







《Downstream Model Design of Pre-trained language Model for Relation Extraction》该论文是华为在2020自然语言处理顶会ACL上发表的一片文章。论文所提出的REDN模型在SemEval 2010 task 8、NYT以及WebNLG上完成SOTA结果。个人认为该篇论文的创新点还是比较好的,构思非常的巧妙。
目录
1 背景
基于神经网络有监督的关系抽取在一定程度上取得了成功。然而,由于复杂关系的存在,它们没有能达到一个良好的水平。这里所说的复杂关系是指:1.远距离的长尾关系; 2.单个句子中有多种关系; 3.实体重叠共享关系(SEO、EPO);另外,预训练语言模型(PLMS)在多种任务上通过finetune得到了很好的结果。但是,关系抽取并不是其定义的标准任务。预训练语言模型一定可以用在关系抽取任务当中,但有必要设计下游任务,甚至是损失函数来处理复杂关系。现如今用神经网络做关系抽取的方法总结如下:
- 从编码器获取文本的嵌入式表示向量。例如Glove、Word2Vec、Bert等等;
- 利用神经网络进一步处理文本嵌入的特征,得到新的向量表示;
- 根据新的向量表示,利用softmax等等的分类器进行分类训练;
这种方法由于上文提到的复杂关系的存在,没有达到很好的效果。最近基于transformers预训练模型的出现,为该问题提供了新的解决思路。通过大量的网络进行自监督训练其初始化参数,然后结合多个下游任务微调来修复特殊任务的方法。然而关系抽取不在其定义的下游任务当中。该篇论文所解决的问题就是:
- 利用基于transformers的预训练语言模型BERT做关系抽取任务。并且将上下文信息添加到实体向量表示中,以处理远距离的关系问题;
- 计算多个核(非对称信息)。不同的核矩阵可能存在不同的信息。有助于同实体对的多重关系;
- 使用Sigmoid分类来代替softmax,该机制考虑的是实体重叠问题。并且使用每一实体对向量的平均概率作为关系分类的最终分数。这种机制允许在重叠实体上预测多个关系;
- 提出了新的损失函数,解决该范式优化问题;
Note:这里大家可能对上面的复杂关系有些不理解,在这里做一个样例补充!!
远距离长尾关系:这个理解比较简单,就是在一个很长的句子中提取一个关系,通常长的句子的特征提取是比较困难的;
单句子中多关系:这种情况就是在一句话中存在两个或两个以上实体,他们之间有多种关系;
实体重叠共享关系:这里还是要重点说一下该关系,其包括SEO和EPO,如下图所示:

所谓EPO就是指同一实体对共享多种关系,在上图中,‘Quentin Tarantino’与‘Django Unchained’同时共享‘Act_in’和‘Direct_movie’这两个关系;而SEO就是单个实体与其他不同的实体共享多个关系,例如‘Wasington’即是‘USA’的‘Capital_of’又是‘Jackie R.Brown’的‘Birth_place’。
2 与其他工作的对比
这里分别与基于CNN、基于GNN、基于Pre-trained的方法分别进行对比:
-
CNN-Based:CNN只能捕获局部的信息,对于上文提到的长距离的关系分类效果做的不是很显著;
-
GNN-Basd:首先GNN的输入一般为句子的依存句法分析树,可能会存在由于pipeline所带来的错误传递。另外紧就语法层面是一些浅层的信息,不能有效的表达词与词之间的关系;
-
Pre-trained Language Model:这种发法取得了一定的成功,但是没有充分利用语言模型信息,把句子表示成一维向量而不是一个矩阵,用矩阵的向量表示信息应该更加丰富;
3 方法
论文所提出的方法这里分两个部分来介绍,一个网络结构,二是损失函数。论文提出的方法架构如下图所示:

图中有很多符号,这里进行符号说明:
| 符号 | 意义 |
| 每个单词的Embedding表示 | |
| 全文表示的嵌入即[cls]的词嵌入 | |
| 关系 |
损失函数部分,首次用Sigmoid激活函数,通过计算,利用实体掩码来构造矩阵M,用它来保存句子中实体对的信息。根据每个实体对是否是第
个关系的实例标签,使用
每个实体区域的平均值来计算其二进制交叉上(Binary Cross Entropy)损失。其总损失为所有关系的损失和。(此处不懂没关系,后面有详细说明<-. ->)
3.1 编码器
利用Bert的倒数第二层初始化词嵌入,通过一个transformer层得到句子表示
,公式表示为:
这里;为了更好的捕获全文信息,讲CLS的向量加入到
中,得到向量
:
3.2 关系计算层
利用非对称核内积方法计算和
之间的相似性:
这里注意:,其中,
,
。
即可以视为每个单词在关系
上的概率分数,即
位置元素(m,n)表示两个位置的单词之间存在第
种关系的可能性。最后,使用Sigmoid函数将
归一化到(0,1)之间。
3.3 损失函数
的一个问题是它描述的是单词之间的关系,而不是实体之间的关系,所以使用实体掩码矩阵来解决这个问题。对于每个实体对位置信息已经知道。假设文本中所以实体对集合:
;假设
为实体
的其实位置,因此,构造了一个掩码矩阵
。数学表示如下:

类似的,我们可以构造label矩阵,:
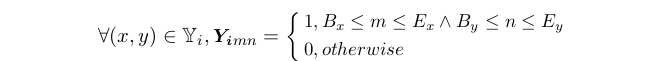
这里的实体掩码实际上就是将不是实体的单词盖住,保留实体的单词,例如下图所示:
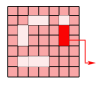
上图所示,表示的第个关系矩阵,粉色部分就是被实体掩码遮住的部分,白色的部分即是实体的位置。而红色代表的是横向和纵向实体有第
种关系。 这样以来就可以计算第
关系的损失函数:
注意这里:
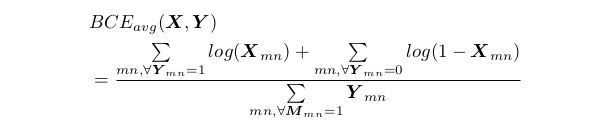
总的损失函数为:
个人拙见:
该篇论文在基于预训练模型BERT下,finetune了关系抽取任务,利用transformers的倒数第二层和最后一层的隐藏层信息,采用和以往一维特征不同的二维矩阵表示特征。并且设计了新的损失函数来优化该范式的参数。在SemEval 2010 task 8、NYT、以及WebNLG数据集上得到了SOTA结果。本人的自己的一些想法,该论文还是创新点十足的,但是论文需要有多少关系,就要有多少个关系矩阵,个人认为在时间上造成了一定的负担,在内存上也产生了一定的负担。是一种以空间和时间换效率的方法。但是利用矩阵信息来做分类,改善实体重叠的问题非常值得借鉴。与吉林大学今年新发表的ACL论文《A Novel Cascade Binary Tagging Framework for Relational Triple Extraction》改善实体重叠问题上,有一定的相似的想法,但是做法不同!!(仅个人观点,大佬勿喷!!)。
论文链接:Downstream Model Design of Pre-trained Language Model for Relation Extraction Task
github链接:REDN Model Code















 2753
2753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









