







目录
1.导入包
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.feature.{IndexToString, StringIndexer, VectorIndexer}
import org.apache.spark.ml.classification.DecisionTreeClassificationModel
import org.apache.spark.ml.classification.DecisionTreeClassifier
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator2.导入数据并创建DataFrame
object DecisionTreeClassificationExampleMl {
case class Iris(features: Vector, label: String) //注意:需写在main外面
def main(args: Array[String]): Unit = {
//!!!注意:如果在Windows上执行,指定Hadoop的Home
System.setProperty("hadoop.home.dir", "D:\\temp\\hadoop-2.4.1\\hadoop-2.4.1")
//不打印日志
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
// 创建sparksession对象
val spark = SparkSession.builder()
.master("local")
.appName("DTML")
.getOrCreate()
// 使用case class 创建DataFrame
import spark.implicits._
val data = spark.sparkContext.textFile("D:\\temp\\iris.txt")
.map(_.split(","))
.map(p => Iris(Vectors.dense(p(0).toDouble,p(1).toDouble,p(2).toDouble, p(3).toDouble),p(4))).toDF()
// 需要生成视图,才可执行SQL语句
data.createOrReplaceTempView("iris")
val df = spark.sql("select * from iris")3.划分数据集,定义模型框架
注意:划分数据集的时候如果想每次划分不一样,则不指定seed参数。
//我们把数据集随机分成训练集和测试集,其中训练集占70%。
val Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3), seed=0)
//分别获取标签列和特征列,进行索引。
val labelIndexer = new StringIndexer()
.setInputCol("label")
.setOutputCol("indexedLabel")
.fit(df)
val featureIndexer = new VectorIndexer()
.setInputCol("features")
.setOutputCol("indexedFeatures")
.setMaxCategories(4)
.fit(df)
//将预测的类别转回字符型。
val labelConverter = new IndexToString()
.setInputCol("prediction")
.setOutputCol("predictedLabel")
.setLabels(labelIndexer.labels)
//定义决策树模型。
val dtClassifier = new DecisionTreeClassifier()
.setLabelCol("indexedLabel")
.setFeaturesCol("indexedFeatures")4.用pipline将训练步骤串联,训练模型
//在pipeline中进行设置
val pipelinedClassifier = new Pipeline()
.setStages(Array(labelIndexer, featureIndexer, dtClassifier, labelConverter))
//训练决策树模型
val modelClassifier = pipelinedClassifier.fit(trainingData)5.在测试集上预测,查看部分结果
//进行预测
val predictionsClassifier = modelClassifier.transform(testData)
//查看部分预测的结果
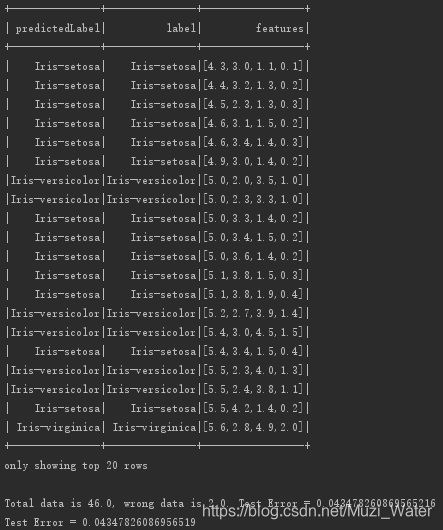
predictionsClassifier.select("predictedLabel", "label", "features").show(20)6.评估模型,打印树模型
/*
* 评估模型的两种写法,一种自己算,另一种调用MulticlassClassificattionEvaluator,推荐第二种
* */
// Evaluate model on test instances and compute test error
val testErr = predictionsClassifier.filter($"predictedLabel" !== $"label").count().toDouble
val all = testData.count().toDouble
println("Total data is " + all + ", wrong data is "+ testErr + ". Test Error = " + testErr/all)
// 推荐下面这种方法
// Select (prediction, true label) and compute test error.
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("indexedLabel")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy = evaluator.evaluate(predictionsClassifier)
println("Test Error = " + (1.0 - accuracy))
// print DecisionTree classification model
val dtModel = modelClassifier.stages(2).asInstanceOf[DecisionTreeClassificationModel]
println("Learned classification tree model:\n" + dtModel.toDebugString)
spark.stop()
}
}7.运行结果
















 7917
7917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









