






整理自知乎Llama 2详解 - 知乎
和b站Llama 2 模型结构解析_哔哩哔哩_bilibili
一、大语言模型处理流程
1.promt提示阶段:输入的这一串文本,进去之后模型内部会干什么事情,为生成阶段生成第一个token
2.生成阶段:收到提示,来进行回复
eg.
1.prompt
输入:今天星期几
Tokennization:将其切分为单词或字符,形成Token序列。之后再将文本映射为模型可理解的输入形式(将文本序列转换为语料库的整数索引序列)
Embedding:单个索引(每个token)转换为一个实数向量,称为Embedding Vector
position embedding :对于token序列中每个位置,添加位置编码
transformer : 生成任务一般只用到decoder阶段 ,生成一个token
2.生成阶段
自回归生成(autoregressive):利用前面生成的上下文,去生成下面的token
model = LLaMA2()
def generate(inputs, n_tokens_to_generate):
for _ in range(n_tokens_to_generate): # auto-regressive decode loop
output = model(inputs) # model forward pass
next = np.argmax(output[-1]) # greedy sampling
inputs.append(next) # append prediction to input
return inputs[len(inputs) - n_tokens_to_generate :] # only return generated tokens
input = [p0, p1,p2] #对应['BOS','君','不']
output_ids = generate(input, 3) # 假设生成 ['p3','p4','p5']
output_ids = decode(output_ids) # 通过Tokenization解码
output_tokens = [vocab[i] for i in output_ids] # "见" "黄" "河"(next = np.argmax(output[-1]) # greedy sampling,np.argmax(output[-1]) 的意思是:找出 output 数组最后一个元素所对应的最大值的索引。)
输出处理:将生成的token序列通过一个输出层,通常是线性层+softmax
二、模型
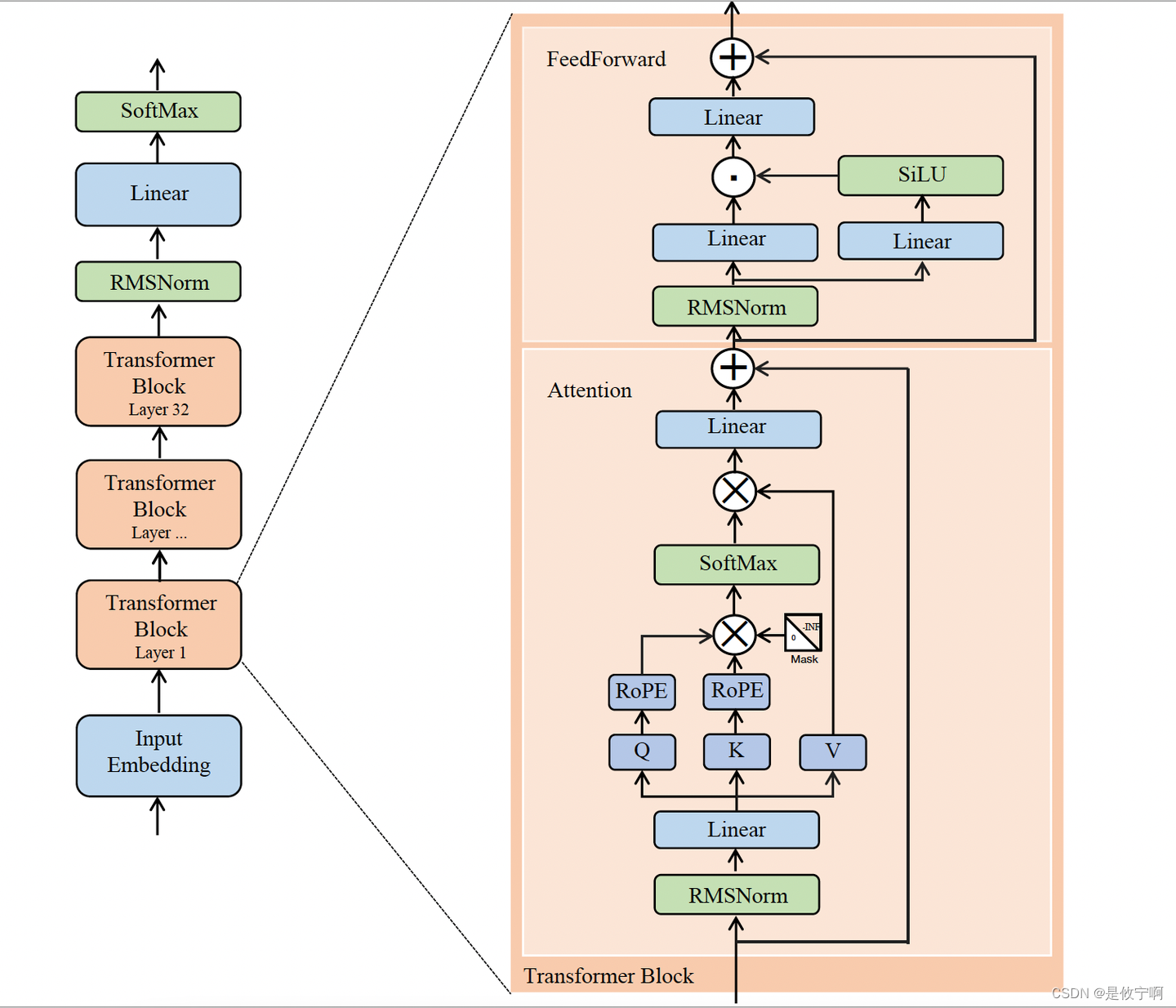
1.RMSNorm
跟之前的正则化层差不多,只是省去了求均值和方差的过程
2.Linear
linear层大小为[dim, dim],故shape不会改变
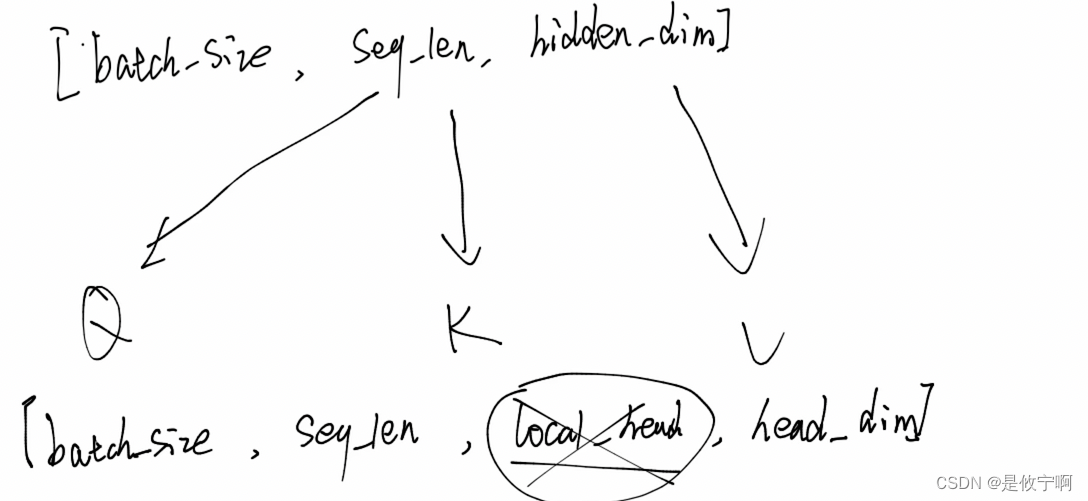
3.多头自注意力层
x通过三个线性层linear得到三个量q,k,v
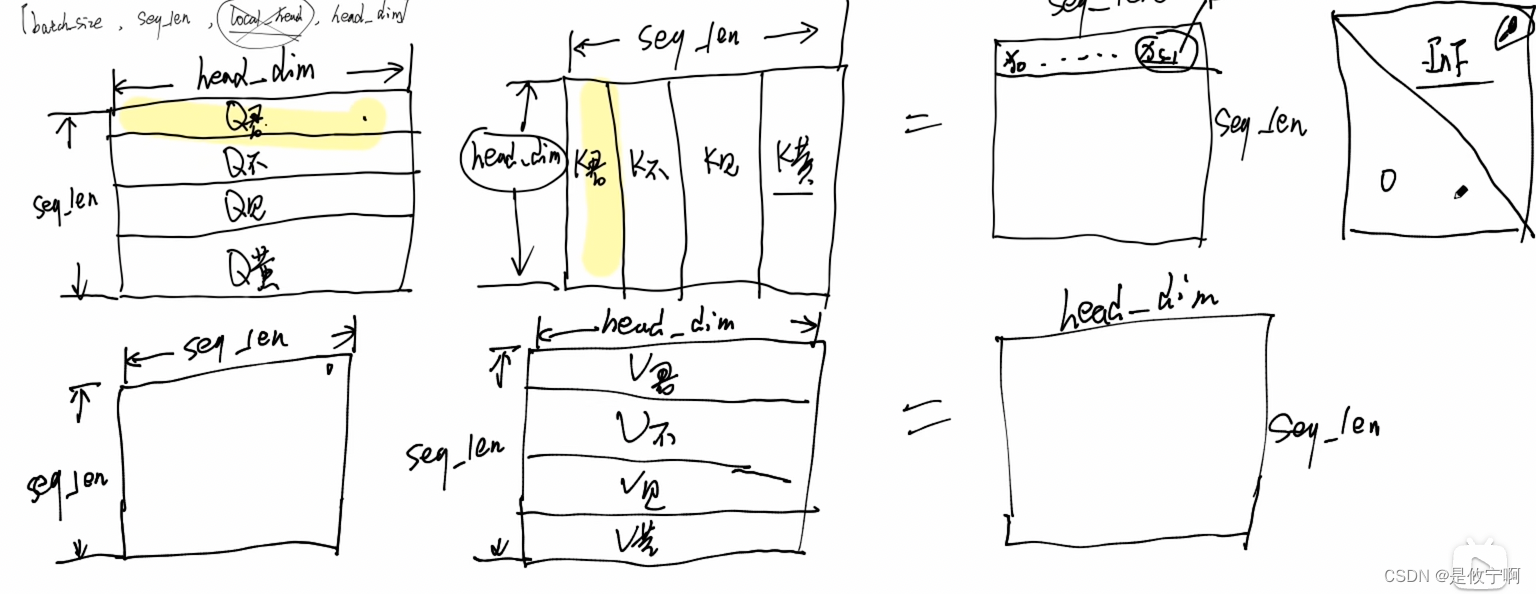
attention计算(缩放点积注意力机制)
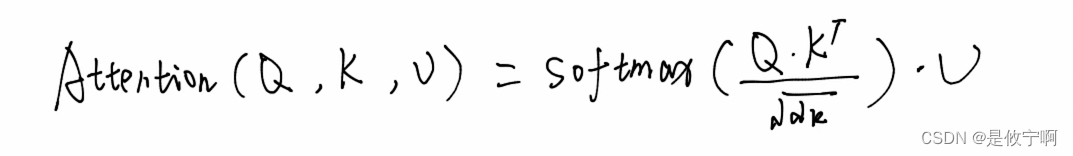
经过attention计算,形状并不会改变
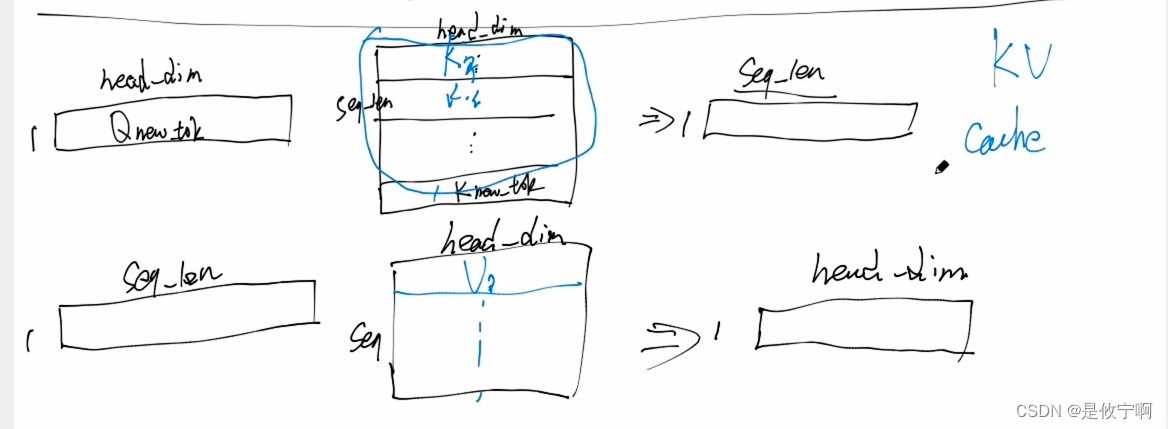
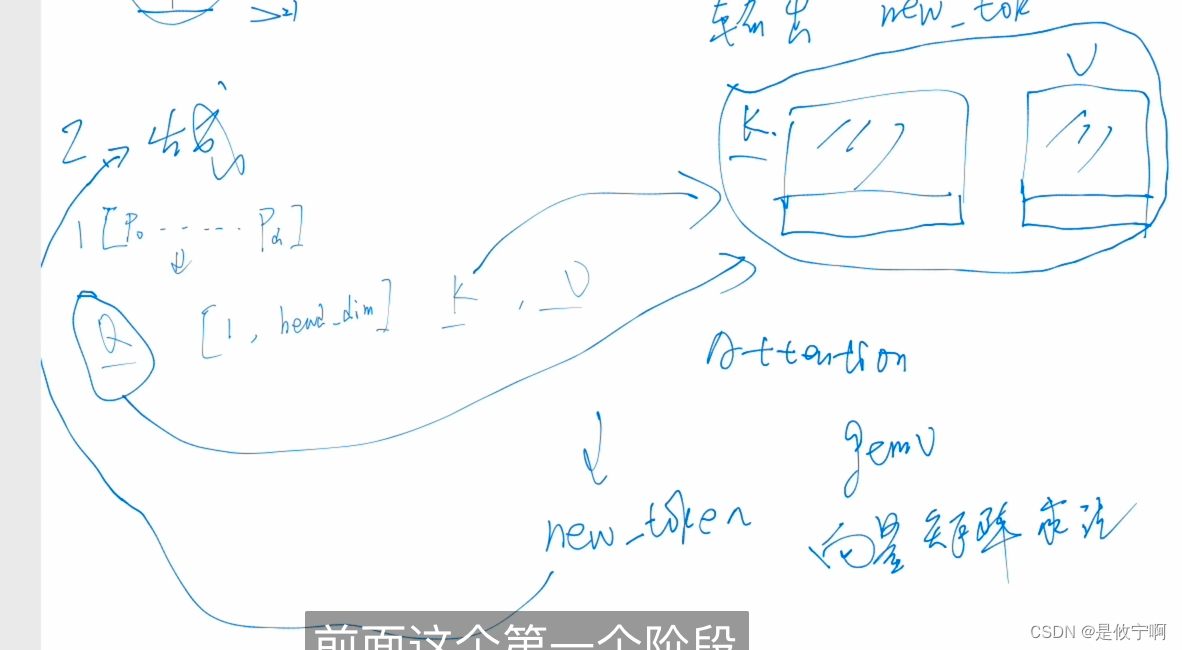
因为是aoturegressive,根据前面的推后面的,为了减少计算,使用k-v cache
4.RoPE
是旋转位置编码,既包含绝对位置关系,又包含相对位置关系

三、总结


















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









