import os
import dlib
import cv2
if not os.path.exists('test'):
os.makedirs('test')
f =open('images.txt','w')
detector = dlib.get_frontal_face_detector()
root ='images'for i in os.listdir(root):
img = cv2.imread(os.path.join(root, i))if img is None:continue
dets =detector(img,0)print(i)for j inrange(len(dets)):
rect = dets[j]
im = img[rect.top():rect.bottom(),rect.left():rect.right()]if im is None:continue
cv2.imwrite('test/{}_{}.jpg'.format(i.split('.')[0],j), im)
f.write('test/{}_{}.jpg\n'.format(i.split('.')[0],j))
f.close()
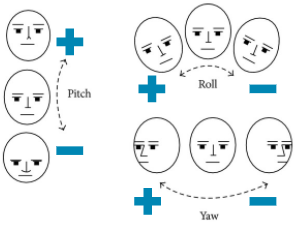
欧拉角计算
import cv2
import numpy as np
import dlib
import time
import math
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("./shape_predictor_68_face_landmarks.dat")POINTS_NUM_LANDMARK=68
def _largest_face(dets):iflen(dets)==1:return0
face_areas =[(det.right()-det.left())*(det.bottom()-det.top())for det in dets]
largest_area = face_areas[0]
largest_index =0for index inrange(1,len(dets)):if face_areas[index]> largest_area :
largest_index = index
largest_area = face_areas[index]print("largest_face index is {} in {} faces".format(largest_index,len(dets)))return largest_index
def get_image_points_from_landmark_shape(landmark_shape):
image_points = np.array([(landmark_shape.part(30).x, landmark_shape.part(30).y), # Nose tip
#(landmark_shape.part(8).x, landmark_shape.part(8).y), # Chin(landmark_shape.part(36).x, landmark_shape.part(36).y), # Left eye left corner(landmark_shape.part(45).x, landmark_shape.part(45).y), # Right eye right corne(landmark_shape.part(48).x, landmark_shape.part(48).y), # Left Mouth corner(landmark_shape.part(54).x, landmark_shape.part(54).y) # Right mouth corner
], dtype="double")return image_points
def get_image_points(img):
dets =detector( img,0)if0==len( dets ):print("ERROR: found no face")return-1, None
largest_index =_largest_face(dets)
face_rectangle = dets[largest_index]
landmark_shape =predictor(img, face_rectangle)returnget_image_points_from_landmark_shape(landmark_shape),face_rectangle
def get_euler_angle(img):
size=img.shape
image_points,rect =get_image_points(img)print(image_points)print(image_points[0][0],image_points[0][1])
cv2.circle(img,(int(image_points[0][0]),int(image_points[0][1])),3,(0,0,255),-1)
cv2.circle(img,(int(image_points[1][0]),int(image_points[1][1])),3,(0,0,255),-1)
cv2.circle(img,(int(image_points[2][0]),int(image_points[2][1])),3,(0,0,255),-1)
cv2.circle(img,(int(image_points[3][0]),int(image_points[3][1])),3,(0,0,255),-1)
cv2.circle(img,(int(image_points[4][0]),int(image_points[4][1])),3,(0,0,255),-1)
model_points =np.array([(0.0,0.0,0.0), # Nose tip
#(0.0,-330.0,-65.0), # Chin(-165.0,170.0,-135.0), # Left eye left corner(165.0,170.0,-135.0), # Right eye right corne(-150.0,-150.0,-125.0), # Left Mouth corner(150.0,-150.0,-125.0) # Right mouth corner
])
# Camera internals
center =(size[1]/2, size[0]/2)
focal_length = center[0]/ np.tan(60/2* np.pi /180)
camera_matrix = np.array([[focal_length,0, center[0]],[0, focal_length, center[1]],[0,0,1]], dtype ="double")
dist_coeffs = np.zeros((4,1)) # Assuming no lens distortion(success, rotation_vector, translation_vector)= cv2.solvePnP(model_points, image_points,
camera_matrix, dist_coeffs, flags=cv2.SOLVEPNP_ITERATIVE)
axis = np.float32([[400,0,0],[0,400,0],[0,0,400]])
imgpts, jac = cv2.projectPoints(axis, rotation_vector, translation_vector, camera_matrix, dist_coeffs)
modelpts, jac2 = cv2.projectPoints(model_points, rotation_vector, translation_vector, camera_matrix, dist_coeffs)
rvec_matrix = cv2.Rodrigues(rotation_vector)[0]
proj_matrix = np.hstack((rvec_matrix, translation_vector))
eulerAngles = cv2.decomposeProjectionMatrix(proj_matrix)[6]
pitch, yaw, roll =[math.radians(_)for _ in eulerAngles]print(pitch, yaw, roll)
pitch = math.degrees(math.asin(math.sin(pitch)))
roll =-math.degrees(math.asin(math.sin(roll)))
yaw = math.degrees(math.asin(math.sin(yaw)))return imgpts, modelpts,(pitch, roll, yaw),image_points[0],rect
if __name__ =='__main__':
im = cv2.imread('face.png')
imgpts, modelpts,rotation,nose,rect=get_euler_angle(im)
nose=tuple(int(i)for i in nose)
cv2.line(im, nose,tuple(int(i)for i in imgpts[1].ravel()),(0,255,0),3) #GREEN
cv2.line(im, nose,tuple(int(i)for i in imgpts[0].ravel()),(255,0,),3) #BLUE
cv2.line(im, nose,tuple(int(i)for i in imgpts[2].ravel()),(0,0,255),3) #RED
#print(rotation)
b, g, r = cv2.split(im)
im = cv2.merge([r, g, b])import matplotlib.pyplot as plt
text='pitch:{:.0f}\n roll:{:.0f}\n yaw:{:.0f}'.format(rotation[0],
rotation[1],rotation[2])print(text)
plt.text(10,50,text,color='r',fontsize=10)
plt.imshow(im)
plt.show()
























 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









