







参考:团伙挖掘 or Embedding?这是个问题。 - 知乎
1. 背景
直接的团伙挖掘还是做Embedding?是经常要面临的选择。
1.1 数据集简介
使用手机号、邮箱、IP地址、用户ID四种节点生成一个图数据的异构图。pip install Faker
from faker import Faker
fake = Faker(locale='zh_CN')
def gen_data():
# 4个节点
uid = ['uid_' + str(fake.random_int(10000, 10012)) for i in range(0, 12)]
uid1 = ['uid_' + str(fake.random_int(10000, 10100)) for i in range(0, 100)]
ip = ['ip_' + fake.ipv4() for i in range(0, 4)]*3
email = ['em_' + fake.email() for i in range(0, 50)]*2
phone = ['ph_' + fake.phone_number() for i in range(0, 100)]*1
# 3种关系
df1 = pd.DataFrame({'sr': uid, 'ds': ip})
df2 = pd.DataFrame({'sr': uid1, 'ds': email})
df3 = pd.DataFrame({'sr': email, 'ds': phone})
# 四个节点、三种关系合并
df = pd.concat([df1, df2, df3])
df = df.groupby(['sr', 'ds']).agg({'ds': ['count']}).reset_index() # 对数据进行聚合
return df1.2 构建&显示图
def gen_graph():
df = gen_data() # 图数据转换
df = df.values
G = nx.Graph()
for num in range(len(df)):
G.add_edge(str(df[num, 0]), str(df[num, 1]))
return G
def plot_graph(G):
colors = ['#008B8B', 'b', 'orange', 'y', 'c', 'DeepPink', '#838B8B', 'purple', 'olive', '#A0CBE2', '#4EEE94']*50
colors = colors[0: len(G.nodes())]
# 显示该graph
plt.figure(figsize=(4, 4), dpi=400)
nx.draw_networkx(G, pos=nx.spring_layout(G),
node_color=colors, font_color='DeepPink',
node_size=15, font_size=2, alpha=0.95,
width=0.5, font_weight=0.9)
plt.axis('off')
plt.show()如下:

2. 最大连通子图算法进行团伙挖掘
com_list = list(nx.connected_components(G)) # 找到所有连通子图,列表-字典格式
com_cnt = len(com_list) # 社区数量:12
# 整理成数据表格形式
df = pd.DataFrame()
for i in range(0, len(com_list)):
com_df = pd.DataFrame({'group_id': [i] * len(com_cnt[i]), 'object_id': list(com_list[i])})
df = pd.concat([df, com_df])
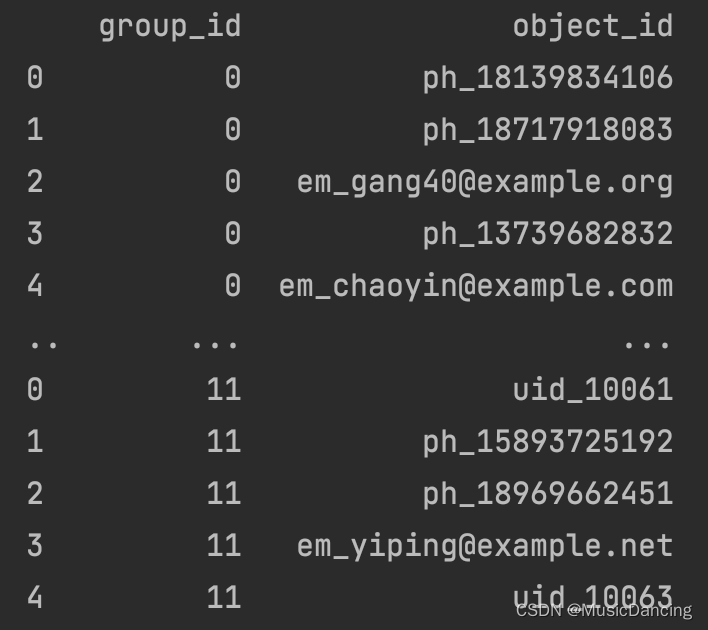
print(df) # 查看数据结果如下:
统计每个团伙人数,并降序
res = df.groupby('group_id').count().sort_values(by='object_id', ascending=False)
print(res)
# 0 85
# 1 58
# 4 17
# 3 9
# 5 5
# 7 5
# 8 5
# 10 5
print(df[df['group_id'] == 4]) # 查看第4组明细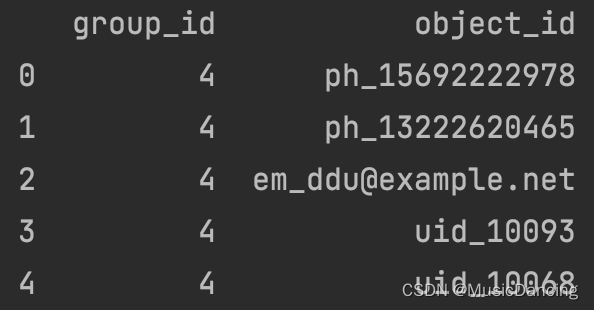
可以看到分成了10个团伙,最大的85个人,最小的5人。
3. 训练节点向量 embedding
查看同一个团伙的相似性
from node2vec import Node2Vec
node2vec = Node2Vec(G, dimensions=64, walk_length=30, num_walks=200, workers=4)
model = node2vec.fit(window=10, min_count=1, batch_words=4) # Embed nodes
# Look for most similar nodes
model.wv.most_similar('uid_10033', topn=20)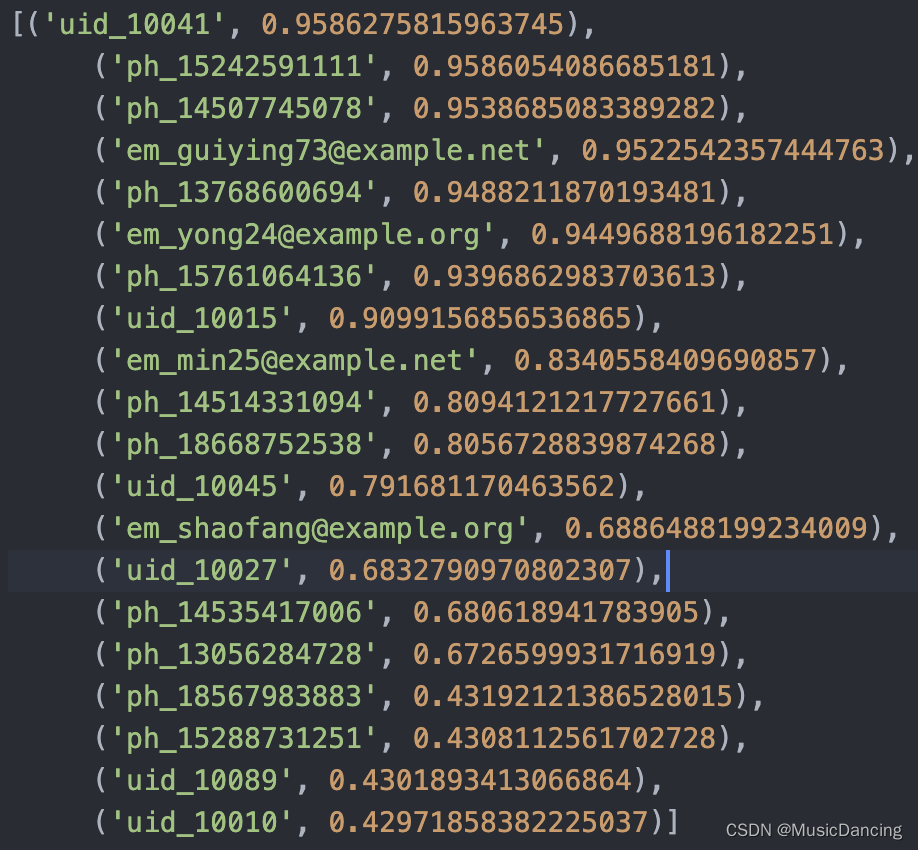
可以看到:最近的是uid_10041,比直接接壤的em_guiying73@example.net要高,感觉就是扁担两端的比桥梁略高一点,整体差异不大,就是离得近的越相似。离得远的越不相似。uid_10010、uid_10089甚至都不在一个社群里面。
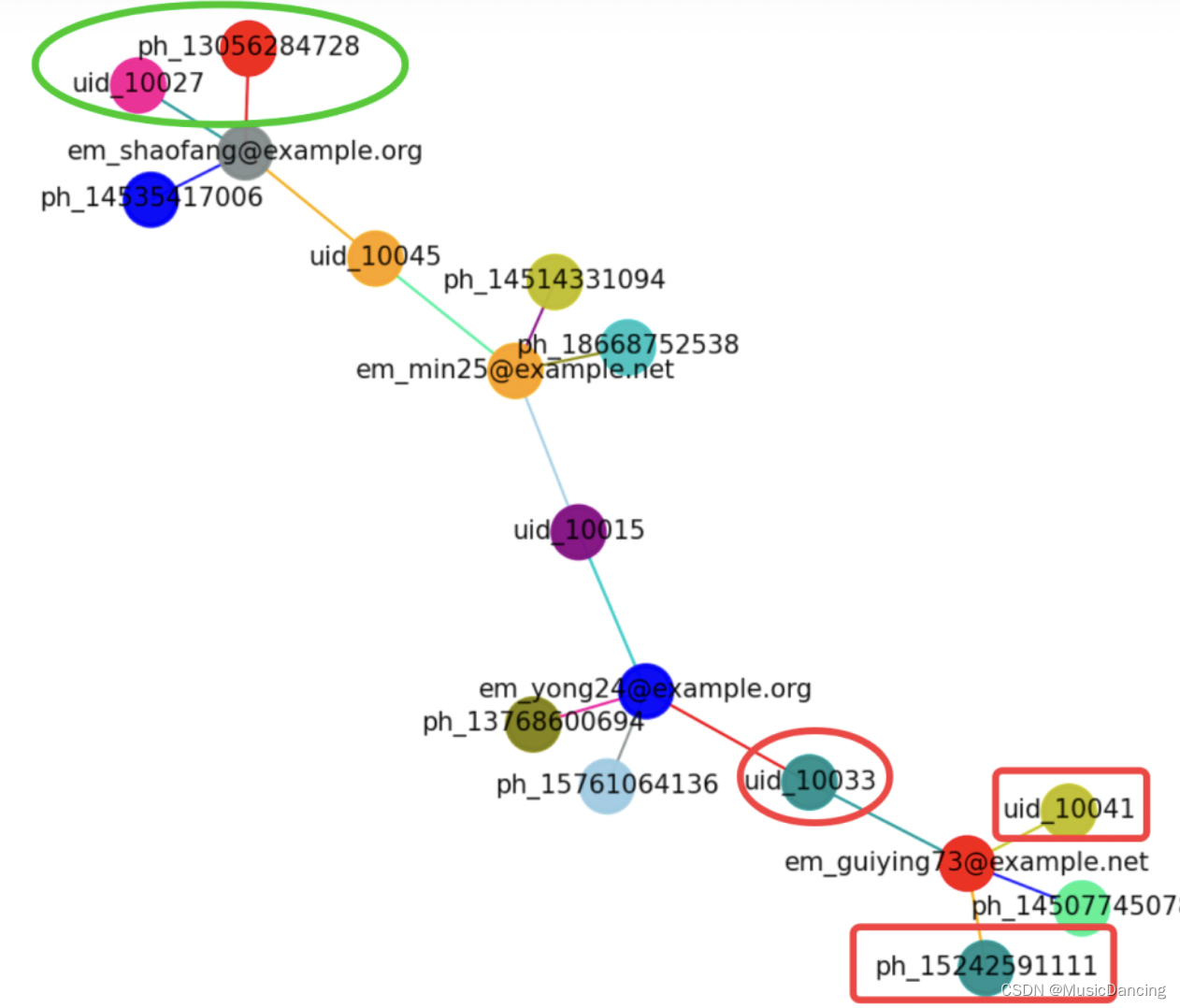
# 图上离得最远的两个伙伴相似度
model.wv.similarity('ph_18609158237', 'ph_13598935989')
# 0.8747926
# 两个用户的距离
model.wv.similarity('uid_10077', 'uid_10039')
# 0.9642026
# 两个最远的(左上角和右下角的),相似度很低
model.wv.similarity('uid_10004', 'uid_10096')
# 0.36086872
# 再在中间挑两个离得近的,相似度高
model.wv.similarity('uid_10001', 'uid_10003')
# 0.9128927单个团伙可视化
from pandasql import sqldf
df.columns = ['sr', 'ds', 'cnt']
# 单个团伙关系提取
query = ''' select sr, ds
from(select sr, ds from df) a
left join(
select group_id, object_id
from df_com
where group_id=0) b
on a.sr = b.object_id
left join(
select group_id, object_id
from df_com
where group_id=0) c
on a.ds = c.object_id
where b.object_id is not null and c.object_id is not null
'''
ls = sqldf(query)
# 社区还原并可视化
da = ls[['sr', 'ds']].values
G = nx.Graph()
for num in range(len(da)):
G.add_edge(str(da[num, 0]), str(da[num, 1]))在图中进行embedding时,越远相似性越低,并没有考虑结构和特征,但是向量化后可以用作分类任务或者与其他特征融合。在团伙挖掘中,每个节点都是等价的,也是容易误杀。对比下来,两个算法基本上都可以用,但是效果不是最好的,那能填补这两个缺点的,就只有图NN了。
















 2300
2300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









