




笔者之前写过一些论文的讲解文章,都是按照论文的基本顺序:摘要、介绍、相关工作、方法、实验和总结的顺序。这星期在实验室论文分享上,分享了《Extracting Multiple-Relations in One-Pass with Pre-Trained Transformers》这篇文章,突然有了想法,如果一味的按照论文的顺序写一些类似于“翻译”的博客,也没有什么价值。不如按照自己的思路,能把别人讲懂了,比什么都强。这篇博客,我按照我自己理解的逻辑,来给大家讲解这篇文章,以后的文章也都按照这样的思路,希望对大家有所帮助,对自己也是一个学习记录和加深理解的过程!
论文链接:Extracting Multiple-Relations in One-Pass with Pre-Trained Transformers
1.背景
这篇论文是由腾讯和IBM实验室合作发表在2019年ACL会议的一篇文章,名为:《利用预训练Transformers做一次性编码抽取出多个关系》(《Extracting Multiple-Relations in One-Pass with Pre-Trained Transformers》) ,属于关系抽取类的文章。
关系抽取简单来说就是从一句话中抽取出三元组(实体1,关系,实体2),举个例子:
东北大学坐落于沈阳市。---抽取出---->(东北大学,位于,沈阳市) ps:这里类似于‘位于’这样的关系是会给出的
那么,抽取出这样的三元组会有什么作用呢?例如,我们可以根据这样的三元组,构建出基于三元组的知识图谱,如下图所示:
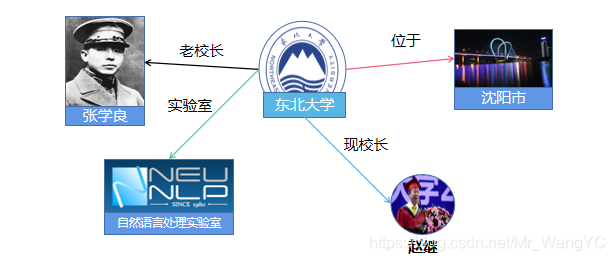
基于这样的知识图谱我们可以有很多的下游应用,比如说:搜索引擎、问答系统等等。
2.论文解决的问题
以上是对关系抽取概念的简单介绍,既然,该论文属于关系抽取领域,那么我们就来看一看它是从关系抽取的那个方向和问题出发的。首先,我们有如图所示的一张关系表:
| 关系表 |
|---|
| 位于 |
| 校长 |
| 所属专辑 |
| ........ |
有这样的一句话:“赵继 担任沈阳市 东北大学 校长”。这就句话中红色字体标出的(赵继、沈阳市、东北大学)三个实体已经给出,并且已知赵继和东北大学有某种关系,东北大学和沈阳市有某种关系,论文中要做的就是说在已知一句话和东北大学、赵继有关系推断出是校长这个关系,同理,已知东北大学和沈阳市,推断出位于这个关系。简单来说是一个关系分类问题;这个任务的特点就是说一句话中有多对已知的实体,并且有多个未知的推断出的关系。
2.1以往解决方法
对于这种一句话有多对已知实体,并且需要推出对应多个未知关系的问题,以往的解决方法是:将一句话对应的多个关系,强拆分为一句话只对应一个关系。如下图所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 649
649







 到【灌水乐园】发言
到【灌水乐园】发言







