







目录
【原文链接】
https://www.aclweb.org/anthology/P15-1017/
【摘要】
传统的ACE事件提取方法: 主要依赖自然语言处理(NLP)工具,缺乏通用性,需要大量的人力,容易出现错误传播和数据稀疏问题
本文提出了一种新的事件提取方法: 在不使用复杂的NLP工具的情况下自动提取词汇级和句子级特征
我们引入了一个单词表示模型来捕获有意义的单词语义规则,并采用基于卷积神经网络(CNN)的框架来捕获句子级线索。 但是,CNN只能捕获句子中最重要的信息,并且在考虑多事件句子时可能会丢失有价值的事实。 我们提出了一个动态多池卷积神经网络(DMCNN),它根据事件触发词和参数使用一个动态多池层来保留更多关键信息。 实验结果表明,我们的方法明显优于其他最新方法。
1 介绍
事件抽取是信息提取(IE)中的一项重要且具有挑战性的任务,旨在发现具有特定类型及其参数的事件触发器。目前最先进的方法(Li et al,2014; Li et al,2013; Hong et al,2011; Liao and Grishman,2010; Ji and Grishman,2008)经常使用一组精心设计的特征,通过文本分析和语言知识提取。一般来说,我们可以将这些特征分为两类:词汇特征和语境特征。词汇特征一般包含词性标签(POS),实体信息和形态特征,目的是捕获语义或单词的背景知识。例如,下面这两个例子中就有一个含糊不清的单词beats:
S1: Obama beats McCain.
S2: Tyson beats his opponent.
在第一句话中,beats是一个Elect类型的触发词,而在第二句话中,beats是一个Attack类型的触发词,由于这是同一个单词,所以传统的方法可能会将第一句话中的beats错误的标成Attack类型的触发词。如果我们知道奥巴马和麦凯恩都是总统竞选人,就可以预测beats是Elect类型的触发词。我们把这些知识称为词汇层面的线索。为了表示这些特征,现有的方法(Hong et al,2011)经常依赖于人工标注,这是一个耗时的过程,且缺乏通用性。此外,先前方法中的传统词汇特征是one-hot表示,其可能遭受数据稀疏性问题并且可能无法充分捕获单词的语义(Turian et al,2010)。

图1 事件提及S3的语法分析器结果。 上方显示了两个事件提及,它们共享三个参数:Die事件提及,由“died”触发,而Attack事件提及由“fired”触发。 下方显示折叠的依赖性结果。
S3: In Baghdad, a cameraman died when an American tank fired on the Palestine Hotel.
为了更准确地识别事件和参数,以前的方法通常会捕获上下文特征,例如句法特征,其目的是从更大的视角了解事实如何联系在一起。 例如,在S3中,有两个共享三个参数的事件,如图1所示。从参数cameraman和触发词die之间的nsubj依赖关系,我们可以在Die事件中向摄影师添加受害者角色。 我们称这种信息为句子级的线索。 但是,参数cameraman及其触发的单词在不同的子句中,并且它们之间没有直接的依赖路径。 因此,使用传统的依赖功能很难在它们之间找到目标角色。 此外,提取此类特征在很大程度上取决于现有的NLP系统的性能,而NLP系统可能会遭受错误传播。
要正确地将cameraman识别为fired的Target参数,我们必须利用整个句子的内部语义,以便使得Attack事件可以导致Die事件。对卷积神经网络(CNN)的改进已被证明对于捕获NLP任务的句子内的单词之间的句法和语义是有效的。CNN通常使用最大池化层,其对整个句子的表示应用最大操作以捕获最有用的信息。
但是,在事件提取中,一个句子可能包含两个或多个事件,并且这些事件可能共享具有不同角色的参数。传统的CNN只使用最重要的信息表示句子,将会错过有价值的线索。
例如,S3中有两个事件,Die事件和Attack事件。如果我们使用传统的最大汇集层并且只保留最重要的信息来表示句子,我们可能会获得描述“摄影师死亡”的信息但却错过了“美国坦克向巴勒斯坦酒店开火”的信息,这对于预测攻击事件具有重要意义,对于将cameraman识别为fired的Target参数也很有价值。在我们的实验中,我们发现这样的多事件句占我们数据集的27.3%,这是一个我们不能忽视的现象。
所以,本文提出动态多池化卷积神经网络(DMCNN)来解决上述问题。为了捕捉词汇层面的线索并减少人为干预,我们引入了一个单词表示模型(Mikolov et al,2013b),它已经被证明能够捕获单词的有意义的语义规律(Bengio et al,2003; Erhan et al,2010; Mikolov et al,2013a)。为了在不使用复杂的NLP工具的情况下捕获句子级线索,并更全面地保留信息,我们为CNN设计了动态多池层,它根据事件触发器和参数返回句子每个部分的最大值。本文的贡献如下:
- 我们提出了一种新的事件提取框架,它可以自动从纯文本中引入词汇级和句子级特征,而无需复杂的NLP预处理。
- 我们设计了一个动态多池卷积神经网络(DMCNN),旨在捕获句子中更有价值的信息以进行事件提取。
- 我们对广泛使用的ACE2005事件提取数据集进行了实验,实验结果表明我们的方法优于其他最先进的方法。
2 事件抽取任务
在本文中,我们关注自动内容提取(ACE)评估中定义的事件提取任务,其中事件被定义为涉及参与者的特定事件。
- 事件提及:描述事件的短语或句子,包括触发词和参数。
- 事件触发词:最清楚地表达事件发生的主要单词(ACE事件触发词通常是一个动词或名词)。
- 事件参数:与事件(即参与者)相关的实体提及、时间表达或价值(如职位名称)。
- 参数角色:参数与它所参与的事件之间的关系。
3 方法
事件抽取分为两个阶段,触发词分类和参数分类
如果一个句子有触发词,则进行第二阶段,即应用类似的DMCNN来为触发词分配参数并调整参数的角色。
触发词分类是通过DMCNN对一句话中的每个单词进行分类识别出哪个词是触发词,到第二阶段,它应用类似的DMCNN为触发词分配参数并对齐参数的角色。因为第二阶段更复杂,所以这里先讲第二阶段。

图2 事件提取中参数分类阶段的体系结构。它演示了一个实例的处理,其中有一个实例使用了预测值触发词和候选参数摄像师。
图2描述了参数分类的体系结构,它主要分四个部分:
(i)词嵌入学习,这里是以无监督的方式显示单词的嵌入向量;
(ii)词汇级特征表示,直接使用词的嵌入向量来捕获词汇线索;
(iii)句子级特征提取,提出DMCNN来学习句子的组成语义特征;
(iv)参数分类器输出,它计算每个参数角色候选者的置信度分数。
3.1 词嵌入学习和词汇级特征表示
词汇级特征是事件提取的重要线索。传统的词汇级特征主要包括候选词的引理、 同义词和POS标签。
这些特征的质量很大程度上取决于现有NLP工具的结果和人类的聪明才智。另外,传统特征仍然不能令人满意地捕获单词的语义,这在事件提取中很重要,如S1和S2所示。Erhan et al(2010)指出,从大量未标记数据中学习到的词嵌入在获取有意义的词汇语义规则方面更加强大。本文使用无监督的预训练词嵌入作为基本特征的来源。我们选择候选词的嵌入(候选触发,候选参数)和上下文标记(候选词的左和右标记)。然后,所有这些单词嵌入被连接到词汇级特征向量L中,以表示参数分类中的词汇级特征。
使用Skip-gram模型预先训练单词嵌入,Skip-gram模型通过最大化平均对数概率来训练单词
w
1
,
w
2
.
.
.
w
m
w_1,w_2...w_m
w1,w2...wm的嵌入,
1
m
∑
t
=
1
m
∑
−
c
≤
j
≤
c
l
o
g
p
(
w
t
+
j
∣
w
t
)
(1)
\frac{1}{m}\sum_{t=1}^{m}\sum_{-c \le j \le c}logp(w_{t+j}|w_t) \tag{1}
m1t=1∑m−c≤j≤c∑logp(wt+j∣wt)(1)
【参考】Skip-gram
其中,c是训练窗口的大小(也可能是中心词
w
t
w_t
wt的一个函数),较大的c会得到更多的训练实例,因此会有更高的精度,但是会耗费更多的时间。m是未标记文本的词汇表大小。后面这个概率代表着我们的词典中的每个词是输出词的可能性(使用softmax函数定义)。
p ( w t + j ∣ w t ) = e x p ( e t + j ′ T e t ) ∑ w = 1 m e x p ( e w ′ T e t ) (2) p(w_{t+j}|w_t)=\frac{exp(e_{t+j}^{'T}e_t)}{\sum_{w=1}^{m}exp(e_w^{'T}e_t)}\tag{2} p(wt+j∣wt)=∑w=1mexp(ew′Tet)exp(et+j′Tet)(2)
其中m是未标记文本的词汇表, e i ′ e_i^{'} ei′是 e i e_i ei的另一个嵌入,详见Morin和Bengio(2005)。
3.2 使用DMCNN提取句子级别的特征
具有最大池化层的CNN是捕获句子内长距离单词语义的良好选择(Collobert et al,2011)。 但是,如第1部分所述,传统的CNN无法解决事件抽取问题。 因为句子可能包含多个事件,所以只使用最重要的信息来表示句子,就像在传统的CNN中一样,将错过有价值的线索。 为解决此问题,我们建议使用DMCNN来提取句子级特征。 DMCNN使用动态多池层来获取句子每个部分的最大值,该值由事件触发器和事件参数分割。 因此,与传统的CNN方法相比,DMCNN有望获得更有价值的线索。
3.2.1 输入
本小节说明了DMCNN提取句子级特征所需的输入。预测的触发词和参数候选之间的语义交互对于参数分类是至关重要的。因此,我们建议DMCNN使用三种类型的输入来捕捉这些重要的线索:
i. 上下文单词特征(context -word feature, CWF):类似于Kalchbrenner et al.(2014)和Collobert et al.(2011),我们把整个句子中的所有单词都当作语境。CWF是通过查找单词嵌入而转换的每个单词标记的向量。
ii. 位置特征(PF):必须指定哪些单词是参数分类中的预测触发词或候选参数。因此,我们提出了PF,它被定义为当前单词与预测的触发或候选参数的相对距离。例如,在S3中,坦克与候选参数摄影师的相对距离是5。为了编码位置特征,每个距离值也由嵌入矢量表示。与单词嵌入类似,距离值随机初始化并通过反向传播进行优化。
iii.事件类型特征(EF):当前触发词的事件类型对于参数分类很有价值(Ahn,2006; Hong et al,2011; Liao和Grishman,2010; Li et al,2013),因此,我们将触发分类阶段预测的事件类型编码为DMCNN的一个重要线索,如PF。
图2假设字嵌入的大小为 d w = 4 d_w = 4 dw=4,位置嵌入的大小为 d p = 1 d_p = 1 dp=1,事件类型嵌入的大小为 d e = 1 d_e = 1 de=1。令 x i ∈ R d {x_i ∈ R^d} xi∈Rd采用向量表示对应的第 i i i个单词句子,其中 d = d w + d p ∗ 2 + d e d = d_w + d_p * 2 + d_e d=dw+dp∗2+de,长度为n的句子表示如下:
x 1 : n = x 1 ⊕ x 2 ⊕ . . . ⊕ x n (3) x_{1:n}=x_1⊕x_2⊕...⊕x_n\tag{3} x1:n=x1⊕x2⊕...⊕xn(3)
其中⊕是连接运算符,因此,组合字嵌入、位置嵌入和事件类型嵌入可以转换实例作为一个矩阵
x
∈
R
(
n
∗
d
)
x ∈ R^{(n∗d)}
x∈R(n∗d) 。然后,
x
x
x被输入到卷积部分。
注意:此处的位置特征有两个,一个是当前单词与预测的触发或候选参数的相对距离,另一个是每个词的位置向量。
3.2.2 卷积
卷积层旨在捕获整个句子的组成语义,并将这些有价值的语义压缩成特征映射。通常,用 x i : i + j x_{i:i+j} xi:i+j表示 x i , x i + 1 , . . . , x i + j x_i,x_{i+1},...,x_{i+j} xi,xi+1,...,xi+j的级联。卷积运算涉及一个滤波器 w ∈ R h ∗ d w∈R^{h*d} w∈Rh∗d,应用于 h h h词的窗口以产生新特征。例如,通过下面的运算从 x i : i + h − 1 x_{i:i+h-1} xi:i+h−1的窗口生成特征 c i c_i ci
c i = f ( w ⋅ x i : i + h − 1 + b ) (4) c_i=f(w \cdot x_{i:i+h-1}+b)\tag{4} ci=f(w⋅xi:i+h−1+b)(4)
其中
b
∈
R
b∈R
b∈R是一个偏置项,f是非线性函数,如双曲正切。这个滤波器用于句子
x
1
:
h
,
x
2
:
h
+
1
,
.
.
.
,
x
n
−
h
+
1
:
n
x_{1:h},x_{2:h+1},...,x_{n-h+1:n}
x1:h,x2:h+1,...,xn−h+1:n的每个可能的窗口,产生一个特征
c
i
c_i
ci,
i
i
i的范围是从
1
1
1到
n
−
h
+
1
n-h+1
n−h+1。
我们已经描述了如何从一个过滤器中提取一个特征图的过程。 为了捕获不同的特征,通常在卷积中使用多个过滤器。假设我们用m个滤波器,则卷积操作就可以表示为:
c j i = f ( w j ⋅ x i : i + h − 1 + b j ) (5) c_{ji}=f(w_j \cdot x_{i:i+h-1}+b_j)\tag{5} cji=f(wj⋅xi:i+h−1+bj)(5)
其中 j j j的范围是从1到 m m m,卷积的结果是一个矩阵 C ∈ R m ∗ ( n − h + 1 ) C∈R^{m*(n-h+1)} C∈Rm∗(n−h+1)。
3.2.3 动态多池化
为了提取每个特征图中最重要的特征(最大值),传统的CNN(Collobert et al,2011; Kim,2014; Zeng et al,2014)将一个特征映射作为一个池,并且每个特征图只得到一个最大值。由于单个最大池对于事件提取来说还不够,因为在本文的任务中,一个句子可能包含两个或两个以上的事件,一个参数候选者可能在不同的触发器中扮演不同的角色。为了做出准确的预测,有必要获取与候选词的变化有关的最有价值的信息。因此,我们根据参数分类阶段中的候选参数和预测触发词将每个特征映射分成三个部分。我们保留每个拆分部分的最大值,而不是使用整个特征映射的一个最大值来表示句子,并将其称为动态多池。与传统的最大池相比,动态多池化可以在不丢失最大池化值的情况下保留更多有价值的信息。
如图2所示,特征 c j c_j cj被“cameraman”和“fired”分为三个部分 c j 1 , c j 2 , c j 3 c_{j1},c_{j2},c_{j3} cj1,cj2,cj3,动态多池化表示为公式6,其中 1 ≤ j ≤ m 1 \le j \le m 1≤j≤m 并且 1 ≤ i ≤ 3 1 \le i \le 3 1≤i≤3。
p j i = m a x ( c j i ) (6) p_{ji}=max(c_{ji})\tag{6} pji=max(cji)(6)
通过动态多池,我们获得每个特征映射的 p j i p_{ji} pji 。然后,我们将所有 p j i p_{ji} pji连接起来形成一个向量 P ∈ R 3 m P∈R^{3m} P∈R3m,它可以被认为是更高级别的特征,就是句子级特征。
注意:换句话说,对于没有动态多池化的模型来说,无论处理died这个事件还是fired这个事件,最后的结果就只有一个最大值,这时候就没办法对这两个事件进行区分,但是有了动态多池化的时候,用died和fired两个触发词进行分块后得到的每个块的词是不一样的,这样对这两个词进行池化后的结果就有区分度了,所以说动态多池化对一个句子中有多个事件时能够更好的进行抽取。在图2中只是用fired作为示例进行展示。
3.3 输出
上面提到的自动学习的词汇和句子级别特征被连接成单个向量 F = [ L , P ] F = [L,P] F=[L,P]。 为了计算每个参数角色的置信度,特征向量 F ∈ R 3 m + d l F∈R^{3m+d_l} F∈R3m+dl,其中m是特征映射的数量, d l d_l dl是词汇级特征的维度,被送到分类器中。
O = W s F + b s (7) O=W_sF+b_s\tag{7} O=WsF+bs(7)
W
s
∈
R
(
n
1
∗
(
3
m
+
d
l
)
)
W_s ∈ R^{(n_1∗(3m+ d_l))}
Ws∈R(n1∗(3m+dl)) 是变换矩阵,
O
∈
R
n
1
O∈R^{n_1}
O∈Rn1是网络的最终输出。其中
n
1
n_1
n1等于参数角色的数量,包括候选参数的“无角色”标签。 在活动中扮演任何角色。对于正则化,我们还在倒数第二层使用了dropout(Hinton et al.,2012),这可以通过在前向传播和反向传播期间随机丢弃隐藏单元的比例p来防止隐藏单元的协同适应。
【参考】正则化
3.4 训练
将参数分类阶段的训练的所有参数定义为 θ θ θ,E是词嵌入,PF是位置嵌入,EF是事件嵌入, W W W和 b b b是滤波器的参数, W s W_s Ws和 b s b_s bs是输出的参数。在这里对所有参数角色类型应用softmax操作,获得条件概率,然后再对这些所有的概率进行对数求和,得到最大似然,从而得到预测的结果。在代码当中最终得到的是事件类型的预测结果。
给定一个输入示例s,参数θ的网络输出向量O,其中第 i i i个元组 O i O_i Oi包含了参数角色i的得分。为了获得条件概率 p ( i ∣ x , θ ) p(i|x,θ) p(i∣x,θ),我们对所有参数角色类型应用softmax操作:
p ( i ∣ x , θ ) = e o i ∑ k = 1 n 1 e o k (8) p(i|x,θ)=\frac{e^{o_i}}{\sum_{k=1}^{n_1}e^{o_k}}\tag{8} p(i∣x,θ)=∑k=1n1eokeoi(8)
给定我们所有的(假设为T)训练样例 ( x i ; y i ) (x_i; y_i) (xi;yi),然后我们可以定义目标函数如下:
J ( θ ) = ∑ i = 1 T l o g p ( y ( i ) ∣ x ( i ) , θ ) (9) J(θ)=\sum_{i=1}^{T}logp(y^{(i)}|x^{(i)},θ)\tag{9} J(θ)=i=1∑Tlogp(y(i)∣x(i),θ)(9)
为了计算网络参数 θ θ θ,我们使用Adadelta(Zeiler,2012)更新规则,通过随机梯度下降在混洗小批量上最大化对数似然 J ( θ ) J(θ) J(θ)。
3.5 触发词分类
在以上各节中,我们介绍了参数分类的模型和功能。 上面提出的方法也适用于触发词分类,但是任务只需要在句子中找到触发词即可,没有参数分类那么复杂。 因此,我们可以使用DMCNN的简化版本。
在触发词分类中,我们仅在词汇级特征表示中使用候选触发词及其左右标记。 在句子级的特征表示中,我们使用与参数分类相同的CWF,但是我们仅使用候选触发词的位置来嵌入位置特征。 此外,不是将句子分为三部分,而是由候选触发词将句子分为两部分。 除功能和模型的上述更改外,我们将触发词分类视为参数的分类。 这两个阶段构成事件提取的框架。
4 实验
4.1 数据集和评估指标
数据集:ACE 2005语料库
评估指标:
- 如果触发词的事件子类型和偏移量与参考触发词的类型匹配,则触发词是正确的。
- 如果一个参数的事件子类型和偏移量与引用参数中提到的任何一个匹配,那么这个参数就被正确地标识出来。
- 如果一个参数的事件子类型、偏移量和参数角色与引用参数中提到的任何一个匹配,那么该参数就被正确分类。
最后,我们使用精确度(P)、召回率(R)和F测度(F1)作为评价指标。
4.2 我们的方法与最先进的方法
我们选择以下最先进的方法进行比较。
(1)Li’s baseline,基于特征的系统。它只使用了人类设计的词汇特征、基本特征和句法特征。
(2)Liao’s cross-event,利用文档级信息提高ACE事件抽取性能的方法。
(3)Hong’s cross-entity,通过跨实体推理提取事件。据我们所知,它是文献中报道最好的基于特征的系统基于黄金标准的论证候选。
(4)Li’s structure,基于结构预测提取事件。这是最好的报告结构为基础的系统。
DMCNN:
触发词分类:window=3;feature map=200;batch size=170;PF=5
参数分类:window=3;feature map=300;batch size=20;PF and EF=5
两个参数:p = 0.95; ε=
1
e
−
6
1e^{−6}
1e−6;dropout=0.5
词嵌入:在the NYT corpus(纽约时报语料库)用Skip-gram训练的

表1:盲测数据的总体性能
从结果中,我们可以看到我们提出的具有自动学习功能的DMCNN模型在所有比较方法中实现了最佳性能。
注意:由于该篇论文是2015年的,所以目前有性能更好的方法。
4.3 DMCNN对句子级特征提取的影响
我们特别选择了两种方法作为基线与我们的DMCNN进行比较:Embeddings+T和CNN。CNN类似于DMCNN,只是它使用标准的卷积神经网络和最大池来捕捉句子级的特征。相比之下,DMCNN在网络中使用动态多池层,而不是CNN中的max pooling层。此外,为了证明DMCNN能够更精确地捕捉句子层面的特征,特别是对于含有多个事件的句子,我们根据句子中的事件数(单事件和多事件)将测试数据分成两部分,分别进行评估。表2显示了包含多个事件或单个事件的句子的比例,以及在我们的数据集中参与一个或多个事件的参数的比例。表3显示了结果。
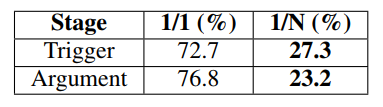
表2:一个句子中多个事件的比例。 1/1表示一个句子只有一个触发词或一个参数在一个句子中起作用; 1/N表示一个句子中有多个触发词或多个参数起作用的情况。
表3说明了基于卷积神经网络(CNN和DMCNN)的方法优于Embeddings+T,证明了卷积神经网络在句子级特征提取方面比传统的人类设计策略更有效。在表3中,对于所有的句子,我们的方法比CNN实现了大约2.8%和4.6%的改进。结果证明了动态多池层的有效性。有趣的是,DMCNN对含有多个事件的句子的触发器分类提高了7.8%。这种改进要比单个事件的句子更大。
对于参数分类结果,也可以进行类似的观察。这说明所提出的DMCNN能比最大池法更有效地捕捉更多有价值的线索,尤其是当一个句子包含多个事件时。

表3:传统方法,CNN和DMCNN模型获得的事件提取分数的比较
4.4 词嵌入对抽取词汇级特征的影响
这一部分研究我们的单词嵌入对词汇特征的有效性。为了进行比较,我们选择了Li等人描述的基线。(2013)作为传统的方法,它使用传统的词汇特征,如n-grams、POS标签和一些实体信息。相反,我们只使用单词嵌入作为我们的词汇特征。此外,为了证明单词嵌入能够捕捉到更有价值的语义,特别是对于那些在训练数据中从未出现过相同事件类型或参数角色的测试数据中的单词,我们将测试数据中的触发词和参数分为两部分(1:只出现在测试数据中,或2:同时出现在测试和具有相同事件类型或参数角色的训练数据)并分别执行评估。对于触发器,测试数据中34.9%的触发词在训练数据中从未出现过相同的事件类型。这一比例为83.1%。实验结果见表4。
表4说明,对于所有的情况,我们的方法在触发词和参数的分类方面都比传统的词汇特征有了显著的改进。对于情况B,从单词嵌入中提取的词汇级特征,触发器分类和参数分类分别提高了18.8%和8.5%。这是因为基线只使用离散的特征,因此它们受到数据稀疏的影响,无法充分处理触发词或参数未出现在训练数据中的情况。
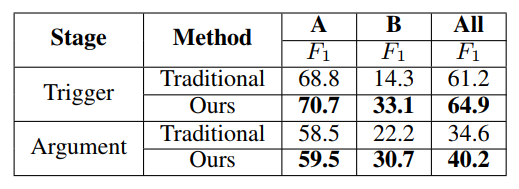
表4:传统词汇功能和我们的词汇功能的结果比较。 A表示同时出现在训练和测试数据集中的触发词或参数,B表示所有其他情况。
4.5 词汇特征vs.句子特征
为了比较不同层次特征的有效性,我们分别使用词汇特征和句子特征提取事件。使用DMCNN得到的结果如表5所示。有趣的是,在触发词分类阶段,词汇特征起到了有效的作用,而句子特征在论据分类阶段起着更重要的作用。当我们结合词汇层面和句子层面的特征时,效果最好。这一观察结果表明,这两个层次的特征对于事件提取都很重要。
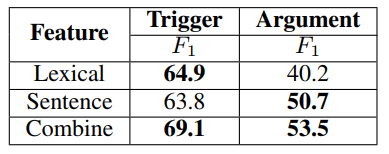
表5:通过词汇级别的特征,句子级的特征以及两者的组合获得的触发词分类得分和参数分类得分的比较
5 相关工作
事件提取是NLP中的重要主题之一,目前已经探索了许多用于事件提取的方法。几乎所有ACE事件提取都使用监督范式。我们进一步将监督方法划分为基于特征的方法和基于结构的方法。
在基于特征的方法中,已经利用各种策略将分类线索(例如序列和解析树)转换为特征向量。 Ahn(2006)使用词汇特征(例如,全字,pos标签),句法特征(例如,依赖特征)和外部知识特征(WordNet)来提取事件。灵感来自“每个故障的一个意义”的假设(Yarowsky,1995),Ji和Grishman(2008)将来自相关文献的全球证据与当地的事件提取决策结合起来。为了从文本中获取更多线索,Gupta和Ji(2009),Liao和Grishman(2010)以及Hong等人(2011)提出了ACE事件任务的跨事件和跨实体推理。尽管这些方法实现了高性能,但是基于特征的方法在将分类线索转换为特征向量时遇到选择合适的特征集的问题。
在基于结构的方法中,研究人员将事件提取视为预测句子中事件结构的任务。 McClosky等将生物医学事件提取的问题作为依赖性解析问题。Li 等人提出了基于结构感知器和光束搜索的ACE事件提取的联合框架。为了使用句子中的更多信息,Li 等人提出基于统一结构提取ACE任务中的实体提及,关系和事件。这些方法产生相对高的性能。然而,这些方法的性能在很大程度上取决于所设计的特性的质量,且必须接受现有NLP工具中的错误。
6 结论
本文提出了一种新的事件提取方法,该方法可以从纯文本中自动提取词汇级别和句子级特征,无需复杂的NLP预处理。引入词表示模型来捕获词汇语义线索,并设计动态多池卷积神经网络(DMCNN)来编码句子语义线索。实验结果证明了该方法的有效性。














 4633
4633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









