







笔者最近在学习利用远程监督范式做关系抽取任务。在读论文和调试代码的过程中,发现有些论文里的细节我是在调试代码才弄懂的,例如论文中说的Precision和Recall值指的是多示例学习中包级别的准确率和召回率。那么多示例学习是什么呢?远程监督有事如何做关系抽取任务的呢?相信这篇文章你会有一定的收货~
背景
关系抽取任务是在非结构化的文本中抽取出关系事实,并且这种关系事实可以应用到知识图谱、问答、搜索引擎等下游任务当中。神经网络的出现,使得有监督的关系抽取得到了很好的提升,但是有监督的学习对有标注的数据非常依赖。而人工标注数据费时费力,代价昂贵。所以如何让机器自动的构造训练集得到了人们的广泛关注。远距离监督就是为了解决自动构造数据的问题,通过远距离监督构造更多数据、更多实体、更多关系的带标签数据集。这篇文章,就是对远距离监督算法在关系抽取上的梳理和总结。
1 介绍
关系抽取是自然语言处理中的关键任务,即从非结构化的文本中抽取出关系事实;该关系事实以”(实体1,关系,实体2)”这样的三元组方式存储。以三元组方式存储的关系事实又可以应用到知识图谱、问答系统和搜索引擎等等的应用当中。
随着深度学习的蓬勃发展,也带动了自然语言处理领域的进步。神经网络的出现,使的有监督的关系抽取系统的性能得到了很大的提升。然而这种有监督的关系抽取范式对带标签的数据有很强的依赖性,人工标注数据费时费力,代价昂贵。于是就有另一种基于无监督的范式做关系抽取任务,这种方法不需要有标签的数据,仅仅用无标签的数据,采取聚类的算法,将所有的文本进行分类,然后利用每个类别中的文本,自动总结归纳出关系属性。然而这种做法也是有一定的弊端,无监督的做法的确可以在大量的无标签信息中抽取出大量的关系事实,但是该关系事实规范化程度很差(例如,关系“出生地”可能会归纳为“故乡”,“出生的地方”,“出生于”等等相似的关系),很难映射到知识图谱当中,也影响其他基于关系事实的应用。
基于以上叙述,那么如何让机器自动的构造带标签的数据呢?Mintz在2009年第一次在ACL会议提出的远距离监督范式就是来解决这一问题的。远距离监督范式,利用现存的知识库(例如:FreeBase)和大型语料库(例如:Wiki)采用启发式对齐的放式来生成数据,即远距离监督的假设:在知识库中,某个关系的两个实体包含在语料库中的某句文本中,则该文本就某种程度上表示该关系。语料库中的某文本符合该假设,那么就将这个文本加入到对应关系的训练集合当中。因为关系是在知识库中提取的,所以有很好的规范性。根据这种方法可以构造一个很大的训练集,当然这种训练集是包含很多噪音数据集的。原因是例如在知识库中有关系事实“(比尔盖茨,创始人,微软公司)”,如果文本是“1975年,比尔盖茨创立了微软公司”文本符合该关系事实。然而,现实不能总是这么理想化的,如果文本是“2008年 6月27日,比尔盖茨从微软公司退休,结束了他的职业生涯”,那么文本就不符合上文中的关系事实,则该标记就是错误的,即噪音数据。
总之,远距离监督的范式既弥补了有监督范式缓解签数据缺乏的缺点,又弥补了无监督范式关系的规范化问题。然而在生成数据的过程中,会引入大量的噪声数据,如何在有大量噪声数据(noise data)的训练集中,挑选正确的数据集(clean data)自然而然的成为了远距离监督学习研究的重点。以后的部分中,我们也是基于这个重点,对远距离监督方法进行梳理和总结。
2 相关工作
早期(Mintz et al., 2009)提出了远距离监督的方式应用于关系抽取任务当中。(Riedel et al,2010)将多示例学习应用到远距离监督处理数据中,其忽略了一句话中可能包含多个关系。于是(Surdeanu et al., 2012; Hoffmann et al.,2011)多示例、多标签学习,来对假设每个关系实例至少有一个句子正确的表达了该关系进行建模(个人理解该假设的意思是:每一个句子至少表达了一个关系)。随着神经网络的兴起,PCNN(Zeng et al., 2015)成为最流行的编码结构,并且使用多示例学习算法对生成的数据集进行分类,提取。随后又有一些工作在对句子间特征提取上运用了attention机制(Lin et al., 2016;Han et al., 2018)。
3 方法综述
要了解远程监督关系抽的方法,我们先要对这种范式的流程掌握清楚:首先我们要通过Freebase知识库和wiki等语料库启发对其的方式得到数据;接下来,以按照实体对以及对应的关系将文本分包处理,作为多示例学习的输入;接下来将输入向量化,得到句向量特征;然后,根据句向量特征得到包向量特征;最后,训练分类器。
3.1 如何得到训练数据?
首先,远距离监督的假设是在数据库中存在某关系事实,如果语料库中的某一文本包含该关系事实中的两个实体,则这一文本就表示关系事实中的关系,那么就将这一文本作为对应关系的训练数据。如下图所示:
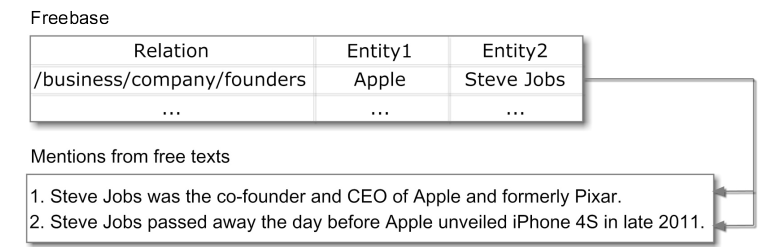
如上如所示,在Freebase的关系事实中包含“Apple”和“Steve Jobs”这两个实体,在语料库中找到也包含这两个实体的文本,那么该文本就表示“/busuness/company/founders”这个关系,将这两个文本作为该关系的训练数据。
Steve Jobs was the co-founder and CEO of Apple and formerly Pixar.
Steve Jobs passed away the day before Apple unveiled iPhone 4S in late 2011.
3.2 多示例学习
上述中生成数据的假设很不现实,因为一定有某句话包含两个实体但是却不表示仍和关系的情况。两者很可能是一种并列的状态,没有任何关系。
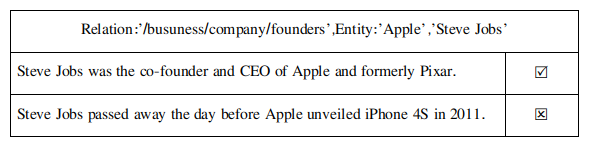
上表所示的数据中,在乔布斯是苹果公司创始人的关系事实下提取到的两个训练数据,第一个是标注正确的数据,而第二个“乔布斯在2011年苹果4S的发布会前一天去世”,很明显与“乔布斯是苹果公司创始人”这个关系事实没有任何的关系,是一个噪音数据。针对这种“噪音数据横行”的问题,多示例学习的应用,就在很大程度上缓解了这一问题。
多示例学习是在包级别上进行分类,所谓包级别就是一个包内可能有一条或一条以上条数据,这个包的关系类别是已知的,但是包内每条数据的类别是未知的(允许包内含有噪声数据)。注意,多示例学习的假设:如果包内所有的数据均为负示例,则该包为负示例包(负包),如果包内至少有一条数据为正示例,则该包为正示例包(正包)。该假设正好符合我们远距离监督生成数据的特点,给了模型一定的容错空间。
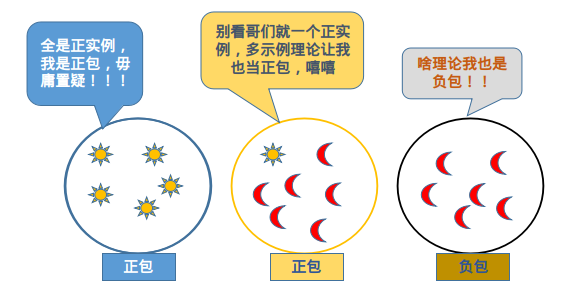
在远距离监督做关系抽取的任务上,多示例学习的应用举例:首先按照相同实体对以及对应的关系对数据进行打包处理。举例来说,将所有或部分的数据包含“Steven Jobs”和“Apple”的数据打包在一起,并且将这个包的标签赋值为“/busuness/company/founders”,即该包中至少有一个“/busuness/company/founders”关系的正例。然后通过提取包级别的特征,对包的类别进行分类训练。
3.3 句子特征和包特征的获取
3.3.1 Piecewise Convolutional Neural Networks
在2009年Mintz提出远距离监督任务后,2015年Zeng等人提出了非常经典的模型,即PCNN(Piecewise Convolutional Neural Networks)分段卷积模型。模型结构如下图所示:
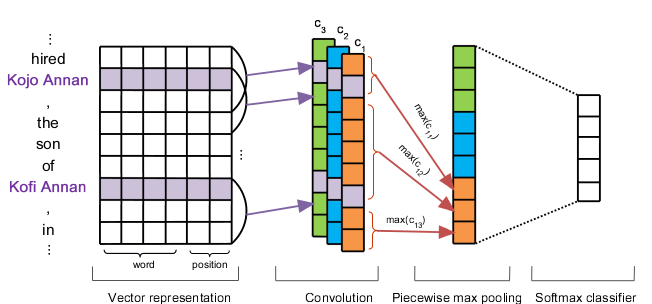
该模型采用卷积网络(CNN)来自动提取文本特征,并且在不同维度上,使用多个卷积核提取不同维度的特征,然后以两个实体为边界,将文本分为三段,接下来取每一段的最大特征值拼接在一起,作为最后分类之前的特征,通过softmax分类器,得到最终文本在各类别的分数。这里需要注意,在做远程监督关系抽取时,我们需要分类的不是对句子级别的分类,而是要在包级别上进行分类,所以如何将句子级别的特征转化为包级别的特征呢?在Zeng的这篇文章中,在得到包内所有句子级别的特征后,我们选择包内对应类别分数最大的句子特征,作为整个包的特征,与标签进行梯度计算,下文中提到的Precision-recall也是在包级而言的。
3.3.2 PCNN + Attention
在上文的PCNN框架中,PCNN捕捉到的包向量是包内对应分数最大的句子级别的向量,因而在每个包内仅抽取一个句子,然而这种做法会屏蔽掉包内其他句子的信息,提取到的特征可能是片面的。
2016年清华大学刘知远团队提出在PCNN基础上加入Attention机制,很自然的为包内的句子加上权重,包的特征向量为包内每个句子向量和各自权重的加和平均。这么做的目的是为了充分利用包内的信息,更好、更全面的提取包的信息。结构图如下:
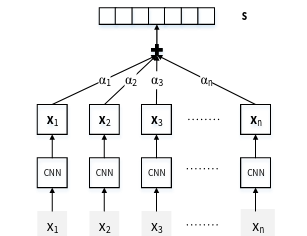
如上图所示,是一个基于CNN的模型,首先利用CNN提取各个句子的信息,注意如果是CNN的话,做的maxpooling是普通的最大池化,只有PCNN的最大池化是需要分段的,在得到包内每个实例的特征向量之后,为每个实例加上注意力权重,该权重代表的是每个向量对包特征的贡献程度。贡献程度越高,权重也越高。最后用权重和向量乘积求和,得到包的最终特征向量。而基于PCNN编码的模型,只不过是把图4中的CNN替换为PCNN而已。这个模型对比单纯的PCNN模型,有了很明显的提升。
4 数据集
NYT10数据集是远距离监督做关系抽取任务的标准数据集。它是通过将Freebase和《纽约时报》语料库相结合而产生的,训练集部分来自2005~2006年的数据,测试机部分来自2007年的数据。
在NYT10数据集中,训练集包含522611个句子,281270个实体对,18252个关系事实。测试集中包含172448个句子,96678个实体对和1950个关系事实。数据集包含53种关系,这53种关系中包含NA关系,即给定的实体对和句子之间没有任何关系的话,判定两者关系为NA关系。 按照惯例,一般报告精确度@N,即(抽取实例的top 100,top200,top300精确度),以及precision-recall曲线。
5 评价
5.1 Precision-recall
这里先解释一下,准确率(precision)是指模型判定的所有样本中有多少是真正的样本;召回率是指所有正样本有多少被模型判定为正。我们举一个例子来更形象的说明。某池塘里有1400条鲤鱼、300只虾、300只乌龟,现在以捕鲤鱼为目的,撒一大网,逮到700条鲤鱼。200只虾、200只乌龟。那么分别计算其准确率和召回率:
Precision = 700 / (700 + 200 + 200) = 70 %
Recall = 700 / 1400 = 50 %
我们试着将池塘里的所有鲤鱼、虾。乌龟全部一网打尽,看看准确率和召回率有什么变化:
Precision = 1400 / (1400 + 300 + 300) = 70 %
Recall = 1400 / 1400 = 100 %
通过上面的例子相信大家对准确率和召回率有了一定的理解,在远程监督的关系抽取任务当中,都是通过Precision-Recall曲线来反应模型性能的好坏。注意,由于在远程监督的过程中加入了多示例学习的原因,我们的数据都被打包成包级别的,通过提取包的特征进行分类,所以,这里的Precision-Recall曲线也是包级别的准确率和召回率的曲线,如下图所示:

Held-out Evaluation:
保留法提供了一种精确的度量,而不需要昂贵的人工评估。一般有Freebase中的关系结果用于测试。在远程监督关系抽取任务上,保留法测试部分先是对测试集进行包的划分,这里和训练集划分是相同的,即把所有或者部分具有相同实体且相同关系的文本打包,然后投入到模型中,得到类别的划分,自动与Freebase中的实例进行比较。也就是说在测试集中,注意分类某个包类别为:(“Steve Jobs”,”/busuness/company/founders”,”Apple”),那么如果在Freebase里面有这个关系事实即表示分类正确,然后统计整体的准确率和召回率,如图3所示。
5.2 P@N
保留法所提供的是在包级别的Precision-recall曲线,只能说明的是模型在包级别的分类性能的好坏。而远程监督关系抽取是为了得到正确的训练数据,所以仅就保留法提出的评价不足以说明提取出的数据的质量是好是坏。为了说明这些,又引入了人工评判的方法。
Manual Evaluation:
在远程监督关系抽取任务上,最终的到的是每一个文本以及所对应关系的分数,即(Text,Entity1,Entity2,Relation,Score)这些数据是以包的方式存储的。在看论文的实验结果中会看到这样的表格:

表格中的Top100是指在所有文本的得分中选取前100得分高的文本作为数据集,进行人工评判,同理,Top200,Top500就是选取前200、前500得分高的文本进行人工评判,表格中的数字指的仅仅是准确率。也正是由于人工评判比较昂贵,所以,选取的文本数量不是很多的去人工评判。
以上是笔者对远程监督(远距离监督)的学习总结,在相关工作和方法概述那部分还有很多的论文要看,笔者边看边加进去。希望对大家有所帮助,也希望学习远程监督挂你抽取的朋友多多私信交流。















 5082
5082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









