







转载链接:如有侵权,立马删除初探NMS非极大值抑制 (qq.com)![]() https://mp.weixin.qq.com/s/rdYyGEUjykyEUeKF6lTopw
https://mp.weixin.qq.com/s/rdYyGEUjykyEUeKF6lTopw
1 标准的NMS
非极大值抑制(Non-maximum supression)简称NMS,其作用是去除冗余的检测框,去冗余手段是剔除与极大值重叠较多的检测框结果。 通常我们所说的NMS指的是标准NMS。那么为什么一定要去冗余呢?因为图像中的目标是多种多样的形状、大小和长宽比,目标检测算法中为了更好的保障目标的召回率,通常会使用SelectiveSearch、RPN(例如:Faster-RCNN)、Anchor(例如:YOLO)等方式生成长宽不同、数量较多的候选边界框(BBOX)。因此在算法预测生成这些边界框后,紧接着需要跟着一个NMS后处理算法,进行去冗余操作,为每一个目标输出相对最佳的边界框,依次作为该目标最终检测结果。
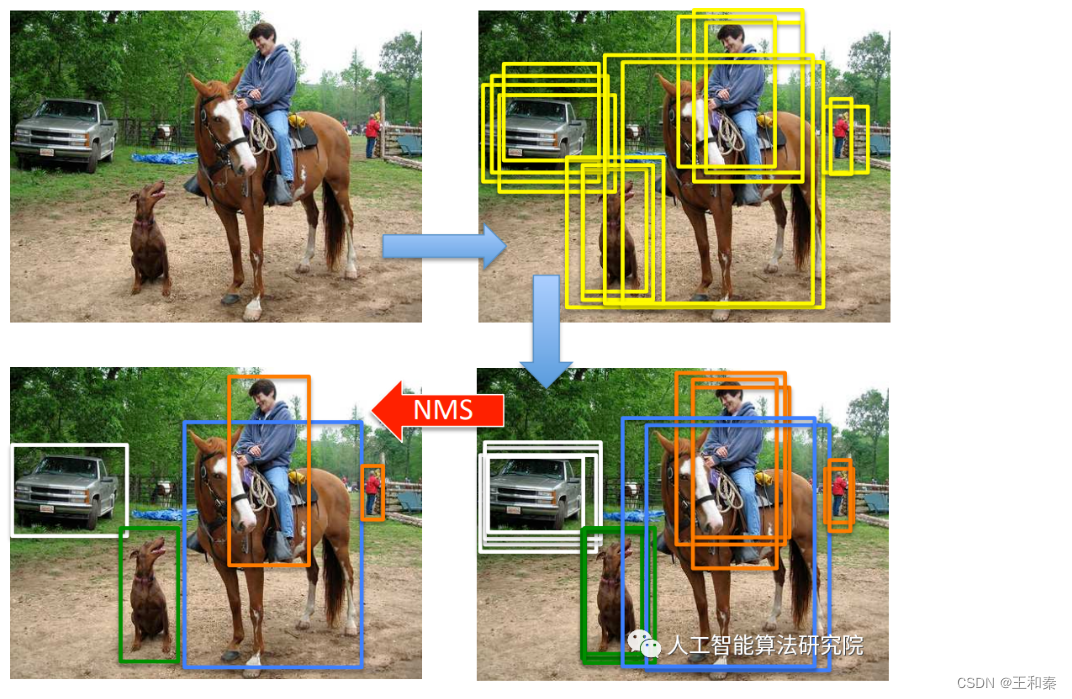
核心思想:是搜索目标局部范围内的边界框置信度最大的这个最优值,去除目标邻域内的冗余边界框。
一般NMS后处理算法需要经历以下步骤(不含背景类,背景类无需NMS):
step1:先将所有的边界框按照类别进行区分;
step2:把每个类别中的边界框,按照置信度从高到低进行降序排列;
step3:选择某类别所有边界框中置信度最高的边界框bbox1,然后从该类别的所有边界框列表中将该置信度最高的边界框bbox1移除并同时添加到输出列表中;
step4:依次计算该bbox1和该类别边界框列表中剩余的bbox计算IOU;
step5:将IOU与NMS预设阈值Thre进行比较,若某bbox与bbox1的IOU大于Thre,即视为bbox1的“邻域”,则在该类别边界框列表中移除该bbox,即去除冗余边界框;
step6:重复step3~step5,直至该类别的所有边界框列表为空,此时即为完成了一个物体类别的遍历;
step7:重复step2~step6,依次完成所有物体类别的NMS后处理过程;
step8:输出列表即为想要输出的检测框,NMS流程结束。

实现代码:
def nms(dets, thresh):
"""
dets:指的是某个类的多组边界框,每组边界框信息均是一个5维数组,分别为x_max、x_min、y_max、y_min以及置信度score
例如:dets为[[x1,y1,x2,y2,score],[x1,y1,y2,score]……]]
thresh:是设置的IoU的阈值。IOU(Intersection over Union), 指的是两个边界框的交并比。
"""
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1) #每一个检测框的面积
order = scores.argsort()[::-1] #按照score置信度降序排序
keep = [] #保留的结果框集合
while order.size > 0:
#每次筛选一组框,依次选择置信度最高的框作为种子框,与未被筛选的框分别计算IOU
i = order[0]
keep.append(i) #保留该类剩余box中得分最高的一个边界框
#获取相交区域,左上及右下
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
#计算相交的面积,注意不重叠时面积为0
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
#计算IoU
ovr = inter / (areas[i] + areas[order[1:]] - inter) # 重叠面积 /(面积1+面积2-重叠面积)
#保留IoU小于阈值的box
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1] #因为ovr数组的长度比order数组少一个,所以这里要将所有下标后移一位
return keep优势:该算法可以找到绝大部分情况下物体的最佳检测框。
不足:存在以下缺陷
(1) NMS的预设阈值需要手动设置,nms实际效果容易受nms预设阈值影响。nms预设阈值的调整直接会影响边界框的抑制效果,稠密场景易漏检。预设阈值太大抑制效果差,会造成误检,太小时邻近边界框容易被抑制掉。如下图所示,红框和绿框存在较大的重叠,若预设阈值太小时,绿框会被红框抑制掉。

(2)直接把跟置信度得分最大的bbox的IOU大于预设阈值直接置为零的方式太过简单粗暴,即太过hard(因此该nms方式也可以认为是hard_nms);
(3)评价方式不是特别的完全合理。盲目认为得分最大的边界框就是定位最为准确的框,实际场景可能会出现得分最大的边界框未必是最准确的情况。此外,IOU的评价方式中边界框的尺度、距离的影响并不相同。
那么能否通过衰减IOU的大小的方式来抑制邻近边界框吗?鉴于此,Soft NMS诞生。
2 soft-nms
在介绍标准NMS时,我们发现在预设的NMS阈值过小时,如下图所示,较低置信度的绿色边界框会被抑制,导致只检测出红色检测框中的目标,降低了检测算法的召回率;而过大值,由于抑制效果弱,易引入误检。因此,soft nms便适时出现了。
思路:
使用更平滑的方式去替代标准nms中简单粗暴的做法,即:不直接删除IOU大于预设阈值的框,而是降低这些边界框的置信度。
对于同一个物体附近的多个框,每次选择置信度分数最高的框,抑制邻近的框其他。使得与置信度分数最高的框的IOU越大的框,较大程度上的被抑制。一般而言表示同一个物体的邻近框的IOU比较大,而非不是同一类别的IOU相对较小,通过这样的抑制作用,保留下不同类别的物体的框而抑制掉同一物体的框。
实现方式:
和标准NMS类似,只不过在step5中,当IOU大于预设的NMS阈值时,将其得分调低,替代之前的直接进行删除的方式。
原始NMS函数:
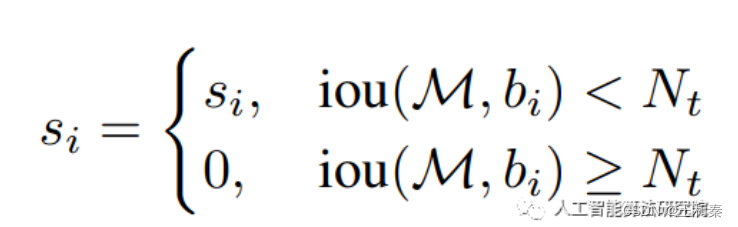
修改后的soft nms为线性函数:
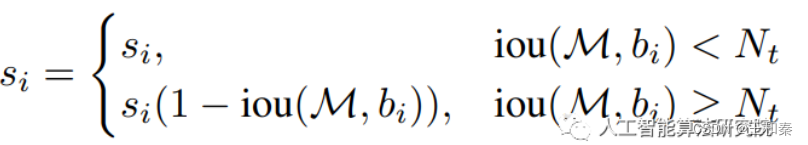
由于上式是一个不连续函数,无法直接进行求导,因此作者将上式改为高斯函数:
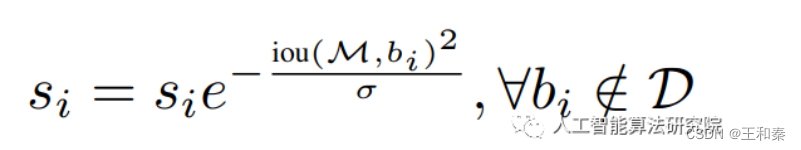
高斯函数下,越接近于高斯分布中心的惩罚力度越大。

代码实现:
def soft_nms(boxes, thresh=0.35, sigma2=0.5, score_thresh=0.3, method=2):
"""
:param boxes:
:param thresh:IOU阈值
:param sigma2: 高斯中用到的sigma
:param score_thresh: 置信概率分数阈值
:param method: soft-nms对应1或者2,传统nms对应0
:return: 最终保留的boxes的索引号
"""
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
areas = (y2 - y1 + 1) * (x2 - x1 + 1)
scores = boxes[:, 4]
#keep 存放保留的数据
keep = []
keep_scores = []
#几个框的索引
N = boxes.shape[0]
indexs = [i for i in np.arange(0,len(x1),1)]
pos = np.argmax(scores, axis=0)
pos_score = np.max(scores, axis=0)
keep.append(pos)
keep_scores.append(pos_score)
for i in range(N):
#将b = index-keep中的所有检测框与pos进行iou计算,大于阈值的重新赋值分数
b = list(set(indexs).difference(set(keep)))
# 计算交集的左上角和右下角
# 比较大小,留下 x1 y1 x2 y2 中比较大的那个值
x11 = np.maximum(x1[pos], x1[b]) # calculate the points of overlap
y11 = np.maximum(y1[pos], y1[b])
x22 = np.minimum(x2[pos], x2[b])
y22 = np.minimum(y2[pos], y2[b])
#如果两个方框相交,x22-x11, y22-y11是正的
#如果两个方框不相交,x22-x11,y22-y11是负的,将不相交的w和h设为0
w = np.maximum(0,x22-x11+ 1)
h = np.maximum(0,y22-y11+ 1)
# 计算重叠面积
overlaps = w * h
# IOU公式,(交集/并集)
# ious是一个列表,当前方框和其他所有方框的iou结果
ious = overlaps / (areas[pos] + areas[b] - overlaps)
# 大于阈值的重新赋值分数
weight = np.ones(ious.shape)
# Three methods: 1.linear 2.gaussian 3.original NMS
if method ==1:
weight[ious>thresh] = weight[ious>thresh] - ious[ious>thresh]
elif method == 2:
weight[ious > thresh]= np.exp(-((ious[ious>thresh]) * (ious[ious>thresh])) / sigma2)
else:
weight[ious > thresh] = 0
scores[b] = weight*scores[b]
# 将b = index-keep中的所有检测框与pos进行iou计算,大于阈值的重新赋值分数
#找出除了keep外的最大score极其下标
#pos 为基准
if i != (N-1):
b_scores = list(set(scores).difference(set(keep_scores)))
#如果全为0则不再继续循环
if np.any(b_scores)==0:
break
pos_score = np.max(b_scores, axis=0)
pos = list(scores).index(pos_score)
else:
break
keep.append(pos)
keep_scores.append(pos_score)
#score约束
keep_scores = np.array(keep_scores)
keep = np.array(keep)
indx = keep[(keep_scores>=score_thresh)]
return indx优势:相较于标准NMS,处理过程较为平滑,可以减少邻近物体的误检,提升召回率,缓解重叠目标的漏检。
不足:仍需手工选取阈值;而且还可能会带来时间开销的增加;非密集物体场景,未必有明显效果。
3 softer NMS
对于NMS而言,一般会存在下面问题:
(1)密集物体场景易漏检;
(2)边界框的置信度分数和物体的定位准确性并不是强相关的关系。可能会出现框更准但置信度低的边界框被其他置信度高但定位不准的边界框给一直掉。
(3)标注框不一定准确。
如下图所示,左图中两个边界框均不精确,右图中定位精度高的边界框的置信度分数低。

soft nms仅缓解了问题1,那么当所有边界框位置精度不够精确时怎么选择?当得分高的边界框不准确而准确的框置信度分数低时如何选择? 为了解决这些问题,softer nms诞生。
思路:在soft nms的基础上,提出KL loss(可同时学习 bounding box transformation和localization confidence),引入定位的方差投票来进行位置修正,本质是对预测的检测框加权求平均。即:Softer NMS = soft NMS + variance voting
具体步骤:
网络结构:直接摘回归分支上预测边界框的不确定度。
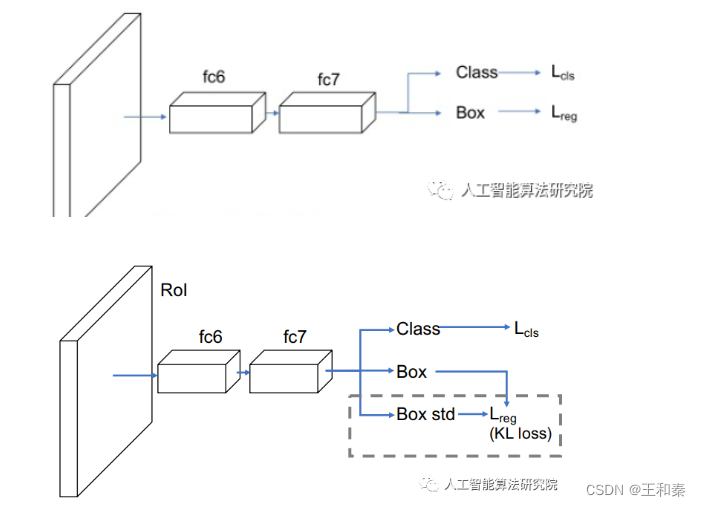
将预测框和gt框分别建模为Gaussian distribution、Dirac delta function; 然后,通过最小化KL loss(上述两个分布的KL散度)训练网络; 最后,在soft NMS过程中,用不确定性网络预测到的标准差对候选框进行加权平均。

实现代码:
def softer_nms(dets, confidence=None, ax = None):
thresh = cfg.STD_TH #.6
score_thresh = .7
sigma = .5
N = len(dets)
x1 = dets[:, 0].copy()
y1 = dets[:, 1].copy()
x2 = dets[:, 2].copy()
y2 = dets[:, 3].copy()
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
ious = np.zeros((N,N))
for i in range(N):
xx1 = np.maximum(x1[i], x1)
yy1 = np.maximum(y1[i], y1)
xx2 = np.minimum(x2[i], x2)
yy2 = np.minimum(y2[i], y2)
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas - inter)
ious[i,:] = ovr
i = 0
while i < N:
maxpos = dets[i:N, 4].argmax()
maxpos += i
dets[[maxpos,i]] = dets[[i,maxpos]]
areas[[maxpos,i]] = areas[[i,maxpos]]
confidence[[maxpos,i]] = confidence[[i,maxpos]]
ious[[maxpos,i]] = ious[[i,maxpos]]
ious[:,[maxpos,i]] = ious[:,[i,maxpos]]
ovr_bbox = np.where((ious[i, :N] > thresh))[0]
avg_std_bbox = (dets[ovr_bbox, :4] / confidence[ovr_bbox]).sum(0) / (1/confidence[ovr_bbox]).sum(0)
if cfg.STD_NMS:
dets[i,:4] = avg_std_bbox
else:
assert(False)
areai = areas[i]
pos = i + 1
while pos < N:
if ious[i , pos] > 0:
ovr = ious[i , pos]
dets[pos, 4] *= np.exp(-(ovr * ovr)/sigma)
if dets[pos, 4] < 0.001:
dets[[pos, N-1]] = dets[[N-1, pos]]
areas[[pos, N-1]] = areas[[N-1, pos]]
confidence[[pos, N-1]] = confidence[[N-1, pos]]
ious[[pos, N-1]] = ious[[N-1, pos]]
ious[:,[pos, N-1]] = ious[:,[N-1, pos]]
N -= 1
pos -= 1
pos += 1
i += 1
keep=[i for i in range(N)]
return dets[keep], keep优缺点分析:
1、个人认为论文提出的KL loss就是曼哈顿距离,但是通过KL散度去证明,让数学不太好的同学不明觉厉。
2、论文提出的Softer-NMS,本质是对预测的检测框加权求平均,为什么要这样,以及为什么让box高度重叠?个人认为Softer-NMS的理论没有在应该什么的地方深入。
4 DIOU NMS
在经典NMS中,得分最高的检测框和其它检测框逐一算出一个对应的IOU,然后将该值与NMS threshold作比较,将超过该阈值的框全部过滤掉。在执行标准的NMS的时候,会遇见下面的问题:
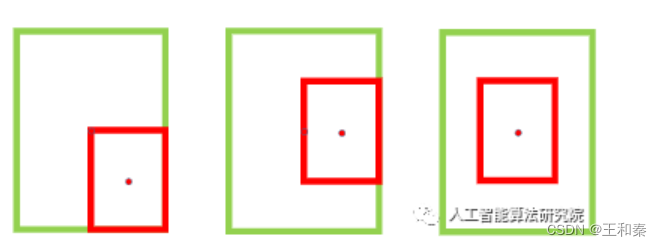
也就是,两个检测框挨得很近或完全重叠,此时再使用普通IOU做nms,便无法区分上面三种情况下好坏,那么该怎么办呢?
思路:
我们先做这样一个假设,若两个检测框的中心越接近,那么是相同物体的概率越大,即:越有可能存在冗余的检测框。
基于上述假设,引入了DIOU作为NMS的评判指标。如下所示:
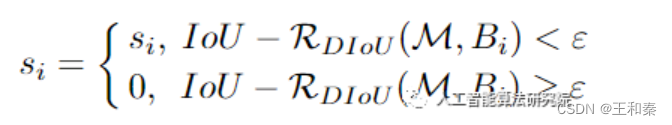
上式中,M表示高置信度候选框,Bi表示遍历各个框和置信度高的框的重合情况。
其中:
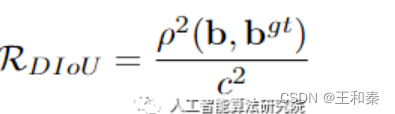
上式中,字母含义如下:
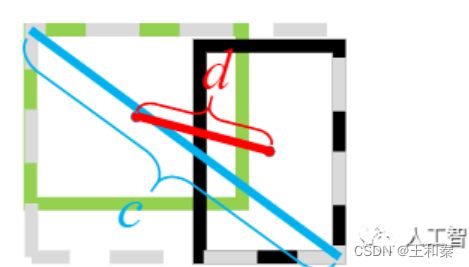
c表示两个检测框的最远对角线距离,d表示两个检测框中心点的距离。
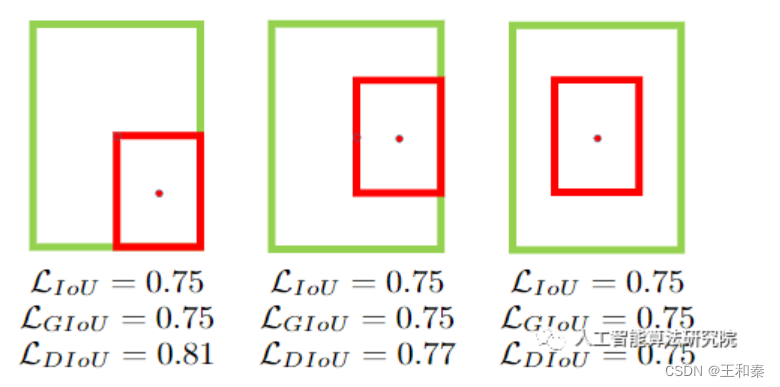
引入DIOU后,我们发现在IOU和GIOU已经无法五分区分好坏情况下,DIOU依然具有较好的区分能力。如下图所示:

实现代码:
def DIOUnms(bboxes, scores, threshold=0.2, top_k=200): #bboxes维度为[N,4],scores维度为[N,],均为tensor
#获得每一个框的左上角和右下角坐标
x1 = bboxes[:, 0]
y1 = bboxes[:, 1]
x2 = bboxes[:, 2]
y2 = bboxes[:, 3]
center_x=x2-x1/2.0
center_y=y2-y1/2.0
#获得每个框的面积
areas=(x2-x1)*(y2-y1)
#按降序排列
_,order=scores.sort(0,descending=True)
#取前top_k个
order=order[:top_k]
keep=[]
count=0
while order.numel()>0:
if order.numel()==1:
break
count += 1
# print(order)
i=order[0]
keep.append(i)
#[N-1,]
xx1=x1[order[1:]].clamp(min=x1[i].item())
yy1=y1[order[1:]].clamp(min=y1[i].item())
xx2=x2[order[1:]].clamp(max=x2[i].item())
yy2=y2[order[1:]].clamp(max=y2[i].item())
w=(xx2-xx1).clamp(min=0)
h=(yy2-yy1).clamp(min=0)
#相交的面积 [N-1,]
inter=w*h
#计算IOU [N-1,]
overlap=inter/(areas[i]+areas[order[1:]]-inter)
# DIOU计算
xxx1=list()
xxx2=list()
yyy1=list()
yyy2=list()
for j in range(len(np.array(xx1))):
xxx1.append(min(x1[order[j+1]].item(), x1[i].item()))
xxx2.append(min(x2[order[j+1]].item(), x2[i].item()))
yyy1.append(max(y1[order[j+1]].item(), y1[i].item()))
yyy2.append(max(y2[order[j+1]].item(), y2[i].item()))
xxx1 = torch.Tensor(xxx1).clamp(min=0)
xxx2 = torch.Tensor(xxx2).clamp(min=0)
yyy1 = torch.Tensor(yyy1)
yyy2 = torch.Tensor(yyy2)
CDistance=torch.pow(xxx2-xxx1,2)+torch.pow(yyy2-yyy1,2)
DDistance=torch.pow(center_x[i]-center_x[order[1:]],2)+torch.pow(center_y[i]-center_y[order[1:]],2)
overlap=overlap-DDistance/CDistance
#返回一个包含输入 input 中非零元素索引的张量.输出张量中的每行包含 input 中非零元素的索引
ids=(overlap<=threshold).nonzero().squeeze()
if ids.numel()==0:
break
#ids中索引为0的值在order中实际为1,后面所有的元素也一样,新的order是经过了一轮计算后留下来的bbox的索引
order=order[ids+1]
return torch.tensor(keep,dtype=torch.long),count效果:
使用DIOU-NMS后,无论是在YOLOV3上还是在SSD上,与原始NMS相比,均获得了一定的性能提升。
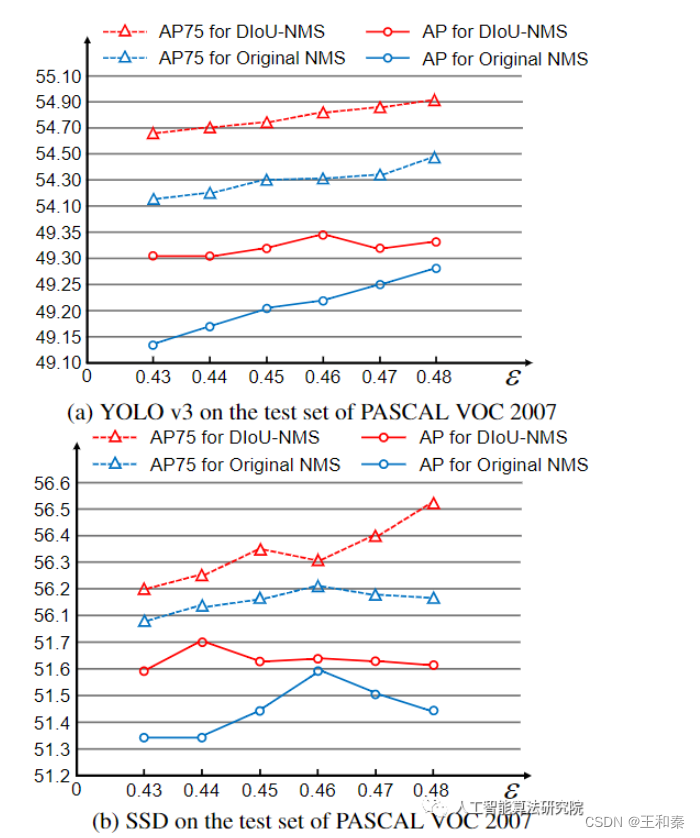
下图中,左侧是NMS结果,右侧是DIOU-NMS结果:

优势:1)通过结合检测框中心点距离的方式,提升了相同物体遮挡情况下的检出性能,降低了漏检。
2)该方式是对IOU的优化,有助于更快和更好的学习检测框信息。
不足:1)带来了一定的计算量,比IOU要复杂,耗时增加;
2)与标准的NMS相比,每一轮迭代后,保留的框增加,运算效率有所降低。
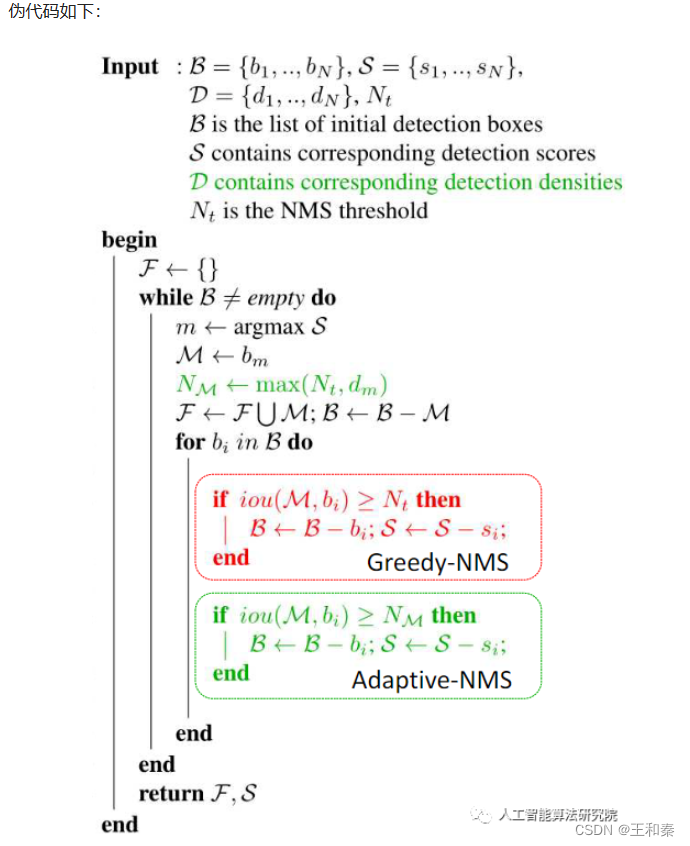
5 Adaptive NMS
在经典NMS中,得分最高的检测框和其它检测框逐一算出一个对应的IOU,然后将该值与NMS threshold作比较,将超过该阈值的框全部过滤掉。在执行标准的NMS的时候,当物体或行人较稠密时,会遇见下面的问题(图中蓝框表示漏检的行人框,红框表示误检的行人框):

思路:
由于统一采用一个NMS过滤阈值不合理,因此提出一种自适应的方式去调节非极大值过滤阈值的大小。当物体密集分布时,NMS阈值采用大的过滤阈值,以便增加召回率,当物体分布稀疏时,采用较小的过滤阈值,以便删除冗余的检测框。可适用于单阶段和双阶段检测器。
那么如何判断物体或人群的密级程度呢?具体来说是添加了一个密度预测模块,用于学习一个框的密度大小。例如:第i个物体处的密度如下:
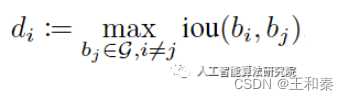
引入密度之后,便将NMS改进为如下的方式:
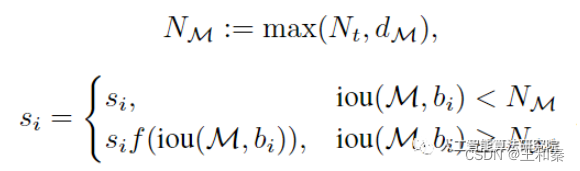
其中,Nm表示adptive-NMS中M的抑制阈值,dM是M的目标密度。
文中将密度预测视为一个回归任务,密度的值采用上述定义的计算公式,损失函数采用Smooth-L1 loss。在训练CNN时,每次还需要求出密度作为监督信号,训练网络能够拟合这个密度函数,即输入一张图片,能输出每个位置的物体密度。与soft nms相比,adptive-NMS多了一步目标密度的预测步骤,文中是通过设计一个Density-subnet对目标密度进行回归预测的,如下图:
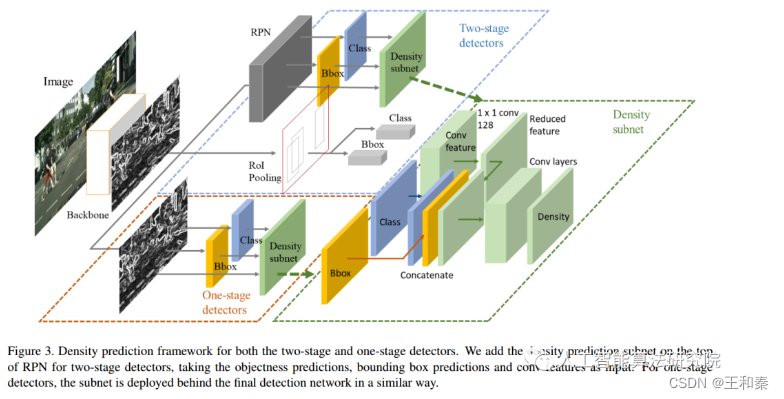
实现效果:

优势:对遮挡情况的检测性能有所提升。
不足:添加了密度预测模块,计算开销增大。运算效率低。















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









