







1. 背景
RNN(Recurrent Neural Networks)
CNN利用输入中的空间几何结构信息;RNN利用输入数据的序列化特性。
2. SimpleRNN单元
传统多层感知机网络假设所有的输入数据之间相互独立,但这对于序列化数据是不成立的。RNN单元用隐藏状态或记忆引入这种依赖,以保存当前的关键信息。任一时刻的隐藏状态值是前一时间步中隐藏状态值和当前时间步中输入值的函数
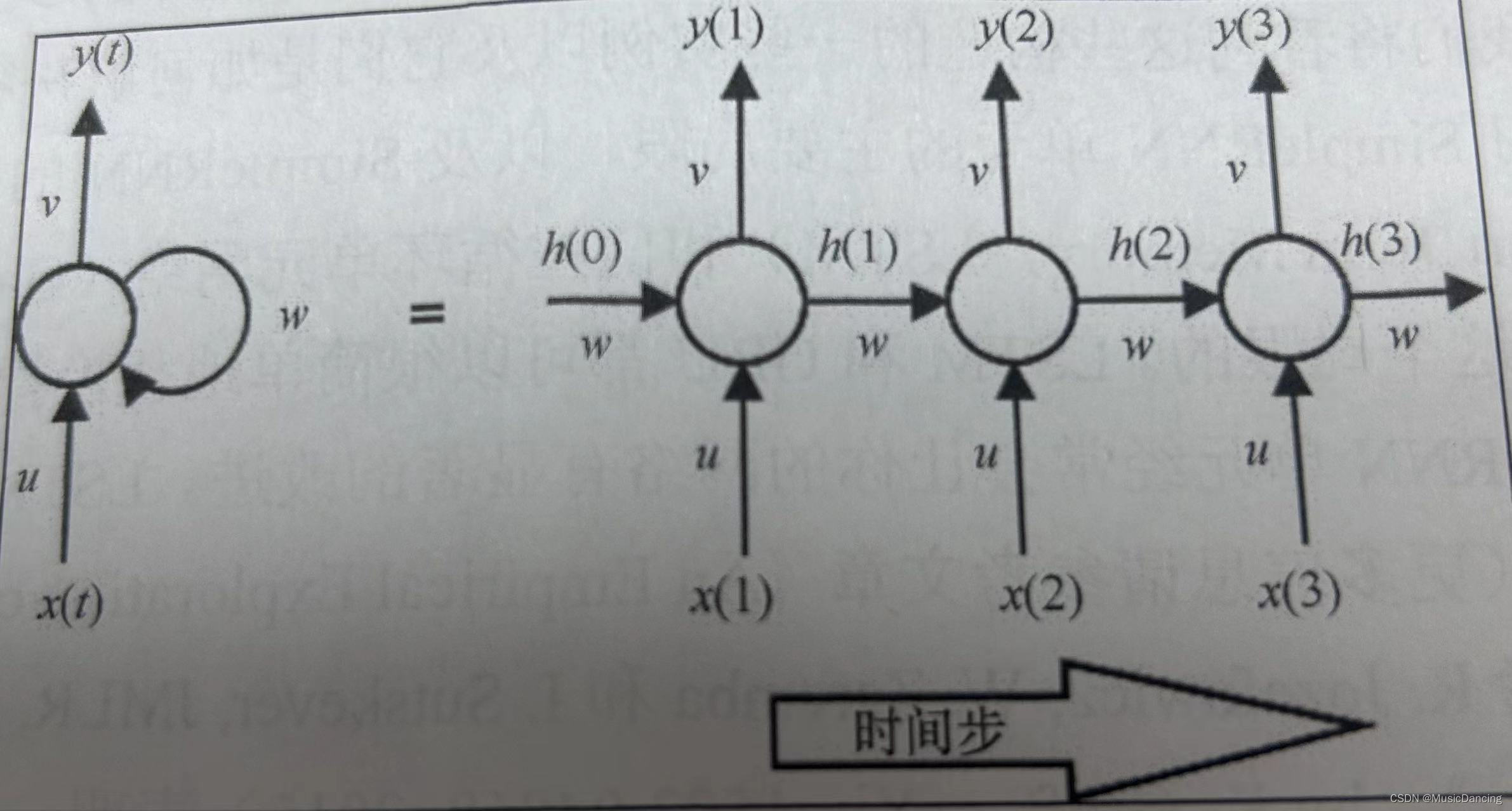
在所有时间步上共享相同的权重向量(U、V、W),极大地减少了RNN网络需要学习的参数个数(即RNN的数量不随时间步的增加而增长)。其t时间步输出
选择t
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2274
2274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









