







 文章目录一、时间序列数据的表示方法二、Embedding层三、单层RNN与多层RNN1.单层RNN2.多层RNN四、RNN案例—情感分类实战1.单层RNN2.多层RNN3.SimpleRNN—高级封装五、LSTM案例—情感分类实战1.LSTMCell2.LSTM—高级封装六、GRU案例—情感分类实战1.GRUCell2.GRU一、时间序列数据的表示方法 循环神经网络RNN是对具有时间先后顺序的数据做处理的。 如果数据类型为结构化数据时,可以由[????, ????, ????]的张量才能表
文章目录一、时间序列数据的表示方法二、Embedding层三、单层RNN与多层RNN1.单层RNN2.多层RNN四、RNN案例—情感分类实战1.单层RNN2.多层RNN3.SimpleRNN—高级封装五、LSTM案例—情感分类实战1.LSTMCell2.LSTM—高级封装六、GRU案例—情感分类实战1.GRUCell2.GRU一、时间序列数据的表示方法 循环神经网络RNN是对具有时间先后顺序的数据做处理的。 如果数据类型为结构化数据时,可以由[????, ????, ????]的张量才能表
文章目录
一、时间序列数据的表示方法
循环神经网络RNN是对具有时间先后顺序的数据做处理的。
如果数据类型为结构化数据时,可以由[𝑏, 𝑠, 𝑛]的张量才能表示
其中,b为序列数量,s为序列长度,n为每个时间戳产生长度为𝑛的特征向量
如下图,可理解为b个波(种类),每个波(种类)上有100(s)个时间戳,每个时间戳可由长度为1(n)的张量表示

如果数据类型为图片数据时,也可以由[𝑏, 𝑠, 𝑛]的张量才能表示
其中,b为图片数量,s为每张图片的序列长度,n为每个时间戳用长度为n的向量表示
如下图,可理解为b张图片,每张图片扫描28次,每次扫描用长度为n的向量表示(每次扫描提取28个特征)

如果数据类型为文本数据:
对于一个含有𝑛个单词的句子,单词的一种简单表示方法就是One-hot编码。以英文句子为例,假设我们只考虑最常用的1 万个单词,那么每个单词就可以表示为某位为1,其它位置为0 且长度为1 万的稀疏One-hot 向量;对于中文句子,如果也只考虑最常用的5000 个汉字,同样的方法,一个汉字可以用长度为5000 的One-hot 向量表示。如图中所示,如果只考虑𝑛个地名单词,可以将每个地名编码为长度为𝑛的Onehot向量。

文字编码为数值的过程为Word Embedding,One-hot 的编码方式实现WordEmbedding 简单直观,编码过程不需要学习和训练。
但是One-hot 编码的向量是高维度而且极其稀疏的(大量的位置为0,计算效率较低),同时也不利于神经网络的训练。从语义角度来讲,One-hot 编码还有一个严重的问题,它忽略了单词先天具有的语义相关性。
举个例子,对于单词“like”、“dislike”、“Rome”、“Paris”来说,“like”和“dislike”在语义角度就强相关,它们都表示喜欢的程度;“Rome”和“Paris”同样也是强相关,他们都表示欧洲的两个地点。对于一组这样的单词来说,如果采用One-hot 编码,得到的向量之间没有相关性,不能很好地体现原有文字的语义相关度,因此One-hot 编码具有明显的缺陷。

在自然语言处理领域,有专门的一个研究方向在探索如何学习到单词的表示向量(Word Vector),使得语义层面的相关性能够很好地通过Word Vector 体现出来。一个衡量词向量之间相关度的方法就是余弦相关度(Cosine similarity)

𝜃为两个词向量之间的夹角,cos(𝜃)较好地反映了语义相关性


二、Embedding层
在神经网络中,单词的表示向量可以直接通过训练的方式得到,我们把单词的表示层叫作Embedding 层。Embedding 层负责把单词编码为某个词向量𝒗,它接受的是采用数字编码的单词编号𝑖,如2 表示“I”,3 表示“me”等,系统总单词数量记为𝑁vocab,输出长度为𝑛的向量𝒗:
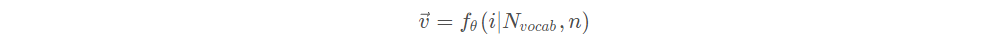
Embedding 层实现起来非常简单,构建一个shape 为[𝑁vocab, 𝑛]的查询表对象table,对于任意的单词编号𝑖,只需要查询到对应位置上的向量并返回即可。
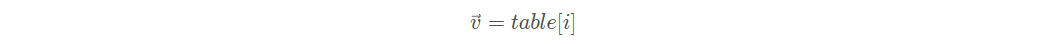
Embedding 层是可训练的,它可放置在神经网络之前,完成单词到向量的转换,得到的表示向量可以继续通过神经网络完成后续任务,并计算误差,采用梯度下降算法来实现端到端(end-to-end)的训练。
在 TensorFlow 中,可以通过layers.Embedding(𝑁vocab,𝑛)来定义一个Word Embedding层,其中𝑁vocab参数指定词汇数量,𝑛指定单词向量的长度。
import tensorflow as tf
from tensorflow.keras import layers
x = tf.range(10) # 生成10个单词的数字编码
x = tf.random.shuffle(x)
# 创建共10个单词,每个单词用长度为4的向量表示的层
net = layers.Embedding(10,4)
out = net(x)
tf.Tensor(
[[-0.0001258 -0.01502239 0.00644372 0.04399958]
[-0.03629031 -0.04979119 -0.00445051 -0.0088243 ]
[-0.03081716 0.0424983 -0.03043612 -0.01220802]
[-0.02545066 -0.04368721 -0.02251965 0.00655595]
[-0.04625113 -0.04106627 0.0468717 0.0404476 ]
[-0.00539555 -0.0425167 -0.0274111 -0.01424157]
[-0.03010789 0.0140976 0.01486215 -0.0171892 ]
[ 0.03787538 0.02254117 0.01853167 0.04533416]
[-0.03413143 -0.02415942 0.03709478 0.01728374]
[-0.02677795 0.00826843 -0.0051159 -0.01122908]], shape=(10, 4), dtype=float32)
查看Embedding 层内部的查询表table:
print(net.embeddings)
<tf.Variable 'embedding/embeddings:0' shape=(10, 4) dtype=float32, numpy=
array([[-0.02671334, -0.01306969, -0.01389484, 0.02536395],
[ 0.03719736, 0.00645654, -0.04235708, 0.04766853],
[ 0.01650348, -0.03993852, 0.01852169, -0.01021679],
[ 0.015307 , -0.02686958, -0.0118206 , -0.04958133],
[ 0.02233492, 0.00747244, 0.04506476, 0.01315404],
[ 0.00199506, -0.00295981, 0.01042227, -0.00751244],
[ 0.03401004, 0.00053816, 0.04955151, -0.03941982],
[ 0.00327535, -0.02441757, -0.01637713, -0.04333794],
[ 0.00115421, 0.03005128, -0.03063954, -0.04861031],
[-0.04716169, -0.02324554, -0.02143958, -0.02631059]],
dtype=float32)>
并查看net.embeddings 张量的可优化属性为True,即可以通过梯度下降算法优化。
print(net.embeddings.trainable)
True
Embedding 层的查询表是随机初始化的,需要从零开始训练。实际上,我们可以使用预训练的Word Embedding 模型来得到单词的表示方法,基于预训练模型的词向量相当于迁移了整个语义空间的知识,往往能得到更好的性能。目前应用的比较广泛的预训练模型有Word2Vec 和GloVe 等。它们已经在海量语料库训练得到了较好的词向量表示方法,并可以直接导出学习到的词向量表,方便迁移到其它任务。
那么如何使用这些预训练的词向量模型来帮助提升NLP 任务的性能?非常简单,对于Embedding 层,不再采用随机初始化的方式,而是利用我们已经预训练好的模型参数去初始化 Embedding 层的查询表。
# 从预训练模型中加载词向量表
embed_glove = load_embed('glove.6B.50d.txt')
# 直接利用预训练的词向量初始化Embedding层
net.set_weights([embed_glove])
经过预训练的词向量模型初始化的Embedding 层可以设置为不参与训练:net.trainable= False,那么预训练的词向量就直接应用到此特定任务上;如果希望能够学到区别于预训练词向量模型不同的表示方法,那么可以把Embedding 层包含进反向传播算法中去,利用梯度下降来微调单词表示方法。
三、单层RNN与多层RNN
1.单层RNN
在tensorflow2的框架下,SimpleRNN层可以用keras.SimpleRNN或keras.SimpleRNNCell来表示,keras.SimpleRNN是高级的封装类不需要了解rnn的原理便可以使用,keras.SimpleRNNCell是较接近底层的类需要自己去更新out和state,我们先使用keras.SimpleRNNCell

import tensorflow as tf
from tensorflow.keras import layers
x = tf.random.normal([4, 80, 100])
x_t0 = x[:, 0, :]
# 单层RNN
cell = layers.SimpleRNNCell(64)
out, h_t1 = cell(x_t0, [tf.zeros([4, 64])])
print(out.shape, h_t1[0].shape)
# (4, 64) (4, 64)
print(id(out), id(h_t1[0]))
# 2254557618416 2254557618416
print(cell.trainable_variables)
# W_xh
[<tf.Variable 'simple_rnn_cell/kernel:0' shape=(100, 64) dtype=float32, numpy=
array([[ 0.1363651 , -0.0572269 , 0.09445526, ..., -0.1507045 ,
0.01126893, 0.17339201],
[ 0.02856255, 0.15180282, -0.12121101, ..., 0.0886908 ,
-0.08678336, 0.04887807],
[ 0.18207397, -0.17674726, 0.07250978, ..., -0.01544967,
-0.08867019, -0.11385597],
...,
[-0.09959508, -0.11128702, -0.05792001, ..., -0.12493751,
-0.05981992, -0.15802671],
[-0.03608645, 0.05136161, 0.11901782, ..., -0.05900815,
-0.18590759, -0.06727251],
[-0.00414591, -0.06272078, -0.11666548, ..., 0.05222301,
0.11370294, 0.1058446 ]], dtype=float32)>,
# W_hh
<tf.Variable 'simple_rnn_cell/recurrent_kernel:0' shape=(64, 64) dtype=float32, numpy=
array([[-1.44636631e-01, -2.41715163e-01, -1.37400955e-01, ...,
3.06779407e-02, -9.32328403e-03, 2.50178762e-03],
[ 8.62338617e-02, 8.57626200e-02, -1.92453608e-01, ...,
1.54805947e-02, 7.17535755e-03, 3.00482392e-01],
[ 1.59917727e-01, 2.43820846e-01, -2.19721437e-01, ...,
-1.06618486e-01, -1.92755729e-01, 8.41443986e-03],
...,
[-3.65341753e-02, -7.74926841e-02, -4.81767319e-02, ...,
1.70781165e-01, 8.75974596e-02, -1.19888894e-01],
[ 2.20960930e-01, 1.79074965e-02, 3.92574295e-02, ...,
-1.50801331e-01, 1.14356488e-01, -8.91658291e-02],
[-2.05543414e-01, 1.13110356e-01, 1.79518014e-04, ...,
-4.87414822e-02, -9.71178561e-02, -8.35660249e-02]], dtype=float32)>,
# b
<tf.Variable 'simple_rnn_cell/bias:0' shape=(64,) dtype=float32, numpy=
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1126
1126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









