







Mybatis最大的好处就是封装了JDBC,减少了50%y以上的JDBC代码量,提供Java中POJOs与数据库之间的映射,在配置文件Mapper.xml中就可以使用SQL语句,消除了sql语句与程序代码之间的耦合。
那么接下来作为新手,我通过查资料学习,总结Mappper.xml配置文件的认识。
认识Mapper文件中的元素
1.映射文件节点元素构成
是以<mapper>...</mapper>作为根节点,在根节点中有9个元素,如下图在Ecplise截图所示:
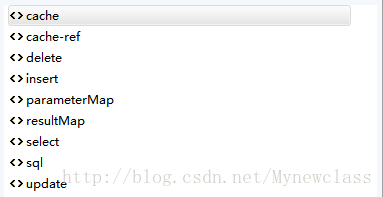
分别为:
1.<sql>...</sql>
2.<cache>...</cache>
3.<cache-ref>...</cache-ref>
4.<parameterMap>...</parameterMap>
5.<resultMap>...</resultMap>
6.<select>...</select>
7.<update>...</update>
8.<delete>...</delete>
9.<insert>...</insert>其中6、7、8、9就是sql语句中的增删改查,非常容易理解
2.映射文件元素的作用
- cache : 配置给定命名空间的缓存。
Mybatis相比较Hibernate还有一个强大的缓存机制, 可以使我们很方便配置与定制。缓存机制主要分为一级缓存与二级缓存。
一级缓存:默认情况下Mybatis是没有开启缓存的,是默认session缓存机制的,当session关闭close或者flush刷新以后,在作用域session中所有cache将会清空。
二级缓存:需要在配置映射文件中加下面的语句
<cache/>这样就可以实现二级缓存,关于二级缓存的属性,如下所示:
<cache
<!--使用FIFO(先进先出)算法来缓存,默认的是LRU(最近使用最少算法)-->
eviction="FIFO"
<!--每隔60m刷新一次缓存-->
flushInterval="60000"
<!--缓存会存储列表对象或者集合的512个引用,默认为1024个-->
size="512"
<!--返回的对象只读状态-->
readOnly="true"/>除此之外,当然也可以进行自定义缓存,但是具体的我目前还没进一步加深学习,还没理解透。
- cache-ref : 从其他命名空间引用缓存配置。
当你想在namespace命名空间中共享某个相同的缓存机制或者实例,就可以使用cache-ref
<cache-ref namespace="com.xxxx.xxxx"/>- resultMap :主要是当对数据库进行负责的联合查询,一对多的情况时候返回的数据类型。
Mybatis中进行select查询以后,返回的类型通常分为resultType与resultMap。resultType是直接返回的类型,resultMap是高级结果映射,但resultMap与resultType只能在其中用一个。
resultMap通常用于下列的情况:比如每个学生都有自己的课程安排表student_course,也有自己的兴趣爱好student_hobby。
--表一:student
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`age` int(3) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8;
--表二:student_course
CREATE TABLE `student_course` (
`course_id` varchar(11) DEFAULT NULL,
`course_name` int(11) DEFAULT NULL
`course_time` int(11) DEFAULT NULL
PRIMARY KEY (`course_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
--表三:student_hobby
CREATE TABLE `student_hobby` (
`hobby_id` varchar(255) NOT NULL,
`hobby_name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`hobby_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8; 我们需要通过student的id查找到学生的兴趣爱好与课程,这时候就用到resultMap配置了。如下实例代码配置resultMap:
<span style="font-family:KaiTi_GB2312;font-size:18px;"><resultMap type="" id="">
<!-- id, 唯一性,这个id用于标示这个javabean对象的唯一性, 不一定会是数据库的主键
property属性对应javabean的属性名,column对应数据库表的列名
(这样,当javabean的属性与数据库对应表的列名不一致的时候,就能通过指定这个保持正常映射了)
-->
<id property="" column=""/>
<!-- result与id相比, 对应普通属性 -->
<result property="" column=""/>
<!--
constructor对应javabean中的构造方法
-->
<constructor>
<!-- idArg 对应构造方法中的id参数 -->
<idArg column=""/>
<!-- arg 对应构造方法中的普通参数 -->
<arg column=""/>
</constructor>
<!--
collection,对应javabean中容器类型, 是实现一对多的关键
property 为javabean中容器对应字段名
column 为体现在数据库中列名
ofType 就是指定javabean中容器指定的类型
-->
<collection property="" column="" ofType=""></collection>
<!--
association 为关联关系,是实现N对一的关键。
property 为javabean中容器对应字段名
column 为体现在数据库中列名
javaType 指定关联的类型
-->
<association property="" column="" javaType=""></association>
</resultMap></span>parameterMap :目前已经不用了不,不做学习记录
sql : 可以重用的 SQL,如列名、字段名、表名、字段值等。
<!--表名 -->
<sql id="tableName">
sc_student
</sql>
<!-- 字段 -->
<sql id="Field">
STUDENT_ID,
NAME,
AGE,
BIRTHDAY
</sql>
<!-- 字段值 -->
<sql id="FieldValue">
#{STUDENT_ID},
#{NAME},
#{AGE},
#{BIRTHDAY}
</sql>
通过使用<include refid="" />标签引用,refid=”” 中的值指向需要引用的<sql>中的id=“”属性,可以重复使用sql
<include refid="tableName">
<include refid="Field"></include>
<include refid="FieldValue"></include>- insert : 映射插入语句
- update : 映射更新语句
- delete –:映射删除语句
select: 映射查询语句
insert、update、delete、select标签用法相类似,都可以使用动态的sql语句
<mapper namespace="com.majing.learning.mybatis.dao.UserDao">
<insert id="addUser" parameterType="student" useGeneratedKeys="true" keyProperty="id">
insert into user(name,password,age) values(#{id},#{name},#{age})
</insert>
<delete id="deleteUser" parameterType="int">
delete from student where id = #{id}
</delete>
<update id="updateUser" parameterType="user" >
update student set name = #{name}, name= #{name}, age = #{age} where id = #{id}
</update>
</mapper> 这相当于可以理解为:JDBC中的预处理代码,标签中的id就是pst
String sql="insert into stduent(id,name,age) values(?,?,?)";
PreparedStatement pst=con.prepareStatement(sql);
pst.executeUpdate();















 5262
5262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









