






利用动态多池化CNN实现事件提取
本篇博客主要介绍论文[Event Extraction via Dynamic Multi-pooling Convolutional Neural Networks]的主要内容,以及复现论文的实验过程:
【摘要】:
传统的ACE事件抽取的方法首先依赖人工设计的特征和复杂的NLP工具。这些传统的方法缺少一般性,需要大量的人力成本,而且会产生误差传播以及数据稀疏问题。本文提出了一个新的事件抽取方法,目的是自动地抽取文本级别的以及句子级别的特征,不需要使用复杂的NLP工具。我们提出了一个单词表示模型来描述有意义的语义规律而且采用了一个基于卷积神经网络的框架来描述句子级别的线索。然而,CNN仅仅能描述句子中最重要的信息,而且当考虑多事件句子的时候可能丢失掉有价值的事实。我们提出了一个动态多池化CNN(dynamic multi-pooling convolutional neural network,DMCNN),为了保持更多的重要的信息,该方法根据事件触发器和参数使用动态的多池化层。实验结果证明我们的方法比其他最好的方法(state-of-the-art methods)都要明显地好。
介绍
事件抽取(Event Extraction):其目标在于发现事件特别类型的触发器以及事件参数。目前最好的方法是通过利用一系列通过文本分析以及语言学知识提取的精心设计好的特征。总体上,我们可以将这些特征分为两类:Lexical features 以及 contextual features。
词法特征(Lexical features):包括词性、实体信息以及形态学特征。目标是获取词语的语义以及词语背后的知识。提取传统的词法特征用以往传统的方法是one-hot 编码的方法。这种方式可能会遇到数据稀疏问题,以及不能充足地获取词的语义。
上下文特征(Contextual features):就像语法特征,目的在于理解事实在一个大的范围中是如何被联系到一起的。提取内部语义,最近CNN的改进以及被证明,能够有效提取一个句子中的词之间的语法以及语义知识。但是CNN通常是运用最大池化层去对整个句子的表示进行一个取最大值操作,以获取最重要的信息。但是,在事件提取中,一个句子可能包含,两个或者多个事件。而且,这些事件可能共享扮演不同角色的同一参数,这种问题用传统的CNN是解决不了的,所以引入了DCNN。
内容
在这篇论文中,作者提出了一种动态多池化CNN去解决上述问题:
为了解决词汇层线索(lexical-level clues)问题,介绍了一种词编码(word-representation)方法。
为了解决句子层线索(sentence-level clues)问题,发明了一种动态多池化CNN方法。根据触发词以及参数词返回句子中每一部分的最大值。论文的主要贡献有:
- 为事件提取提出了一个新颖的框架,它可以不通过复杂的NLP预处理过程,自动地从纯文本中提出Lexical-level features 以及 sentence-level features;
- DMCNN;
- 运用ACE2005事件提取数据集进行实验,发现实验效果比其他最好的方法都要好。
ACE2005
ACE项目是为了开发自动提取技术,为了支持自动处理源语言数据。自动处理,那时定义包括,分类、过滤以及基于源数据语言内容的选择。ACE为广播稿、新闻通讯社以及报纸数据标注了英语、中文、阿拉伯语标签。三种主要的ACE任务:实体检测与跟踪(EDT)、关系检测与描述(RDC)、事件检测与描述(EDC)。以及第四种,实体链接(LNK)。
事件描述(Event mention):一个短语或者句子,描述一个事件,包括一个触发器以及一些参数。
事件触发器(Event trigger):最能清楚表达事件发生的一个词,ACE中主要为一个动词或者名词。
事件参数(Event argument):一个事件中的一个实体描述,暂时性的表达或者值。
参数角色(Argument role):事件与参数之间的关系。
给定一篇英文文本,一个事件抽取系统能够预测出带有具体子类型的事件触发器以及每个句子的参数。ACE定义了8种事件以及33种子事件。这里,主要是直接利用ACE提供的实体标签。
事件描述以及句法分析器实例:
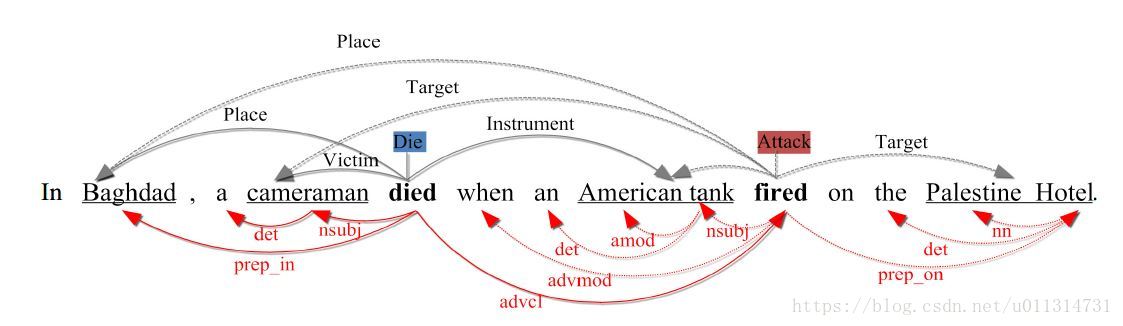
上部分展示了两种事件描述共享了三个参数:Baghdad、cameraman、American tank。两种事件 描述:Die事件,触发器为“died”;Attack事件,触发器为"fired"。下部分展示了依赖结果。
方法论
本文中,事件提取被规划为两个步骤:
(1). trigger classification:利用DMCNN将句子中trigger word识别出来;
(2). argument classification:利用一个相似的DMCNN去识别arguments,并且识别出这些arguments对应的roles。
因为第二阶段更复杂,所以这里的3.1—3.4将会描述arguments classification的方法,在3.5中将会阐述两阶段使用的DMCNN的不同。
Figure 2描述了argument classification的结构,主要包括4个部分:
- [1] word-embedding learning:以非监督的方式得到词的嵌入向量;
- [2 ] lexical-level feature representation:直接用词嵌入向量组成词汇线索;
- [3 ] sentence-level feature extraction:用一个DMCNN网络学习句子的语义特征;
- [4 ] argument classifier output:为参数的每个候选角色计算了置信度。
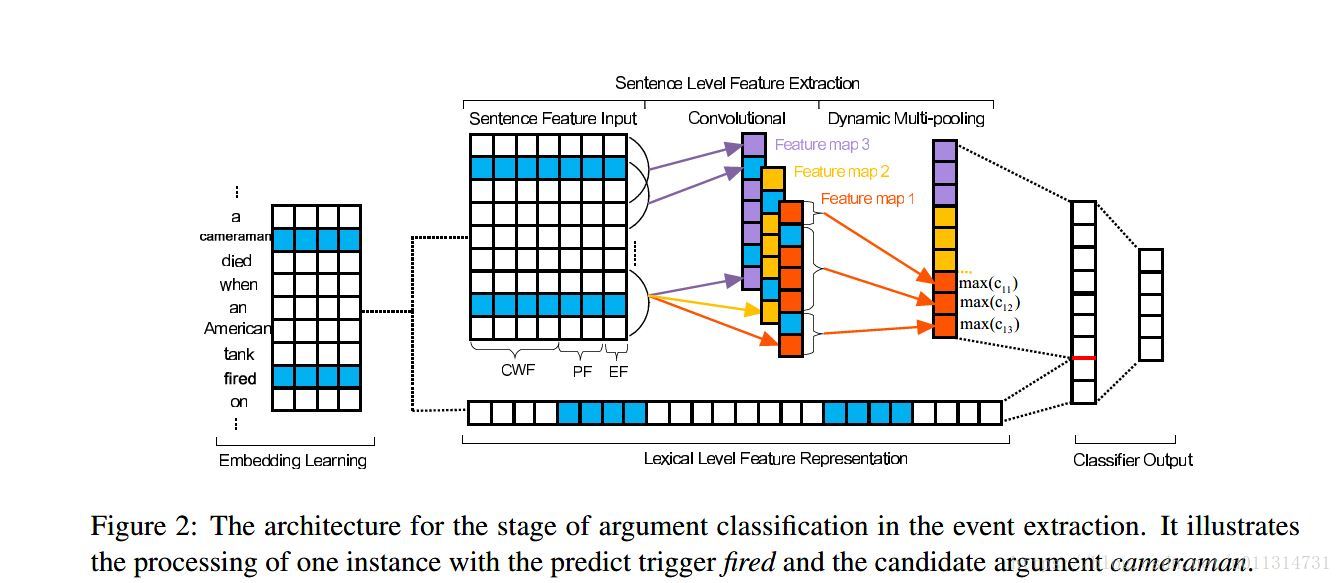
-
Word Embedding Learning and Lexical-Level Feature Representation
传统的Lexical-level特征主要包括lemma(人名,地名),synonyms(同义词),POS tag(词性标签),特征的质量很大依靠于现有NLP工具以及人类的创造力。传统特征不能满足词语语义的获取,而这在事件提取中是十分重要的。词嵌入在获取大量未标注文本的有意义的语义规则显得更加强大。先利用提前利用非监督方式训练好的词嵌入作为基础特征源。我们为候选词挑选词嵌入向量(包括trigger候选词以及argument候选词)以及上下文tokens(左边以及右边tokens)。然后,所有的次嵌入向量将会被连接在一起形成向量L(lexical-level features vector),用来在argument分类过程中代表lexical-level特征。
其中,我们利用Skip-gram模型预训练词嵌入向量。这个模型在很多NLP任务中是最佳方法。
Skip-gram模型同过最大化平均对数概率来words(w1,w2,…wm)的词嵌入向量:
-
Extraction Sentence-Level Features Using a DMCNN
DMCNN用动态多池化层去获取了句子每个部分的最大值,每个部分由事件trigger以及argument分割。因此DMCNN期望比传统CNN方法获得更有价值的线索(传统CNN只能获得一个句子中最有价值的信息)。

- Input
被预测的trigger词以及argument候选词之间的语义交互对于argument classification来说非常重要。因此我们提出了三种类型的DMCNN输入,用来获取这些重要的线索:
1.Context-word feature(CWF):我们将一个句子中的所有词作为上下文,CWF是一个所有字标记都被转换为词嵌入向量。
2.Position feature(PF): 有必要说明在argument classification中那些词被预测为trigger或者候选argument,因此引入PF。PF被定义为当前词语与预测trigger以及候选argument之间的相对距离。例如S3中tank以及候选argument cameraman之间的相对距离为5。为了编码位置特征,每个距离值也被词嵌入向量所代表。与词嵌入相似,距离值也是先随机初始化然后通过BP算法优化。
3.Event-type feature(EF):当前trigger的事件类型对于argument classification也是具有价值的。所以对在trigger classification过程中预测的事件类型进行编码,也做为DMCNN的一个重要线索,编码方式与PF相同。
dp乘以2 是因为相对距离有两个,一个是对于trigger,一个对于argument。
如Figure2,最后形成的Sentence Feature输入为一个nxd的矩阵 - Convolution
卷积层的目的在于获取整个句子的语义并将这些有意义的语义压缩到特征图(feature maps)中。
一个特征图的生成:一个过滤器
w:过滤器 c:特征图 h:窗口大小 b:偏执项 f:非线性函数 i:(1,n-h+1)
多个特征图的生成就需要多个过滤器:
- Dynamic Multi-Pooling
一个句子或许包含两个或者更多的事件,以及一个argument候选或许给不同的trigger扮演着不同的角色。为了做出准确的预测,随着候选词的变化获取最有价值的信息是必要的。因此在argument阶段,我们根据候选argument以及预测出的trigger将每个特征图分割为3个部分。我们保留每一分割部分的最大值——动态多池化,而不是用一个特征图的最大值代表这个句子。与传统的最大池化相比,多池化保留更多的有价值的信息,从而不会错过最大池化值。
如Figure2所示,
得到每个特征图3部分的每部分最大值,最后连接在一起组成向量P,长度为3m。




- Output
上面自动学习获取的词汇特征(lexical feature)以及句子级特征(sentence level feature)被连接为一个简单的向量F=[L,P]。
m:特征图数目 l:词汇特征维数 Ws:转换矩阵 O:输出 n1:参数角色(包括没有角色这一种情况)
规则上,同时在倒数第二层引用了dropout,通过在BP过程中随机地去掉比例为p的隐藏单元可以避免隐藏单元的协同适应。 - Training
我们定义argument classification每个阶段将要被训练的参数 θ =(E, PF1, PF2, EF, W, b, Ws, bs)。E是词嵌入阶段,PF1以及PF2是位置嵌入,EF是事件类型嵌入,W和b是过滤器参数,Ws以及bs是输出层所有参数。
给定一个输入例子s,带有参数θ的网络输出向量O,当第i个组成成分 Oi包含了参数角色i的分数。为了获得条件概率p(i|x, θ),我们对所有参数类型应用了一个softmax操作:
假定我们所有训练示例的集合为T,我们可以将目标函数定义为J (θ)。为了计算参数θ,我们将通过在mini-batches上面通过随机梯度下降最大化对数似然J (θ)。 - Model for Trigger Classification
trigger classification的方法与argument classification方法类似,但是trigger classification中我们只需要识别triggers,比argument classification 简单,因此我们可以利用一个简单版本的DMCNN。
在trigger classification中,词汇级特征表示我们只用了trigger候选词以及它左右的标记词。句子级别的特征表示,我们用了CWF以及PF。然后,根据候选trigger我们将句子分为两个部分。除了上述特性和模型的变化,我们将trigger分类当做argument的分类。这两个阶段形成了事件提取的框架。


实验
-
Dataset and Evaluation Metric
利用ACE2005语料库作为我们的数据集,以40篇新闻专线文章作为测试集,从不同类型的文章中随机挑选30篇文档作为开发集,剩下的529篇文章作为训练集。与之间的工作类似,我们选择了以下标准评价预测事件的正确率:- 如果触发器的事件子类型和偏移量与引用触发器匹配,则触发器是正确的。
- 如果一个参数的事件子类型和偏移量与引用参数中提到的任何一个匹配,那么这个参数就是被正确地识别。
- 如果一个参数的事件子类型、偏移量和参数角色与引用参数中提到的任何一个匹配,那么该参数将被正确分类。
最后,我们利用了precision§,Recall®以及F measure(F1)作为评价指标。
-
Our Method vs. State-of-the-art Methods
- Li’s baseline:提出一个 基于特征的系统,只应用人工设计的词汇特征,基础特征以及语法特征。
- Liao’s cross-event:用文本级信息去提高在ACE上做信息提取的性能。
- Hong’s cross-entity:通过跨实体推理提取事件,据我们所知,它是文献中基于黄金标准论证候选对象的最佳基于特征的系统。
- Li’s structure:通过结构预测提取事件,它是最好的基于结构的系统。
在 Li et al.(2013)之后,我们通过网格搜索(grid search)的方法对参数进行了调优。而且,在事件提取的不同阶段,我们在DMCNN中使用了不同的参数。
特别是,在trigger classification中,我们将窗口大小设置为3,特征图的数量设置为200,batch size为170,PF的维数为5。在argument classification中,我们将窗口大小设置为3,特征图数量设置为300,batch size大小为20 ,PF的维数以及EF的维数都为5。
Stochastic gradient descent over shuffled mini-batches with the Adadelta update rule(Zeiler, 2012) is used fortraining and testing processes。主要包括两个参数,p and ε。p=0.95, ε = 1e
−6次方。dropout的rate为0.5。在NYT 语料库上使用Skip-gram 算法训练次嵌入向量。
- 后面就是DMCNN与不同算法的性能比较,这里不再赘述。














 1694
1694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









