







一、搭建执行hudi的平台
1.1、整体软件架构

1.2、安装Hadoop(当前环境是hadoop2.7)............
1.3、安装 Spark(当前环境是3.x)
第一步、安装Scala-2.12.10
##解压scala
tar -zxvf scala-2.12.10.tgz -C /opt/module
##设置Scala的环境变量
vim /etc/profile
###添加如下
#SCALA_HOME
export SCALA_HOME=/opt/module/scala-2.12.10
export PATH=$PATH:$SCALA_HOME/bin查看Scala是否安装成功

第二步、修改spark的配置文件
##解压spark包spark-3.0.0-bin-hadoop2.7.tgz
tar -zxvf spark-3.0.0-bin-hadoop2.7.tgz -C /opt/module
##修改conf/spark-env.sh
##添加如下
JAVA_HOME=/opt/module/jdk1.8.0_144
SCALA_HOME=/opt/module/scala-2.12.10
HADOOP_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop第三步、本地模式启动spark-shell读取hdfs数据
bin/spark-shell local[2]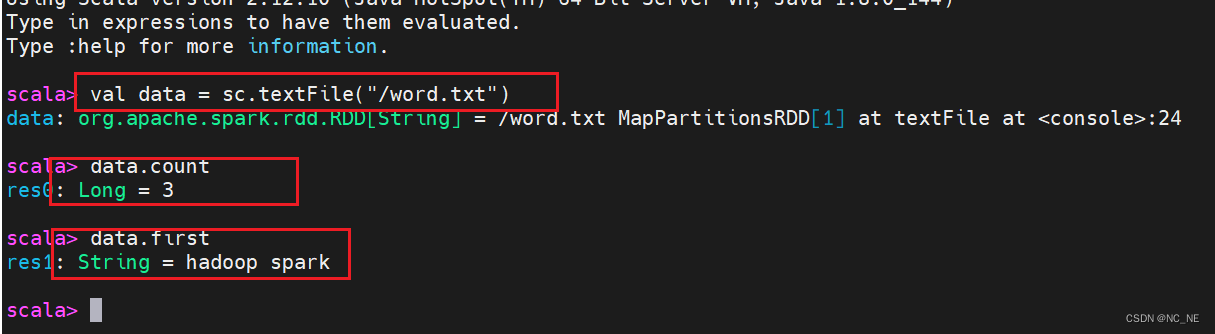
1.4、测试hudi-0.9.0
编译好的hudi下载
链接:https://pan.baidu.com/s/11hhmyZCiQxNRTv-ND_-Chw
提取码:bio5 ./hudi-cli.sh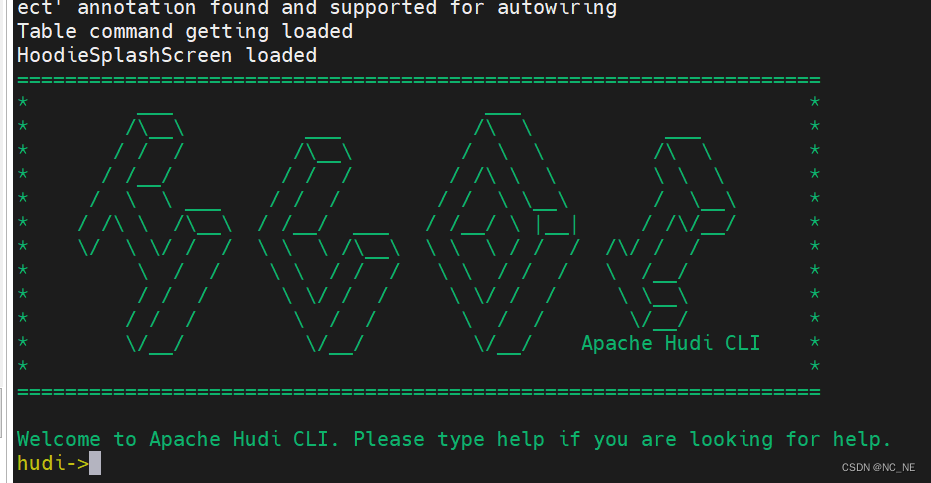
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1099
1099











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









