







1. 简介
- 参考论文:Deep Face Recognition: A Survey
- 人脸识别发展史

- 深度学习概念

1.1 人脸识别步骤
- 人脸检测
- 人脸预处理:人脸关键点检测 + 人脸矫正
- 人脸表示:提取具有较好表达能力的特征向量
- 特征比对/特征匹配
1.2 网络模型
- 网络结构
- DeepFace
- DeepID
- VGGFace
- VGGFace2
- FaceNet
- CenterLoss
- 损失函数
- 基于欧几里德距离的损失 (Euclidean distance based loss)
- 基于角度/余弦边界的损失(Angular/cosine-margin-based loss)
- softmax 损失(Softmax 损失)
- 数据集
- LFW
- IJB-A/B/C
- Megaface
- MSCeleb-1M
2. 人脸识别组件(Components of Face Recognition)
- 人脸检测器(Face Detector):定位人脸在图像中的位置
- 人脸关键点检测器(facial landmark detector):人脸与归一化坐标系对齐
- 人脸识别使用这些对齐的人脸图像实现

2.1 判别损失函数的发展史


- 基于欧几里德距离的损失 (Euclidean-distance-based Loss)
- 对比损失(contrastive loss)
- 三重损失(triplet loss)
- 中心损失(center loss)
- 基于角度/余弦余量的损失 (Angular/cosine-margin-based Loss)
-
种类
- L-Softmax
- A-Softmax
-
在softmax损失中的决策边界
( W 1 − W 2 ) x + b 1 − b 2 = 0 (W_1 - W_2)x + b_1 - b_2 = 0 (W1−W2)x+b1−b2=0- x x x:特征向量(feature vector)
- W i W_i Wi:权重
- b i b_i bi:偏差
-
损失函数定义如下:

- m m m:是一个正整数,用于引入角余量
- θ i \theta_i θi:是权重 W i W_i Wi与特征向量 x x x间的夹角
-
决策边界

-
二者比较
-
基于余弦边际的损失:明确地在超球面流形上增加了判别约束,这在本质上与人脸位于流形上的先验相匹配

-
基于余弦边际的损失:在干净的数据集上获得更好的结果,但容易受到噪声的影响,在高噪声区域变得比中心损失和 softmax 更差

-
-
2.2 网络结构的发展史
2.2.1 主干网络 (Backbone Network)
- 主流架构 (Mainstream architectures)


- 轻量级网络 (Light-weight networks)
- MobiFace
- SqueezeNet
- MobileNet
- ShffleNet
- Xception
- 自适应架构网络 (Adaptive-architecture networks)
- NAS: Neural Architecture Search
- c-CNN:Conditional Convolutional Neural Network
- 联合对齐识别网络 (Joint alignment-recognition networks)
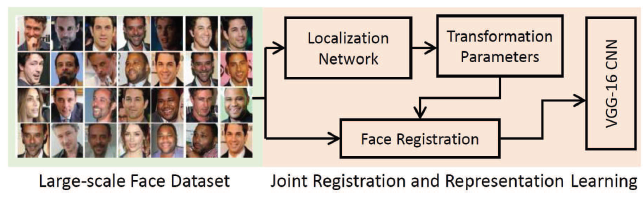
2.2.2 组合网络 (Assembled Networks)
- 多输入网络(Multi-input networks)
- 在“一对多增强”中,从一张图像生成多张具有多样性的图像以增强训练数据
- 以多幅图像作为输入,多个网络也被组合在一起,以提取和组合不同输入类型的特征,这可以胜过单个网络
- 多视图深度网络(MvDN)由特定视角子网络和公共子网络组成; 前者去除特定视角的变化,后者获得了共同的表示
- 多任务网络(Multi-task networks)
- 人脸识别与姿势(pose)、光照(illumination)、年龄(age)等多种因素交织在一起
- 为了解决这个问题,引入了多任务学习来从其他相关任务中转移知识并解开滋扰因素
- 特定任务的子网络被专用于学习人脸检测、人脸对齐、姿态估计、性别识别、微笑检测、年龄估计和 人脸识别

2.2.3 通过深度特征进行人脸匹配 (Face Matching by deep features)
- 测试步骤:
- 第一步:采用余弦距离和L2距离来衡量深度特征 x 1 x_1 x1和 x 2 x_2 x2之间的相似度
- 第二步:阈值比较和最近邻(NN)分类器用于做出验证和识别的决策
- 人脸验证(Face verification)
- 人脸识别(Face identification)
2.3 人脸处理(为训练和识别)
2.3.1 一对多增强 (One-to-Many Augmentation)
- “一对多增强”:可以减轻数据收集的挑战,它们不仅可以用来扩充训练数据,还可以用来扩充测试数据库。 我们将它们分为四类:
- 数据增强
- 光度变换
- 几何变换:如过采样(通过在不同尺度裁剪获得的多个补丁)、镜像 和旋转图像。
- 3D 模型
- 自动编码器模型
- GAN 模型
- 数据增强
2.3.2 多对一归一化(Many-to-One Normalization)
- “多对一归一化”:产生正面人脸并减少测试数据的外观可变性,使人脸对齐且易于比较。
- 包括以下几种类型:
-
自动编码器模型
- 自编码器模型通过编码器学习姿势不变的人脸表示,并通过没有姿势代码的解码器直接对人脸进行归一化
-
CNN 模型
- CNN 模型通常直接学习非正面人脸图像和正面图像之间的 2D 映射,并利用这些映射对像素空间中的图像进行归一化
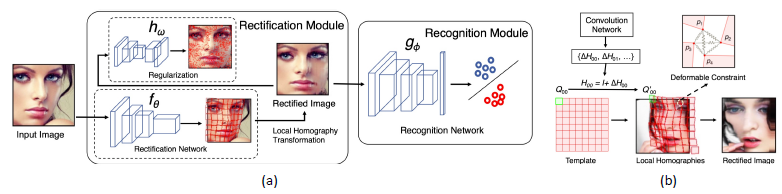
- CNN 模型通常直接学习非正面人脸图像和正面图像之间的 2D 映射,并利用这些映射对像素空间中的图像进行归一化
-
GAN 模型

-
3. 数据集
- 数据集

- 数据集说明

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









