






机器学习好歹也算是前沿领域,这样的idea不能说俯拾皆是吧,但至少也是打着灯笼就能找着的。咱们先从“简单”的开始。
Word2Vec
顾名思义,其实就是把语文的“词”变成数学的“向量”。应该没有比这更简单的了吧,但是当Mikolov等人在2013年提出这个idea时,还是让圈内为之一振。毕竟,那个时候人们还认为“词”是一个离散的概念,然而经过训练的Word2Vec模型居然能够捕获语言中的多种细微关系。 例如,通过简单的向量运算,我们可以得到"king" - “man” + “woman” ≈ “queen”,模型就这样学习到了“潜台词”!
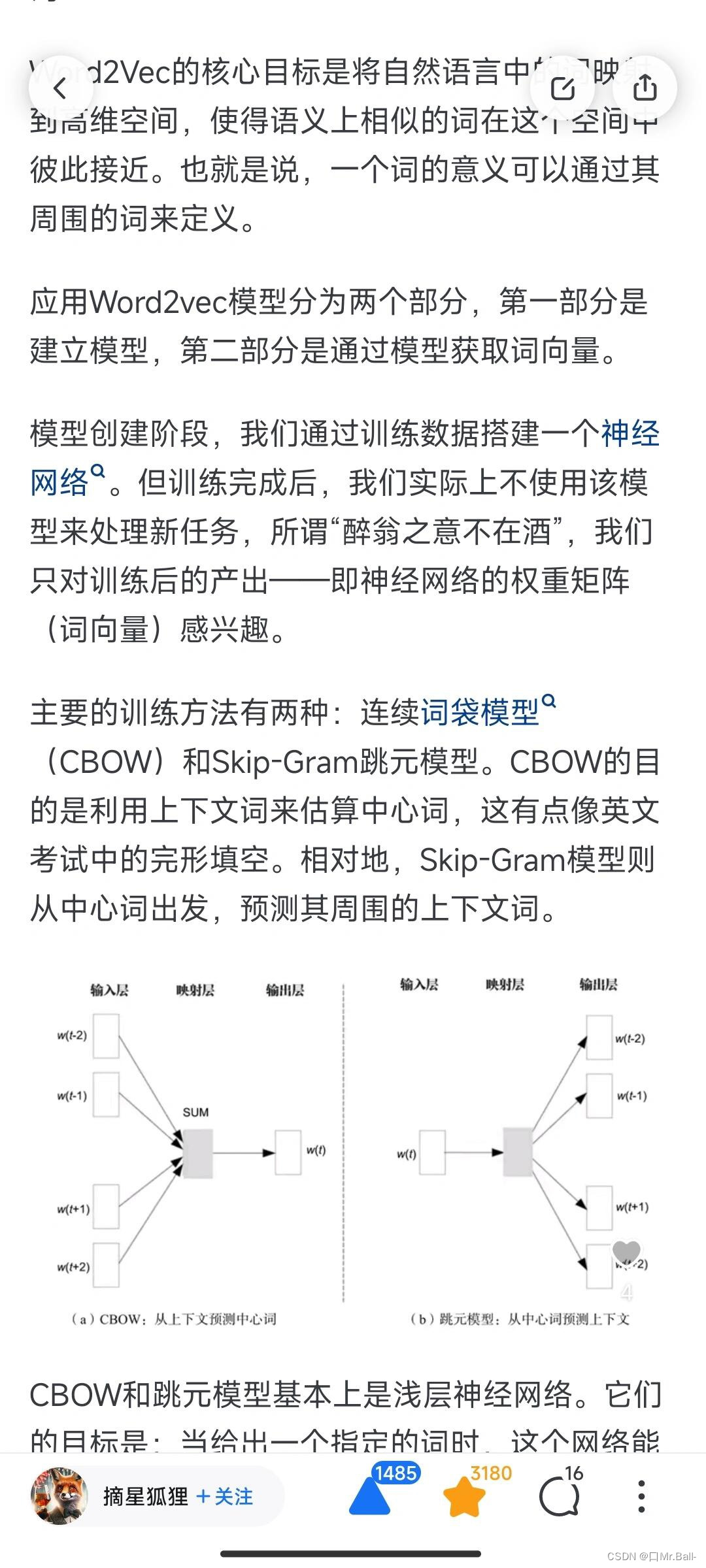
Word2Vec的核心目标是将自然语言中的词映射到高维空间,使得语义上相似的词在这个空间中彼此接近。也就是说,一个词的意义可以通过其周围的词来定义。
Residual Networks (残差网络)
自Word2Vec使用了浅层神经网络尝到甜头之后,人们便开始研究更深层的神经网络。
然而,深度模型尽管功能强大,但训练它们却经常遭遇许多难题。特别是当我们尝试训练一个非常深的神经网络时,常常遇到的问题是“梯度消失”或“梯度爆炸”。
想象你在玩电话传话游戏,每个人都需要向下一个人传递消息,这里的消息就是梯度,每个人则代表神经网络的一层。传递过程中,信息可能出现微小变化,导致最后的信息与原始信息大相径庭。在深层网络中,初次的梯度在每层都可能减弱,使得后续层缺少调整依据,这称为“梯度消失”。相反,“梯度爆炸”是指梯度异常增强,导致网络学习失控。
在2015年,一个叫做ResNet(Residual Network)的模型横空出世,它用残差连接解决了上述问题。
传统的深度学习模型通常是在每一层都尝试学习数据的完整表示,但ResNets 提出了一个出乎意料的观点:为什么不只让每一层学习与前一层表示相比的“残差”或者说“变化”呢?
Attention Mechanism (注意力机制)
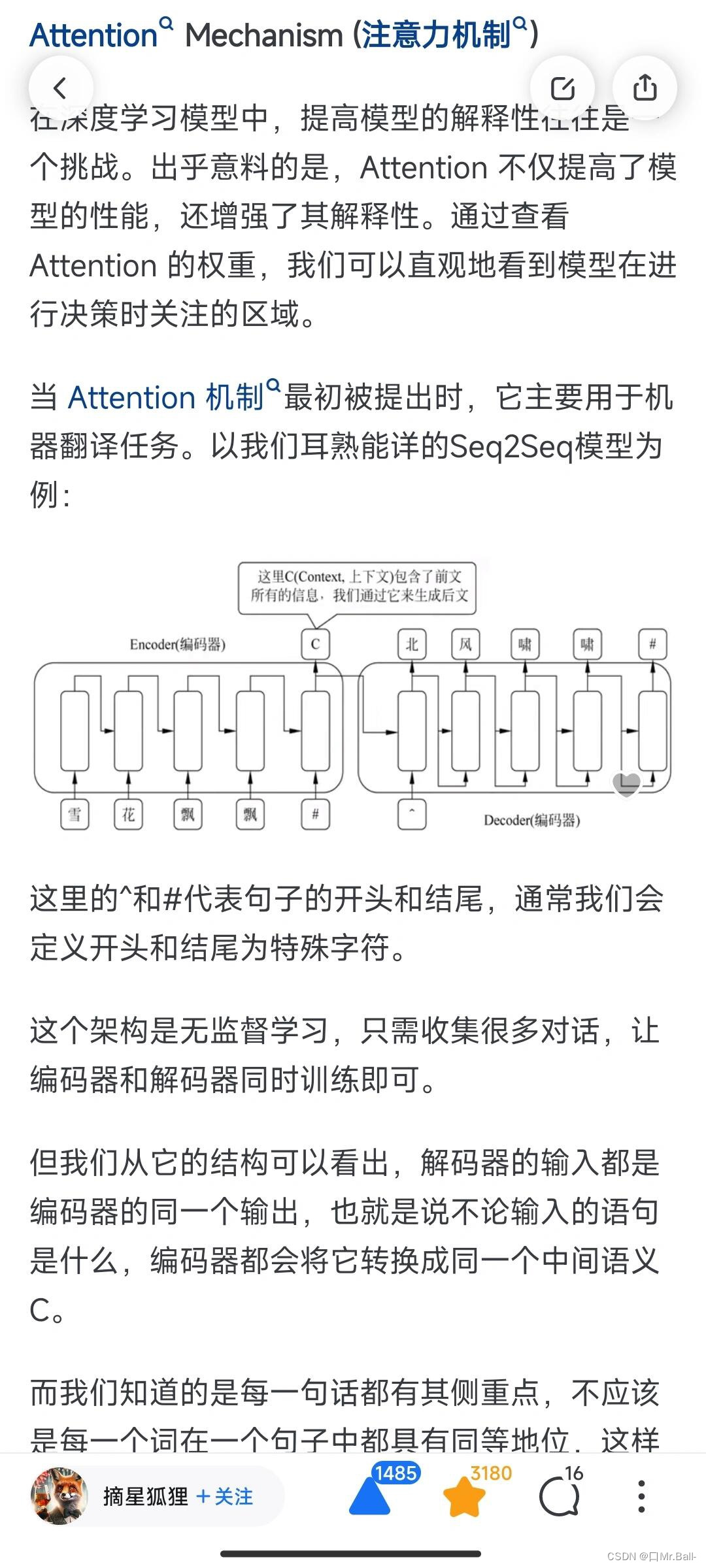
在深度学习模型中,提高模型的解释性往往是一个挑战。出乎意料的是,Attention 不仅提高了模型的性能,还增强了其解释性。通过查看 Attention 的权重,我们可以直观地看到模型在进行决策时关注的区域。
想象一下,你在学习英语时,遇到一个句子:“The cat sat on the ___.”,你需要填空,那你填什么?你会注意到"cat"这个词,因为它决定了填空处的单词是"chair"还是"table",而不是"sun"或"moon"。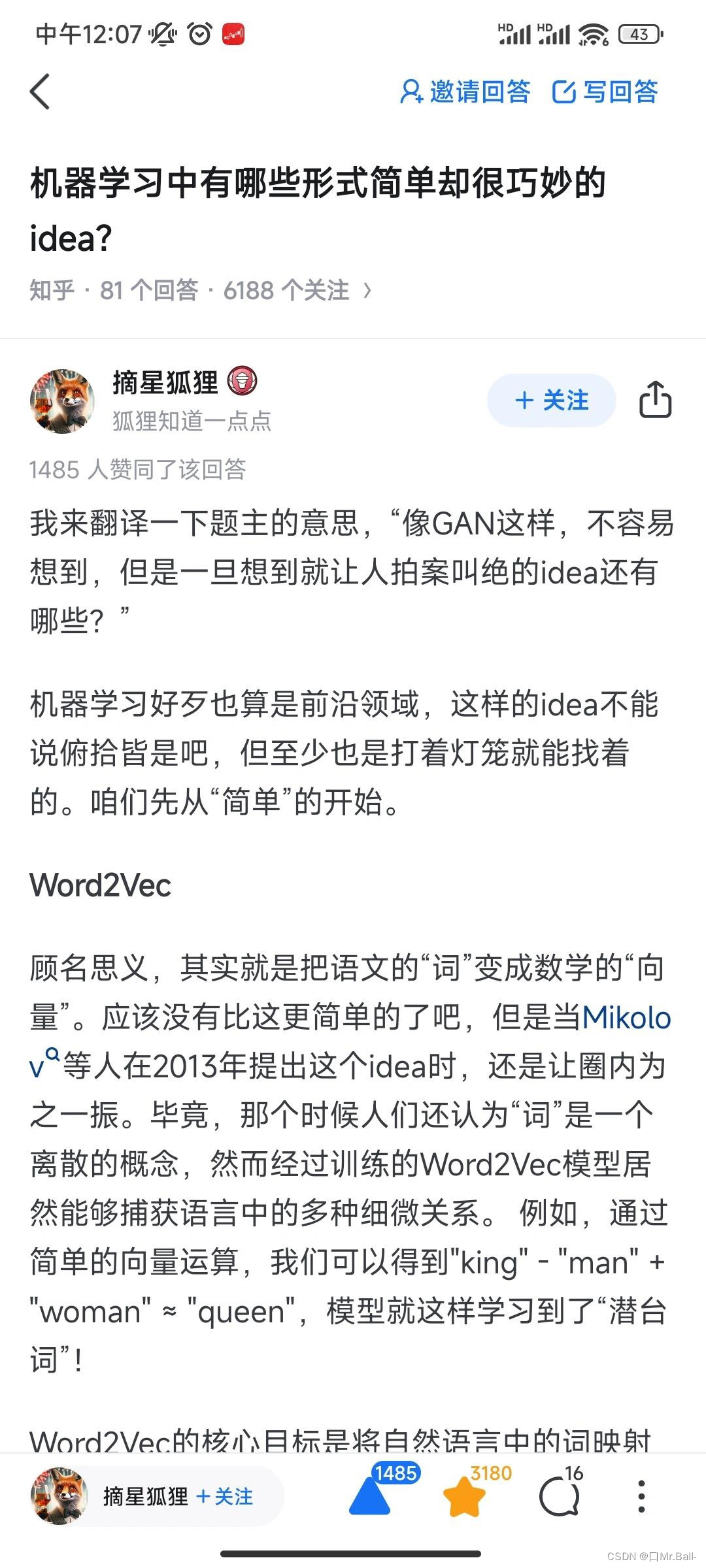






















 933
933
02-26

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











