算法的时间复杂度是对所有的子问题(备忘录)的计算工作量求和(可能需要追踪解的工作量)
7、动态规划算法一般使用较多的存储空间,这往往成为限制动态规划算法使用的瓶颈因素。
贪心算法的特点
设计要素:
1、贪心法适用于组合优化问题。
2、求解过程是多步判断的过程,最终的判断序列对应于问题的最优解。
3、依据某种“短视的”贪心选择性质判断,性质好坏决定算法的成败。
4、贪心法必须进行正确性证明。方法一般为数学归纳法,交换论证法。
5、证明贪心法不正确的技巧:举反例
贪心法的优势:算法简单,时间和空间复杂度低。
得不到最优解的处理
输入参数分析:考虑输入参数什么取值范围内使用贪心法可以得到最优解
误差分析:估计贪心法——近似算法所得到的解与最优解的误差(对所有输入实例在最坏情况下误差的上界)
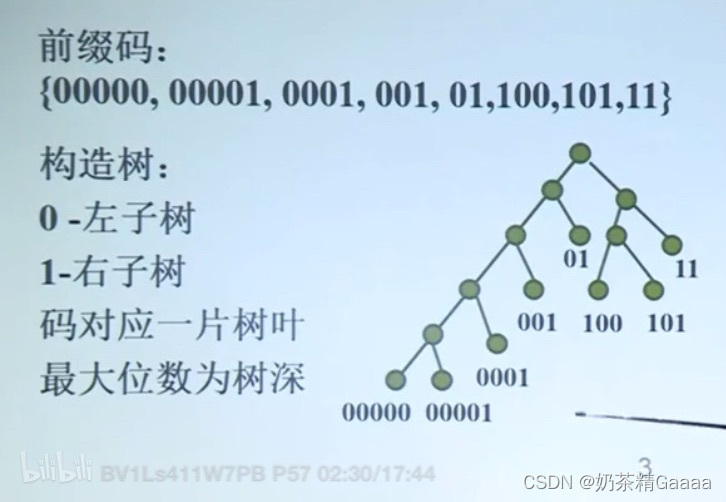
二元前缀码
1、定义:用01字符代码表示字符,要求任何字符的代码都不能作为其他的字符代码的前缀。
2、非前缀码的例子:a:001, b:00, c:010,d:01
3、解码的歧义,例如字符串010000
解码1:01,00,001。dba
解码2:010,00,01 cbd
前缀码的二叉树表示
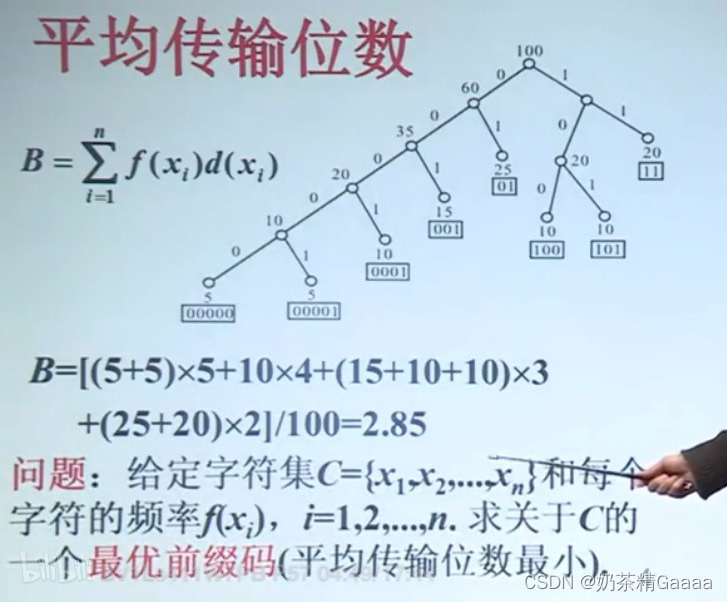
哈夫曼算法:

前缀码的性质:
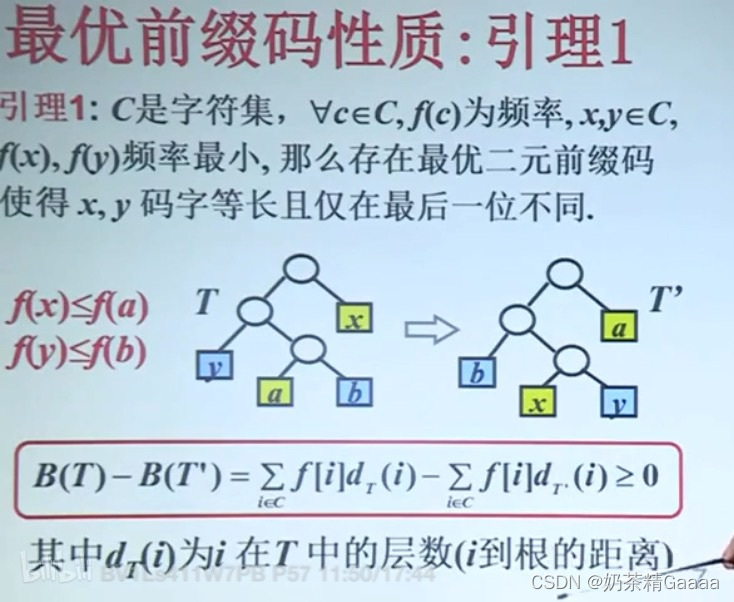
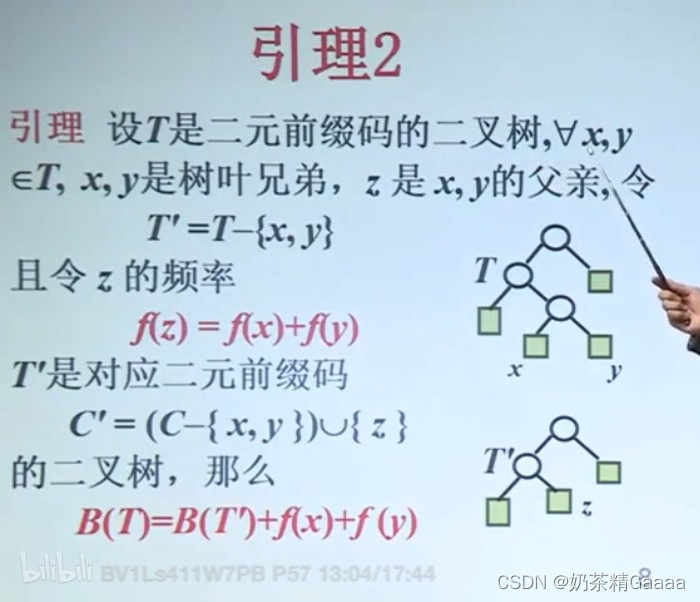
哈夫曼算法的正确性证明:对规模归纳
哈夫曼算法应用:文件合并
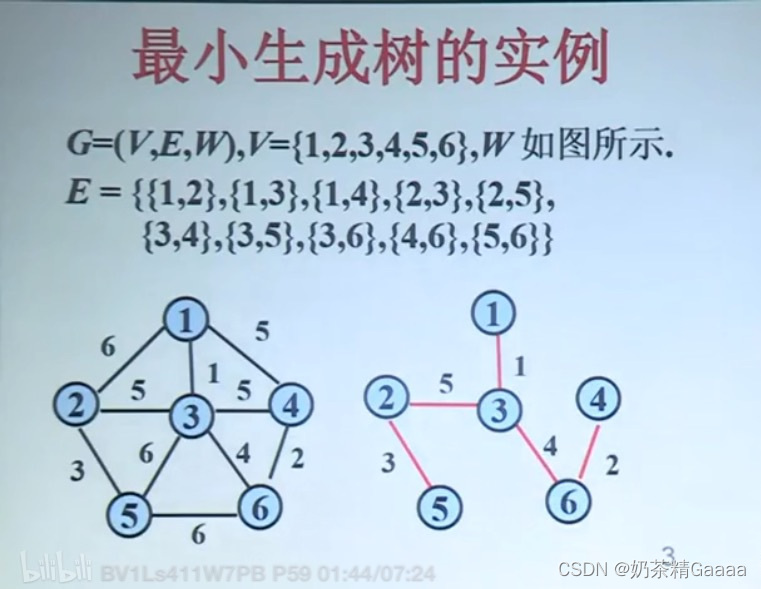
最小生成树
无向连通图G(V,E,W)
其中为w(e)属于W是边e的权
G的一棵生成树T是包含了G的所有顶点的树,树的各边的权之和,W(T)称为树的权,具有最小权的生成树称为G的最小生成树。
生成树的例子
生成树的性质
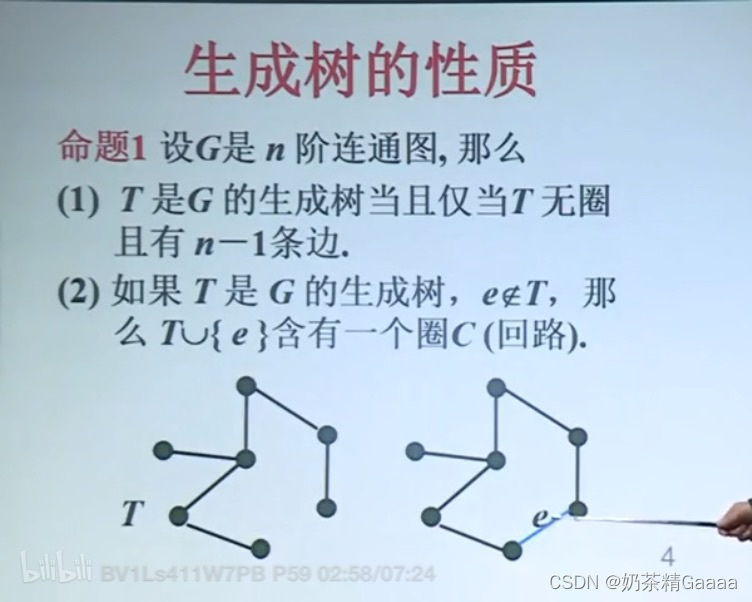

生成树性质的应用

求最小生成树

Prim算法


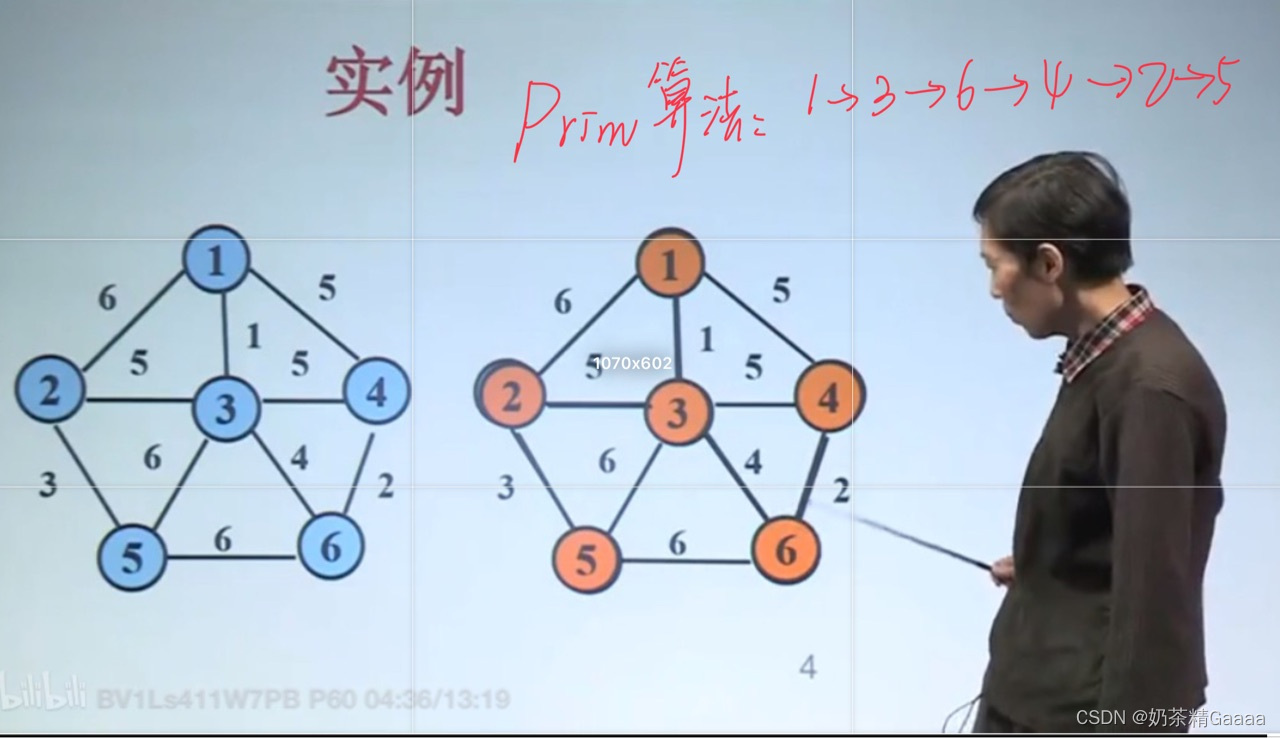
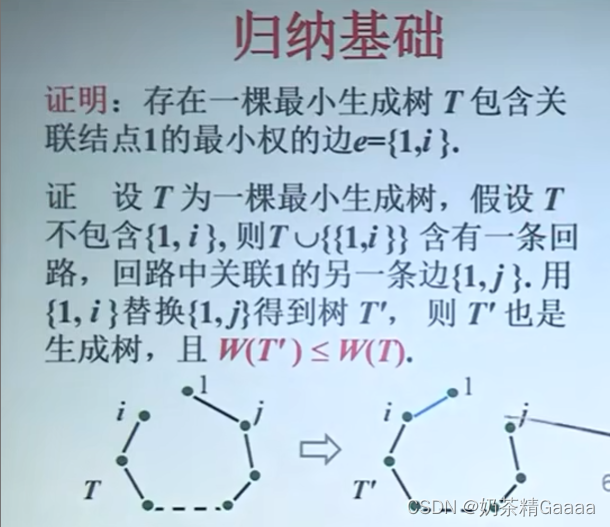
prim算法正确性归纳



prim时间复杂度

prim小结

kruskal算法
设计思想
、


算法正确性证明思路

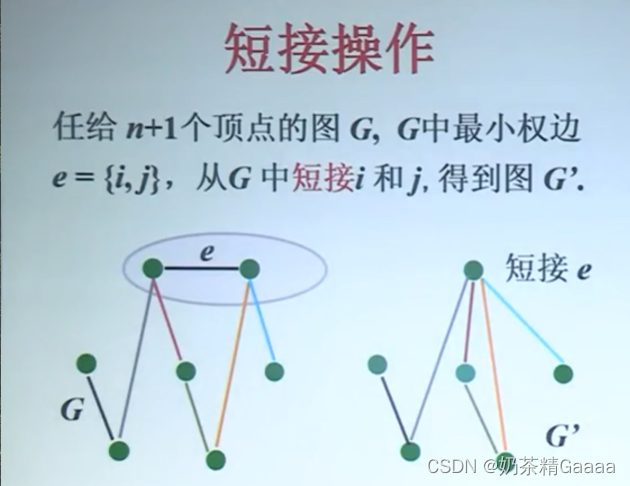


算法实现和时间复杂度



单源最短路问题

Dijkstra算法有关概念

算法设计思想


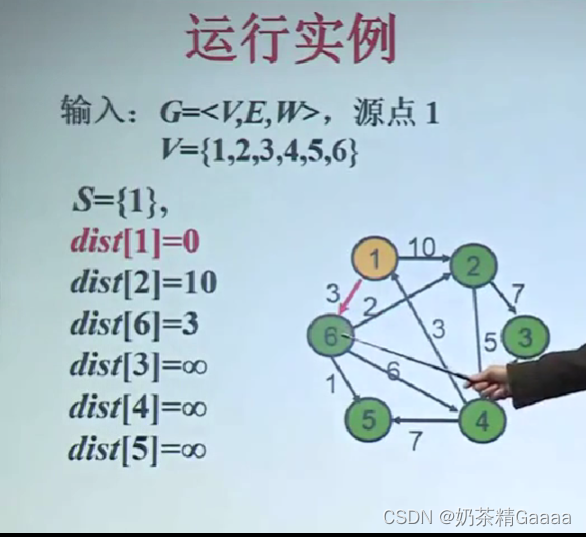
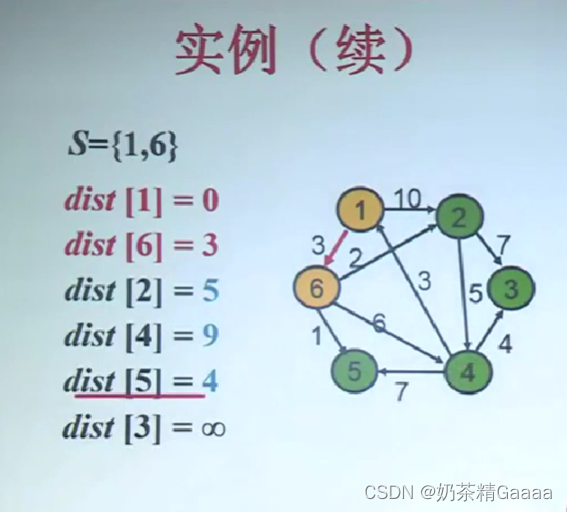
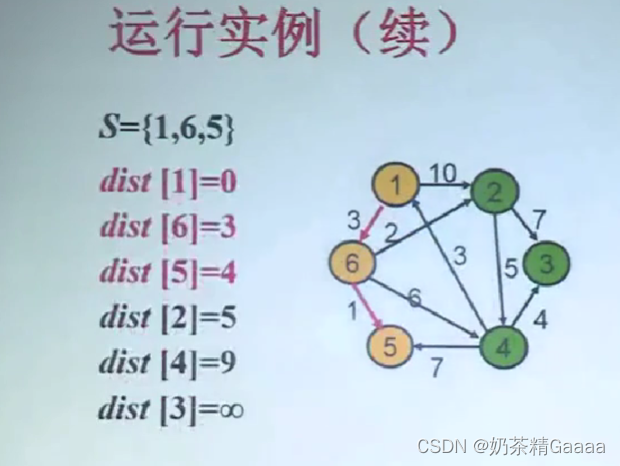
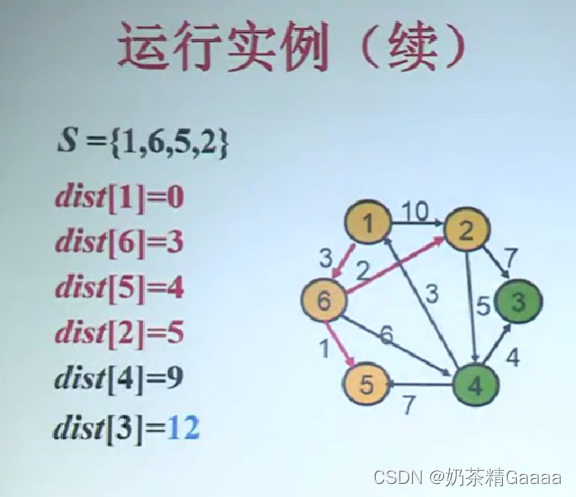
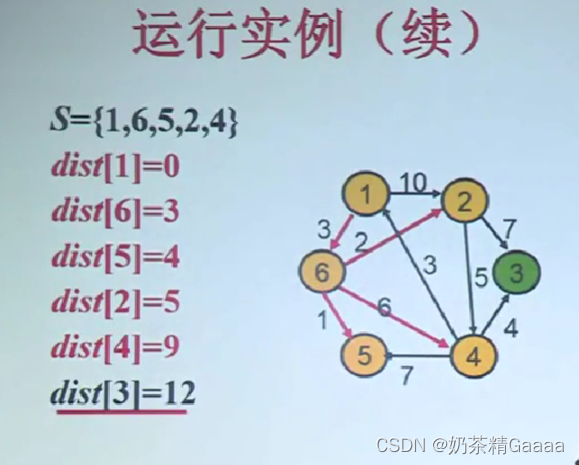

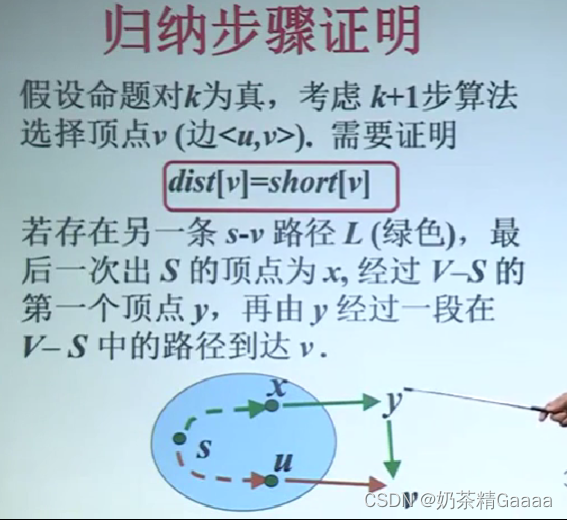
Dijkstra算法正确性
归纳性证明:



贪心法小结
1、贪心法适用于组合优化问题
2、求解过程事多步判断过程,最终的判断序列对应于问题的最优解。
3、判断依据某种“短视的”谈心选择性质,性质的好坏决定了算法的正确性,贪心性质的选择往往依赖于直觉或者经验。
4、贪心法的正确性证明方法:
(1)直接计算优化函数,贪心法的解恰好取得最优值。
(2)数学归纳法(对算法部署或者问题规模归纳)
(3)交换论证
5、证明谈心算法不对:举反例
6、对于某些不能保证对所有的示例得到最优解的贪心算法(近似算法),可做参数化的逆袭或者误差分析。
7、贪心法的优势:代码简单,时间复杂性和空间复杂性低。
8、几个著名的贪心算法:最小生成树的 Prim算法、最小生成树的Kruskal算法、单源最短路径Dijkstra算法
回溯算法
例子:n后问题,01背包,货郎问题等。
解都为向量
搜索空间:树,可能是n叉树、子集树、排列树等等,树的结点对应于部分向量,可行解在叶节点。
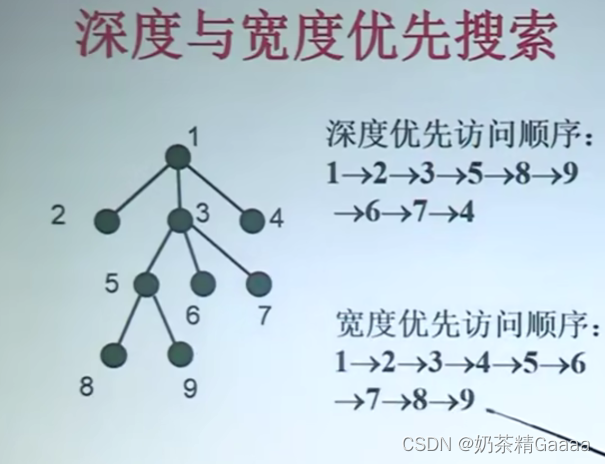
搜索方法:深度优先,宽度优先,跳跃式遍历搜索树,找到解。
回溯算法的思想和适用条件
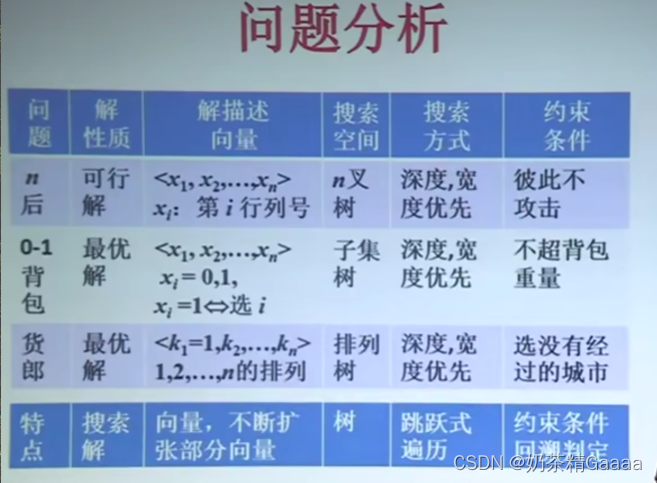
回溯算法的基本思想
(1)适用:求解搜索问题和优化问题
(2)搜索键:树,结点对应部分解向量,可行解在树叶上。
(3)搜索过程:采用系统的方法隐含遍历搜索树
(4)搜索策略:深度优先、宽度优先、函数优先、宽深结合等。
(5)及诶点分支判定条件:
满足约束条件——分治扩张解向量,不满足约束条件,回溯到该节点的父结点。
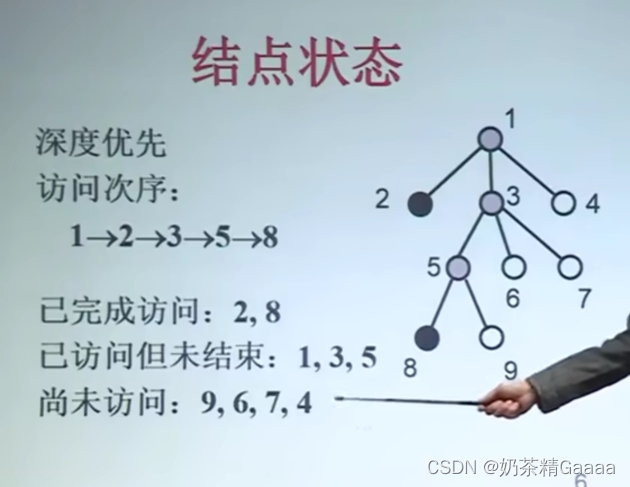
(6)结点状态:动态生成
白结点(尚未访问)
灰结点(正在访问该结点为根的子树)
黑结点(该结点为根的字数遍历完成)
(7)存储:当前路径
回溯算法的适用条件



回溯算法递归实现

















 789
789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











