









PostGIS领域分析
此文为《postgis in action3 》的学习翻译记录并做了些删减与补充
1.最邻近搜索
这一节中主要演示常见的多种最近邻近搜索,如:
- 位于A的X距离之内的geom有那些
- 距离A的最近的N个地方的geom有那些
[1]哪些地方在x距离之内
可以使用 ST_DWithin 函数来查找彼此靠近的地点或确定一个地点是否在另一个地点的 X 单位内,还可以地理类型与几何类型混用(不过使用地理类型时是以米未单位,二使用几何类型时是空间参考系统相应的单位)
如下示例使用地理类型查询某点100 公里范围内的机场:
select name,iso_country,iso_region
from ch09.airports
where ST_DWithin(geog,ST_Point(-75.0664, 40.2003)::geography, 100000);
name | iso_country | iso_region
---------------------------------------------------------+-------------+------------
Soaring Sun Seaplane Base | US | US-NJ
Bayonne Golf Club Heliport | US | US-NJ
Highlands Seaplane Base | US | US-NJ
Allen's Seaplane Base | US | US-NJ
Caven Point USAR Center Heliport | US | US-NJ
Ash Personal Heliport | US | US-NJ
Picatinny Army Heliport | US | US-NJ
Morristown Medical Center Heliport | US | US-NJ
Honeywell Heliport | US | US-NJ
Ballymere Heliport | US | US-NJ
Weichert Headquarters Heliport | US | US-NJ
Fla-Net Airport | US | US-NJ
Trinca Airport | US | US-NJ
Cherry Hill Heliport | US | US-NJ
Newton Airport | US | US-NJ
Scheller Airport | US | US-NJ
Newton Memorial Hospital Heliport | US | US-NJ
Colgate-Palmolive/Mennen Heliport | US | US-NJ
Weiss Farm Airport | US | US-NJ
Mianecki Heliport | US | US-NJ
Aeroflex-Andover Airport | US | US-NJ
Hudson Farm West Heliport | US | US-NJ
Hackettstown Community Hospital Heliport | US | US-NJ
Hackettstown Hospital Heliport | US | US-NJ
Florham Park Heliport | US | US-NJ
Soverel Park Heliport | US | US-NJ
Newark Academy Heliport | US | US-NJ
-- More --
[2]使用ST_DWithin和ST_Distance进行最邻近搜索
可以通过修改(添加使用ST_Distance函数)上面的示例来实现查询结果按距离排序
SELECT ident, name
FROM
ch09.airports
CROSS JOIN -- 笛卡尔积交叉连接
(SELECT ST_Point(-75.0664, 40.2003)::geography AS ref_geog) As r
WHERE ST_DWithin(geog, ref_geog, 100000)
ORDER BY ST_Distance(geog, ref_geog) -- 根据已知点距离查询点的距离来排序
LIMIT 5; -- 返回前5个结果
ident | name
-------+-------------------------------------
KNJP | Warminster Naval Air Warfare Center
31PN | Control Dynamics Heliport
PS84 | Warminster Hospital Heliport
5PN7 | Jarrett Airport
5PN4 | Mahon Heliport
(5 行记录)
[2]使用ST_DWithin和 DISTINCT ON 查找最邻近位置
还有一种常见的情况是:从一组地点开始,查找距离另一组地点最近的地点(套了个娃😓,不过在现实生活中还是挺常见的需求),举个例子:在一个主要城市的所有疗养院 10 英里范围内有多少紧急医疗中心。
对于这种情况可以使用组合 ST_DWithin 和 PostgreSQL DISTINCT ON 来实现搜索( DISTINCT ON 执行隐式 GROUP BY,但不限于仅返回您分组的字段)
例如:以下查询查找离每个机场最近的导航工具(交通站点)
SELECT DISTINCT ON (a.ident) -- 对机场去重+排序,以保留实现最近的一个导航工具
a.ident, a.name As airport, n.name As closest_navaid,
(ST_Distance(a.geog,n.geog)/1000)::integer As dist_km
FROM ch09.airports As a LEFT JOIN ch09.navaids As n -- 左连接(以左为基准)
ON ST_DWithin(a.geog, n.geog,100000) -- 距离机场100公里范围内最近的导航工具
ORDER BY a.ident, dist_km;
ident | airport | closest_navaid | dist_km
-------+---------------------------+--------------------+---------
00A | Total RF Heliport | North Philadelphia | 7
00AK | Lowell Field | Homer | 30
00AL | Epps Airpark | Capshaw | 10
00AR | Newport Hospital | Newport | 8
其查找的圆半径越慢,这里查询进入用了4秒多。。。
此查询使用左连接而不是内连接,以确保即使在没有找到导航设备时,查询操作仍然继续进行
[3]带容差的相交
还可以使用ST_DWithin来代替ST_Intersects判断相交关系,其优势有:
当有两个几何因有效位数引起的差异而无法相交时,可以使用ST_DWithin检查相交。例子(忽略0.0001内的容差):
SELECT ST_DWithin(
ST_GeomFromText(
'LINESTRING(1 2, 3 4)'
),
ST_Point(3.00001, 4.000001),
0.0001
);
st_dwithin
------------
true
(1 行记录)
在使用实际的数据时通常会使用带容差的相交,而并非所有数据都完美对齐
使用 ST_DWithin 代替 ST_Intersects 还有一个优势:ST_DWithin 不会像 ST_Intersects 那样经常因为无效几何图形而被阻碍过程,尤其是在几何图形具有自相交区域的情况下。 ST_DWithin 不关心有效性,因为它不依赖于交集矩阵(九交)。
[4]距离范围内的地点
有时候还会有一种情况,当在查询在某些距离范围内的地点(圆环范围)
这时就需要调用两个ST_DWithin来实现了,其主要原理为使用两个ST_DWithin查询俩个范围(一大一小),只要保留大的范围减去小的范围即可。具体示例如下(还是机场表):
SELECT name, iso_country, iso_region
FROM ch09.airports
WHERE ST_DWithin(geog,
ST_Point(-75.0664, 40.2003)::geography, 100000) -- 100公里范围内的机场
AND NOT ST_DWithin(geog,
ST_Point(-75.0664, 40.2003)::geography, 90000); -- 90公里内的机场
name | iso_country | iso_region
---------------------------------------------------------+-------------+------------
Soaring Sun Seaplane Base | US | US-NJ
Bayonne Golf Club Heliport | US | US-NJ
Highlands Seaplane Base | US | US-NJ
Caven Point USAR Center Heliport | US | US-NJ
Ash Personal Heliport | US | US-NJ
Picatinny Army Heliport | US | US-NJ
Weichert Headquarters Heliport | US | US-NJ
Cherry Hill Heliport | US | US-NJ
Newton Airport | US | US-NJ
Newton Memorial Hospital Heliport | US | US-NJ
Mianecki Heliport | US | US-NJ
Aeroflex-Andover Airport | US | US-NJ
Hudson Farm West Heliport | US | US-NJ
Soverel Park Heliport | US | US-NJ
Kennedy Stadium Heliport | US | US-NJ
Smoketown Airport | US | US-PA
Hideaway Ultralightport | US | US-PA
Chem-Fleur Helistop | US | US-NJ
University Hospital Rooftop Heliport | US | US-NJ
...
[5]使用KNN距离操作符查找 N 个最近的点
postgis有关于最邻近搜索(K-nearest neighbor)的两个操作符:
<->- 这是几何geometry和地理geography的 KNN 距离操作符,A <-> B返回两个几何图形 A 和 B 之间的距离<#>- 这是几何geometry的 KNN 边界框距离操作符,A <#> B返回 A 和 B 的边界框之间的最小距离
使用
<->时,两个对象必须都是几何图形或两者都是地理类型,如果与地理进行比较,经度/纬度空间参考系统中的几何图形将自动转换为地理;如果几何图形使用非 lon/lat 空间参考系统,则会出现错误KNN 运算符的行为与常用的重叠运算符 (&&)、ST_Intersects 和其他关系函数非常不同。 KNN 运算符只能在 ORDER BY 子句中使用空间索引,并且当运算符中一侧的对象在查询或子查询的整个生命周期内保持不变时。人们常犯的一个错误是尝试在 WHERE 子句中使用 KNN 运算符,并想知道为什么它们没有获得任何索引速度提升。 KNN 运算符也总是返回数值。这与 &&、ST_Intersects 和其他关系函数不同,它们仅在 WHERE 和 JOIN 子句中使用空间索引,并返回布尔值 true/false
因为 KNN 运算符会输出的是距离,该距离通常还是需要在查询中使用的,因此推荐在 SELECT 子句中使用别名定义它们。在 ORDER BY 子句中使用定义的别名而不是在 ORDER BY 子句中再次重复整个 <-> 时,是仍然可以获得相同的索引提升的
如使用空间索引和别名的最基本的 KNN 示例(离点最近的十个几何图形):
SELECT
pid,
geom
<-> -- return geom 与 point的距离
ST_Transform(
ST_SetSRID(ST_Point(-71.09368, 42.35857),4326)
,26986) AS dist
FROM ch09.land
WHERE land_type = 'apartment'
ORDER BY dist -- 按距离从小到大排序
LIMIT 10;
pid | dist
--------+-------------------
68-74 | 577.6971291679585
48-154 | 606.4853088634092
74-3 | 636.3831678954274
70-98 | 636.8056504490122
44-107 | 653.9337102092323
74-24 | 670.4939392784329
70-97 | 680.0793327608731
92-118 | 693.2394869664229
75-45 | 699.7823017007512
42-68 | 719.1473197030103
(10 行记录)
与其他操作符与函数一样,两个几何的空间参考系统需要是一样的
2.对地理类型使用KNN操作符
对于地理类型,KNN操作符的使用与几何类型类似:
例如:查看距离Boston Logan(一个机场名)最近的十个机场:
SELECT ident, name,
geog <-> (SELECT geog
FROM ch09.airports WHERE ident = 'KBOS') AS dist -- Boston Logan坐标
FROM ch09.airports
WHERE ident != 'KBOS' AND type = 'large_airport' -- 不包括Boston Logan的大型机场
ORDER BY dist
LIMIT 10;
ident | name | dist
-------+---------------------------------------------------------+--------------------
KMHT | Manchester-Boston Regional Airport | 72338.42343183087
KPVD | Theodore Francis Green State Airport | 78161.53094166022
KBDL | Bradley International Airport | 146189.5781946512
KPWM | Portland International Jetport | 153360.8589790108
KLGA | La Guardia Airport | 296692.4314658076
KJFK | John F Kennedy International Airport | 300178.39036616695
KEWR | Newark Liberty International Airport | 322306.6233001464
KBGR | Bangor International Airport | 323308.49386454397
CYUL | Montreal / Pierre Elliott Trudeau International Airport | 408984.0780492237
KSYR | Syracuse Hancock International Airport | 424727.654195591
(10 行记录)
[1]使用窗口函数对最近的N个地点进行编号
在前面的示例中仅仅对查询的最邻近的地点进行了排序,并没有对其进行排序,有时候对其进行编号也是很有用的。
这时便可以使用 row_number(), rank(), dense_rank()等窗口函数对行进行编号了,窗口函数(也叫OLAP函数(Online Anallytical Processing,联机分析处理)是一种可以查看查询的整个数据集并提供与其在数据中的位置相关的信息的函数。
窗口函数语法:
select <窗口函数> over (partition by <用于分组的列名>
order by <用于排序的列名> ) -- 默认为asc
示例:(查询每所学校 100 米范围内的道路,并根据道路距学校的距离对这些道路进行编号)
SELECT
pid, rnum, -- pid为学校的唯一标识符
rank, drank,
road_name,
round(CAST(dist_km As numeric),2) As dist_km
FROM (
SELECT
ROW_NUMBER() OVER w_dist As rnum,
RANK() OVER w_dist AS rank,
DENSE_RANK() OVER w_dist AS drank, -- 不同窗口函数
E.pid, E.road_name,
E.dist_km
FROM
(SELECT l.pid,
round((r.geom <-> l.geom)::numeric/1000,2) As dist_km
FROM ch09.land As l -- 地点表
LEFT JOIN -- 即使在 100 米范围内没有道路,也可以输出学校信息
ch09.road As r -- 道路表
ON ST_DWithin(r.geom,l.geom,100)
WHERE l.land_type = 'education'
AND l.pid LIKE '143-1%') AS E
WINDOW w_dist AS (PARTITION BY E.pid ORDER BY e.dist_km) -- 定义要在 OVER 中使用的 WINDOW 子句
) As X
WHERE X.drank < 3 -- 仅返回2条最近的道路
ORDER BY pid, rnum;
pid | rnum | rank | drank | road_name | dist_km
--------+------+------+-------+------------------+---------
143-10 | 1 | 1 | 1 | CAMBRIDGE STREET | 0.01
143-11 | 1 | 1 | 1 | CAMBRIDGE STREET | 0.01
143-11 | 2 | 2 | 2 | QUINCY STREET | 0.06
143-11 | 3 | 2 | 2 | CAMBRIDGE STREET | 0.06
143-11 | 4 | 2 | 2 | CAMBRIDGE STREET | 0.06
143-13 | 1 | 1 | 1 | KIRKLAND STREET | 0.01
143-13 | 2 | 2 | 2 | QUINCY STREET | 0.07
143-15 | 1 | 1 | 1 | CAMBRIDGE STREET | 0.06
143-15 | 2 | 2 | 2 | KIRKLAND STREET | 0.09
143-17 | 1 | 1 | 1 | CAMBRIDGE STREET | 0.01
143-17 | 2 | 1 | 1 | QUINCY STREET | 0.01
143-17 | 3 | 3 | 2 | BROADWAY | 0.02
143-17 | 4 | 3 | 2 | KIRKLAND STREET | 0.02
143-17 | 5 | 3 | 2 | CAMBRIDGE STREET | 0.02
对于结果的观察可以发现这几个窗口函数带来的便利:
row_number():对返回的结果中按照某一行创建一个字段来存储排序序号(如上rnum,partition by pid)rank():实际上是对row_number的扩展吧,把dist_km中相同的并为同一个排序号dense_rank():对rank()的在扩展,如上面143-17,的rank和drank列就可以发现dense_rank()是对rank()合并后的行进行再排序。
3.地理注记Geotagging
地理标记是指一类空间技术,这通常有两种形式:
- 区域标记:使用一个注记来标注一个几何体(例如使用区域的名称(州、市)来标注一个几何体)
- 线性参考:对线使用的一种标记
区域标记和线性参考是GIS空间分析冲常用的技术,例如,假设你有一个加利福尼亚州所有麦当劳店的列表,并且你有一个所有县的表作为几何图形。区域地理注记可以尝试找出哪些县包含哪些麦当劳,以便你可以轻松获得每个县的麦当劳数量。相反,如果你有加利福尼亚州所有主要高速公路的列表,则线性参考可以找出哪些高速公路在路边有哪些麦当劳店(这只是使用线性参考的一种情况,更多常见的情况https://www.jianshu.com/p/4916b85bea65)
[1]将数据标记到特定区域
空间数据库更常见的用途之一是标记区域。通常,您会将空间区域命名为多边形或多多边形。这些可能是政治区、销售区、市或其他任何地方。
下面看一个基于 airports 表的示例。加入你想要查找并存储所有机场的时区。而时区区域将表为多面体表 (ch09.tz_world),那么对于每个机场,需要先根据机场的坐标找到它所在的时区多面体,并将其时区设置为该区域的时区值。以下示例使用相应时区多面体中的时区值更新机场的时区字段
ch09.tz_world
ALTER TABLE ch09.airports ADD COLUMN IF NOT EXISTS tz varchar(30); -- 添加一个时区列
UPDATE ch09.airports
SET tz = t.tzid
FROM ch09.tz_world As t
WHERE ST_Intersects(ch09.airports.geog, t.geog); -- 机场点于时区多边形相交处
这样,要显示每个机场的当前本地时间的,就可以直接使用内置的 PostgreSQL 时区函数与根据您tz列指定的时区来计算了
SELECT ident, name, CURRENT_TIMESTAMP AT TIME ZONE tz AS ts_at_airport
FROM ch09.airports
WHERE ident IN('KBOS','KSAN','LIRF','OMDB','ZLXY');
ident | name | ts_at_airport
-------+-----------------------------------------------------+----------------------------
KBOS | General Edward Lawrence Logan International Airport | 2022-11-15 00:54:41.464544
KSAN | San Diego International Airport | 2022-11-14 21:54:41.464544
LIRF | Leonardo da Vinci–Fiumicino Airport | 2022-11-15 06:54:41.464544
OMDB | Dubai International Airport | 2022-11-15 09:54:41.464544
ZLXY | Xi'an Xianyang International Airport | 2022-11-15 13:54:41.464544
(5 行记录)
[2]线性参考:将点捕捉到最近的线串
一种常见的线性参考形式为将最近线串上的最近点返回到参考点。这种线性参考通常被称为捕捉点到最近的线串。从一组点和一组线串开始尝试将每个点与其最近的线串相关联,然后与该线串上的最近点相关联
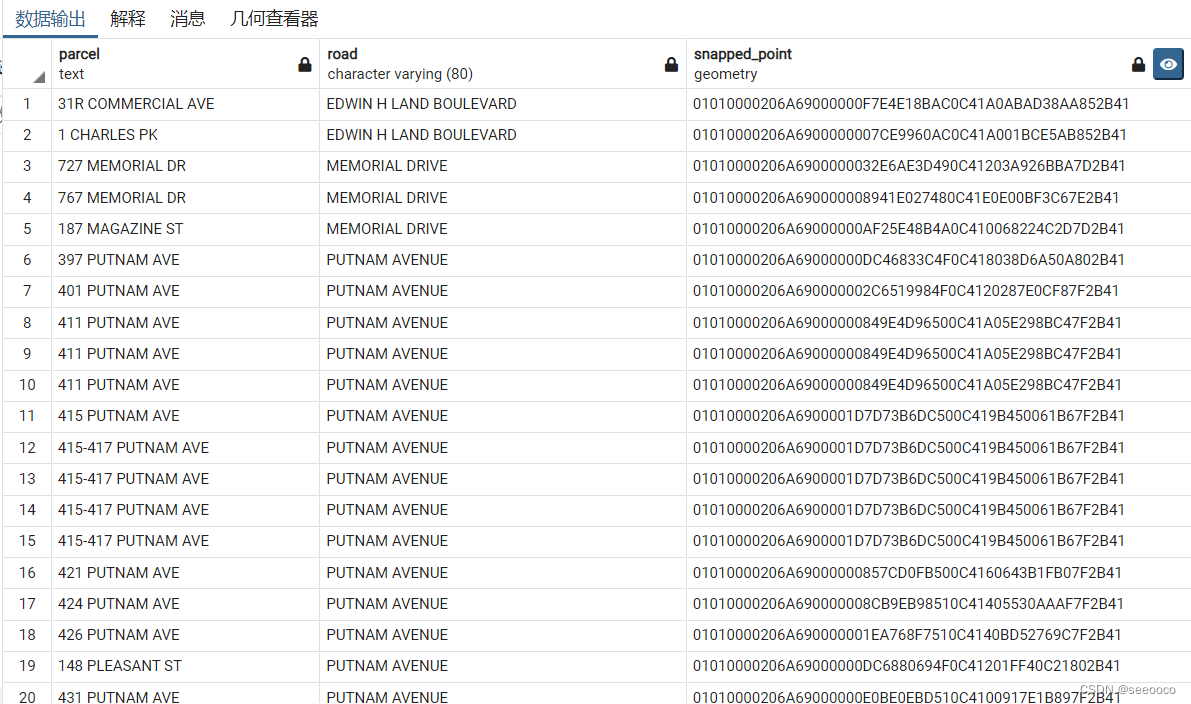
SELECT DISTINCT ON (p.pid) -- 只保留最近的地块和道路对
p.addr_num || ' ' || full_str AS parcel,
r.road_name AS road,
ST_ClosestPoint(p.geom,r.geom) As snapped_point -- return点到直线最近的点(直线上)
FROM ch09.land AS p INNER JOIN ch09.road AS r
ON ST_DWithin(p.geom,r.geom,20.0) -- 仅在land与road20米范围内生成
ORDER BY p.pid, ST_Distance(p.geom,r.geom);
ST_ClosestPoint(geometry A, geometry B):在点与线串之间的最接近是点本身,但是在线条和点之间的最接近的点是线字符串上最接近的点。其他情况,则是多边形A到多边形B上最近的点(生成)
[3]PostGIS空间聚合窗口函数
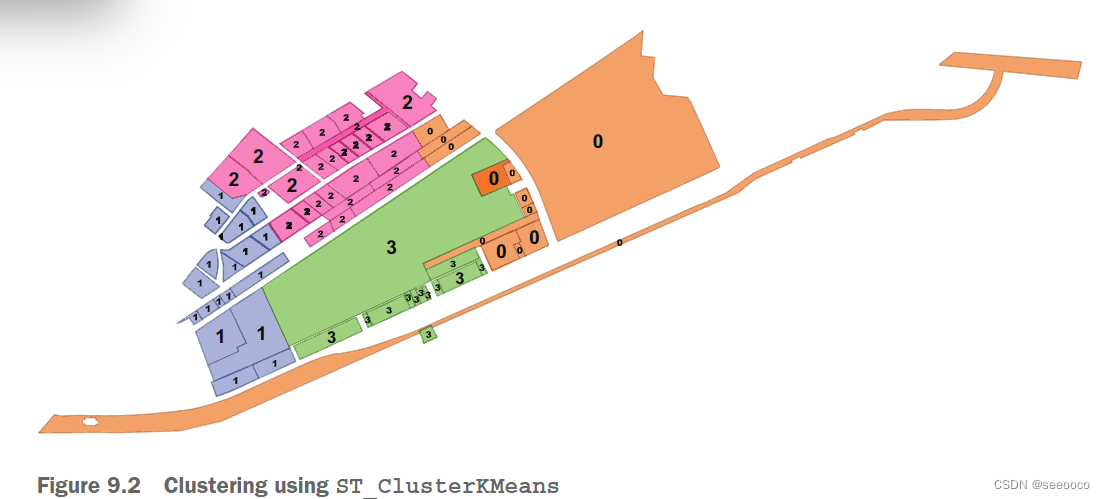
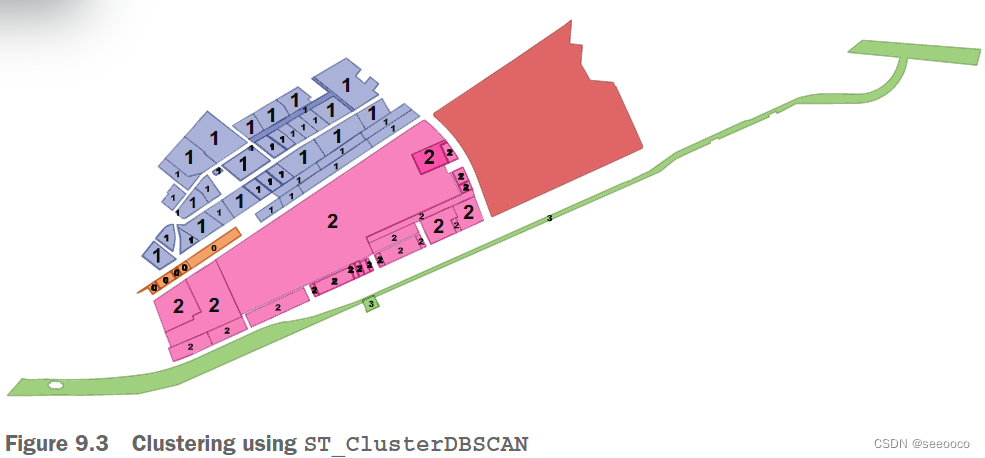
PostGIS 2.3 推出了第一个特定于 PostGIS 的窗口函数:ST_ClusterDBSCAN 和 ST_ClusterKMeans
这些空间聚合窗口函数可以根据几何对象彼此的接近程度将它们聚集在一起。
这里举一个示例:假如现在有一批医护人员要根据地址对需要的人进行疫苗注册,那么确保给他们分配的地址数量均匀且不会太离散。这时就可以发挥postgis空间聚合函数的作用了,它可以将数据集划分为多个块,其中每个块代表一组接近程度高的事物。该窗口函数返回簇号(cluster number),具有相同族号的记录将代表应分配给特定员工的一批地址
integer ST_ClusterKMeans(geometry geom_of_clusters, integer number_of_clusters);需要传入将数据分成的聚类数量,它会使用此数量根据与集合中其他行的接近程度将聚类分配给记录。integer ST_ClusterDBSCAN(geometry geom, float8 eps, integer minpoints)不需要指定多个簇。 一个划定距离,在这一距离内得几何将被划为一个族,,另外还有一个minpoints数,就是你希望一个聚类中最少的成员数
这两种聚类窗口函数的使用示例:
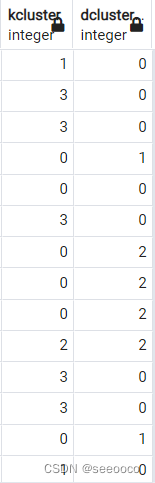
SELECT p.pid, p.geom,
COALESCE(p.addr_num || ' ','') || full_str AS address,
ST_ClusterKMeans(p.geom, 4) OVER() AS kcluster, -- 分为4个聚类[0,3]
ST_ClusterDBSCAN(p.geom, 15, 2) OVER() AS dcluster -- 最大距离为15米,每个聚类中至少有2个成员
FROM ch09.land AS p
WHERE ST_DWithin(p.geom,
ST_GeomFromText('POINT(233110 900676)', 26986),
500);
在这两种情况下,选择的指标会产生大约四个聚类















 3173
3173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











