







 本文全面介绍了Java集合框架的各类集合特点及其应用场景,包括List、Set、Queue、Stack、Map等核心接口与其实现类的基本操作、注意事项及效率分析。
本文全面介绍了Java集合框架的各类集合特点及其应用场景,包括List、Set、Queue、Stack、Map等核心接口与其实现类的基本操作、注意事项及效率分析。
Java 集合框架体系汇总
注意:
- 本文引用了大量优质文章,有应用到的部分具赋予链接可直达查看知识点的深入解析。
- 关于涉及代码部分的内容,均按照
Demo + 注解的形式展现,Demo主要涉及基本常用的方法以及一些进阶方法,并在注解中进行分类,读者可以根据注解选取自己需要的部分(但还是建议对整个代码块有一个整体的理解,注解中也标注出了各种容易出现的错误及细节)。
数组:长度固定、只能存储同一种类型(基本/引用类型)
集合:长度可变、可以存储不同类型(只能引用类型)
迭代器:Iterator对象称为迭代器,用于遍历Collection集合中的元素,所有Collection接口的集合类都有一个iterator()方法,返回一个实现Iterator接口的对象。其仅用于遍历集合,本身并不提供承装对象的能力,如果要创建IUterator对象,则必须有一个被迭代的集合。
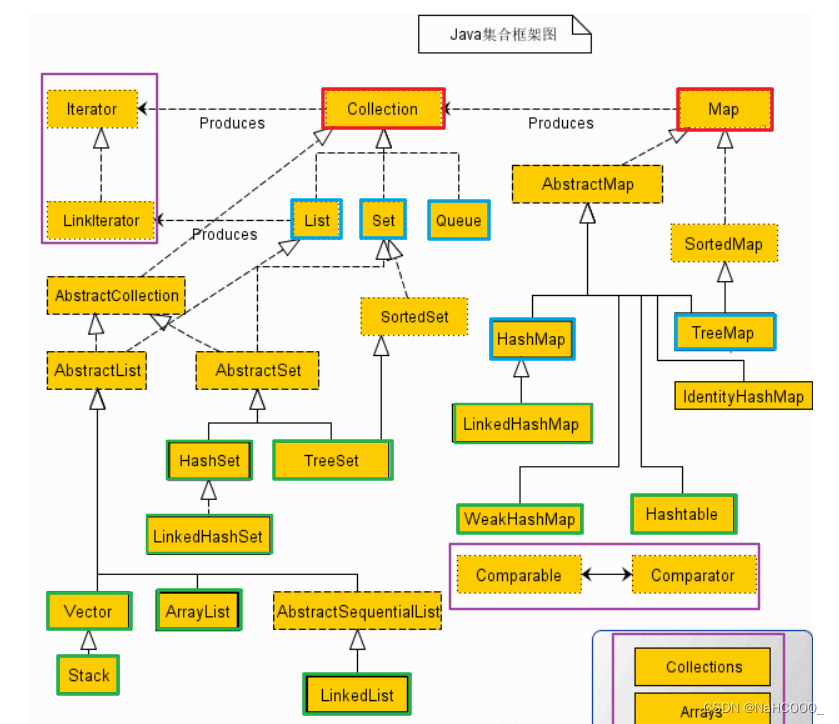
1、Collection
1.1 List
具有顺序的集合,元素可以通过整形下标访问,可以包含重复元素
| 类型 | 底层数据结构 | 线程安全 | 效率 | 使用推荐 |
|---|---|---|---|---|
| ArrayList | 数组 | × | 查询快,增删慢 | √ |
| LinkedList | 双向链表 | × | 查询慢,增删快 | √ |
| Vector | 数组 | √ | 查询快,增删慢,总体效率偏低 | × |
| Stack | 数组 | √ | 先进先出,总体效率低 | × |
ArrayList
-
基本操作
包括构建、增删改查、遍历、排序、去重和其他内置方法。
/** * ArrayList */ public static void ArrayListDemo() { // 1. 构造方法 √ // 无参构造 => 容量为0, 元素个数size默认值0 // public ArrayList() ArrayList<String> arrayStringList = new ArrayList<>(); // 定长构造 => 容量为给定值(小于0会报错), 元素个数size为默认值0 // public ArrayList(int initialCapacity) ArrayList<Integer> arrayIntegerList = new ArrayList<>(10); // Collection构造 √ // public ArrayList(Collection<? extends E> c) HashSet<Long> hashSet = new HashSet<>(2); hashSet.add(1L); hashSet.add(Long.valueOf("99999999999999")); ArrayList<Long> arrayLongList = new ArrayList<>(hashSet); System.out.println(arrayLongList); // [1, 99999999999999] // 2. 基本增删改查操作 √ // 增 arrayStringList.add("学习"); arrayStringList.add(0,"我要"); System.out.println("originStringList: " + arrayStringList.toString()); //originStringList: [我要, 学习] // 改 arrayStringList.set(0, "我不"); // 查 System.out.println("lastStringList: " + arrayStringList.get(0) + arrayStringList.get(1)); //lastStringList: 我不学习 // 删 arrayStringList.remove("我不"); //arrayStringList.remove(0); System.out.println(arrayStringList); //[学习] // 3. 遍历 // 普通遍历 for (int i = 0; i < arrayLongList.size(); i++) { System.out.print(arrayLongList.get(i) + " "); //1 99999999999999 } System.out.println(); // 增强遍历 √ for (Long num : arrayLongList) { System.out.print(num + " "); //1 99999999999999 } System.out.println(); // 迭代器遍历 Iterator<Long> longIterator = arrayLongList.iterator(); while(longIterator.hasNext()) { System.out.print(longIterator.next() + " "); //1 99999999999999 } System.out.println(); // 4. 排序 ArrayList<Pair<Integer, String>> sortList = new ArrayList<>(); sortList.add(new Pair<>(1, "zhangsan")); sortList.add(new Pair<>(2, "lisi")); sortList.add(new Pair<>(3, "wangwu")); // Comparator Collections.sort(sortList, new Comparator<Pair<Integer, String>>() { @Override public int compare(Pair<Integer, String> o1, Pair<Integer, String> o2) { return o1.getKey() - o2.getKey(); } }); System.out.println(sortList); //[1=zhangsan, 2=lisi, 3=wangwu] // Lambda (Java8)√ Collections.sort(sortList, (o1, o2) -> o1.getValue().compareTo(o2.getValue())); System.out.println(sortList); //[2=lisi, 3=wangwu, 1=zhangsan] // stream(Java8)√ sortList = (ArrayList<Pair<Integer, String>>) sortList.stream().sorted((o1, o2) -> o2.getValue().length() - o1.getValue().length()).collect(Collectors.toList()); System.out.println(sortList); //[1=zhangsan, 3=wangwu, 2=lisi] // 5. 去重 for(int i = 0; i < 5; i++) { arrayIntegerList.add(i % 2); } // 借助辅助集合(略) // 迭代器 => 改变顺序 ListIterator<Integer> integerIterator = arrayIntegerList.listIterator(); while(integerIterator.hasNext()) { Integer next = integerIterator.next(); integerIterator.remove(); if (!arrayIntegerList.contains(next)) { integerIterator.add(next); } } System.out.println(arrayIntegerList); //[1, 0] // stream => 顺序不变 √ for(int i = 0; i < 5; i++) { arrayIntegerList.add(i % 2); } arrayIntegerList = arrayIntegerList.stream() .collect(Collectors.collectingAndThen(Collectors.toCollection(HashSet::new), ArrayList::new)); System.out.println(arrayIntegerList); //[0, 1] // 6. 获取ArrayList的容量(扩展)=> 利用反射机制 // 思考:为什么此时容量发生变化?=> ArrayList扩容原理 System.out.println("arrayStringList-Capacity: " + getCapacity(arrayStringList)); //arrayStringList-Capacity: 10 System.out.println("arrayIntegerList-Capacity: " + getCapacity(arrayIntegerList)); //arrayIntegerList-Capacity: 2 // 7. 更多arrayList内容 => jdk文档 // 元素交换 Collections.reverse(arrayIntegerList); System.out.println(arrayIntegerList); // 反转 Collections.swap(arrayIntegerList, 0, 1); //[1, 0] System.out.println(arrayIntegerList); //[0, 1] } /** * 利用反射机制获取容量 * @param list * @return */ public static Integer getCapacity(ArrayList list) { Integer length = null; Class clazz = list.getClass(); Field field; try { field = clazz.getDeclaredField("elementData"); field.setAccessible(true); Object[] object = (Object[]) field.get(list); length = object.length; return length; } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } return length; } -
- 当ArrayList的容量为0时,添加元素
⇓
\Downarrow
⇓
- 无参构造,添加第一个元素后,容量变为10,此后若需要扩容则正常扩容。
- 传容量构造,添加第一个元素后,容量为1,此后若需要扩容则正常扩容。
- 传列表构造且列表为空,添加第一个元素后,容量为1,此后若需要扩容则正常扩容。
- 当 ArrayList 的容量大于0,并且 ArrayList 是满时,增加元素 ⇒ \Rightarrow ⇒ 正常扩容(每次扩容到原来的1.5倍)
- 当ArrayList的容量为0时,添加元素
⇓
\Downarrow
⇓
LinkedList
通过
first和last引用分别指向链表的第一个和最后一个元素,每个节点都用内部类Node表示。注:当LinkedList为空时,first 和 last都指向 null
-
基本操作
包括构建、增删改查、遍历、反转、排序、合并、获取结点(中间/任意)、判断环、判断回文和其他内置方法
public static void LinkedListDemo() { //1. 构造方法 // 空参构造 => 空链表,first和null指向空 √ LinkedList<String> linkedStringList = new LinkedList<>(); // Collection构造 √ HashSet<Long> hashSet = new HashSet<>(2); hashSet.add(1L); hashSet.add(Long.valueOf("99999999999999")); LinkedList<Long> linkedLongList = new LinkedList<>(hashSet); //2. 基本增删改查 // 增 => 头部,尾部,给定索引 linkedStringList.add("学"); linkedStringList.addFirst("我"); linkedStringList.addLast("习"); linkedStringList.add(1, "爱"); System.out.println(linkedStringList); //[我, 爱, 学, 习] // 改 => 给定索引 linkedStringList.set(1, "不"); System.out.println(linkedStringList); //[我, 不, 学, 习] // 查 => 头部,尾部,给定索引(类似折半查找) System.out.println(linkedStringList.getFirst() + linkedStringList.get(2) +linkedStringList.getLast()); //我学习 // 删 => 头部,尾部,给定索引 linkedStringList.removeFirst(); linkedLongList.removeLast(); //注意:删除为空(思考:为何此处无抛异常?) linkedStringList.remove(0); //我学习 //3. 遍历 // 普通for => 增强for √ for (String s : linkedStringList) { System.out.print(s + " "); //学 习 } System.out.println(); // 迭代器 => 列表迭代器 √ ListIterator<String> stringListIterator = linkedStringList.listIterator(); while(stringListIterator.hasNext()) { System.out.print(stringListIterator.next() + " "); //学 习 } System.out.println(); // forEach方法 => stream流方法 linkedStringList.forEach(item -> System.out.print(item + " ")); //学 习 System.out.println(); linkedStringList.stream().forEach(item -> System.out.print(item + " ")); //学 习 System.out.println(); //TODO 思考链表 => 反转、排序、合并、获取结点(中间/任意)、判断环、判断回文 }
1.2 Set
没有顺序的集合,元素不以通过整形下标访问,不包含重复元素(
hashCode与equals方法保证元素唯一性)
| 类型 | 底层数据结构 | 注意 | 线程安全 | 效率 | 类别 |
|---|---|---|---|---|---|
| HashSet | JDK8前,哈希表(数组
+
+
+ 列表) JDK8后,哈希表(数组 + + + 链表 + + + 红黑树) HashSet底层原理分析 | 无序 | × | 快 | 实现类 |
| TreeSet | 红黑树 | 可指定排序规则 (默认自然排序) | × | 实现类 | |
| LinkedHashSet | HashSet + + + 双向链表(记录添加顺序) | 有序(添加顺序) | × | 实现类 | |
| EnumSet | HashSet + + + 枚举型元素 | 必须显式或者隐式指定对应的枚举类 | × | 抽象类 |
HashSet
-
基本操作
public static void hashSetDemo() { //1. 构造 // 空参 => 默认初始容量为16和加载因子0.75 HashSet<String> stringHashSet = new HashSet<>(); // 指定初始容量 => public HashSet(int initialCapacity) // 指定的初始容量和指定的加载因子 => public HashSet(int initialCapacity, float loadFactor) // collection构造 Long[] longs = new Long[]{1L, 2L, 2L, 3L, 4L}; ArrayList<Long> longArrayList = (ArrayList<Long>) Stream.of(longs).collect(Collectors.toList()); HashSet<Long> longHashSet = new HashSet<>(longArrayList); System.out.println(longHashSet); //[1, 2, 3, 4] longArrayList.clear(); //2. 增删改查 //增 longHashSet.addAll(longArrayList); if (!longHashSet.isEmpty()) { longHashSet.add(99999999999999L); longHashSet.add(678910L); longHashSet.add(12345L); } System.out.println(longHashSet); //[1, 2, 3, 4, 678910, 99999999999999, 12345] //改 × //查 × => 包含 √ System.out.println(longHashSet.contains(9)); //false System.out.println(longHashSet.containsAll(longArrayList)); //true //删 longHashSet.remove(1L); //这里注意,如果是1则删除失败 System.out.println(longHashSet.removeAll(longArrayList)); //false longHashSet.removeIf(item -> item.equals(12345L) || item.equals(678910)); System.out.println(longHashSet); //[2, 3, 4, 678910, 99999999999999] //3. 遍历 // 增强for for (Long num : longHashSet) { System.out.print(num + " "); //2 3 4 678910 99999999999999 } System.out.println(); // 迭代器 Iterator<Long> longIterator = longHashSet.iterator(); while(longIterator.hasNext()) { System.out.print(longIterator.next() + " "); //2 3 4 678910 99999999999999 } System.out.println(); // TODO 验证无序性、clone方法、应用场景? }
1.3 队列与栈的选用
实现类选用
- 普通队列:ArrayDeque/LinkedList
- 普通堆栈:ArrayDeque
- 阻塞与双向队列:BlockingQueue接口
ArrayDeque

JDK 1.8 官方注释:
ArrayDeque 当作栈时,此类可能比 Stack 快
ArrayDeque 当作队列时,则比 LinkedList 要快
特性
不允许添加
null⇒ \Rightarrow ⇒ 作为循环结束条件双向队列,自动双向扩容(当数组填充满时扩容,长度必定是2的幂,数组最大长度为 2 30 2^{30} 230)

使用队列头
head,队列尾下一个tail的索引指针 ⇒ \Rightarrow ⇒ 整体相当于一个环形数组
线程不安全
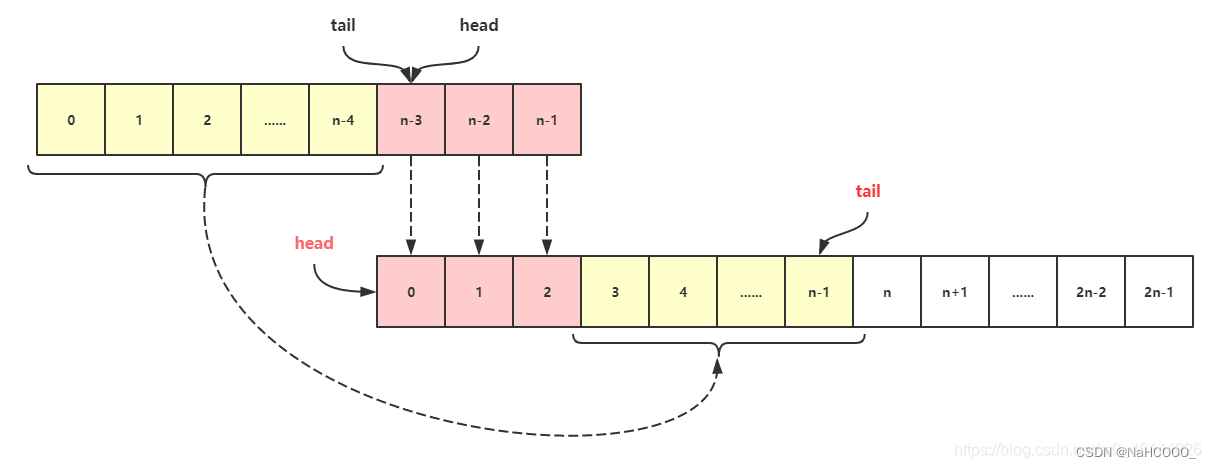
-
作为队列使用
public static void arrayDequeAsDeque() { // 1. 创建栈 Deque queue = new ArrayDeque<>(); // 2. 入队 queue.offer("first"); queue.offer("second"); // 3. 查询队元素 System.out.println(queue.getFirst()); //first System.out.println(queue.getLast()); //second // 4. 出队 queue.poll(); System.out.println(queue); //[second] } -
作为栈使用
public static void arrayDequeAsStack() { // 1. 创建栈 Deque stack = new ArrayDeque<>(); // 2. 入栈 stack.push("first"); stack.push(1); stack.push(1.0); // 3. 查看栈元素 System.out.println(stack.getFirst()); //1.0 System.out.println(stack.getLast()); //first // 4. 出栈 stack.pop(); System.out.println(stack); //[1, first] }
2、Map
双列集合,一个元素包含
key-value(key不可重复,value可以重复,类型可以不同)
| 类型 | 底层 | 注意点 | 线程安全 | 效率 | 类别 |
|---|---|---|---|---|---|
| HashMap | JDK8前,数组
+
+
+ 单向链表 JDK8后,数组 + + + 单向链表 + + + 红黑树 | 无序 | × | 快 | 实现类 |
| Hashtable | 拟HashMap | 不允许使用null作为key和value | √ | 慢 | 实现类 |
| Properties | Hashtable + + + 内部扩展 | 只允许添加String的key-value常用处理属性配置文件 | √ | 慢 | 实现类 |
| TreeMap | 红黑树 | 可指定key排序比较器(默认升序排序) | × | 实现类 | |
| LinkedHashMap | HashMap + + + 双向链表(记录添加顺序) | 有序(添加顺序) | × | 实现类 | |
| EnumMap | HashMap
+
+
+ 枚举型key | key必须是单个枚举类的枚举值 必须显式或者隐式指定对应的枚举类 不允许null作为key | × | 实现类 |
HashMap
底层基于散列算法实现,它是一个
key-value结构的容器。
-
基本操作
public static void HashMapDemo() { // 1. 构造方法 // 无参 => 默认负载因子 0.75f, 默认容量 16 HashMap<Long, String> hashMap = new HashMap<>(); // 指定初始容量 public HashMap(int initialCapacity) // 指定初始容量和负载因子 public HashMap(int initialCapacity, float loadFactor) // Map类型的参数的构造方法 => public HashMap(Map<? extends K, ? extends V> m) HashMap<Long, String> tempHashMap = new HashMap<>(hashMap); // 2. 增删改查 // 增、改(直接覆盖) tempHashMap.put(1L, "first"); tempHashMap.put(3L, "third"); hashMap.putAll(tempHashMap); if (!hashMap.isEmpty()) { hashMap.put(2L, "second"); } System.out.println(hashMap); // 查 System.out.println(hashMap.get(1) + " " + hashMap.get(1L)); //null first // 删 if (hashMap.containsKey(1L) && hashMap.containsValue("first")) { if (!hashMap.remove(1, "first")) { System.out.println("key = 1L and value = " + hashMap.remove(1L)); //key = 1L and value = first } } // 3. 遍历 以下输出均为 { key = 2 and value = second, key = 3 and value = third, } // 迭代器 entrySet(键值对视图)=> keySet键视图, values值视图 Iterator<Map.Entry<Long, String>> iterator = hashMap.entrySet().iterator(); System.out.print("{ "); while (iterator.hasNext()) { Map.Entry<Long, String> next = iterator.next(); System.out.print("key = " + next.getKey() + " and value = " + next.getValue() + ", "); } System.out.println(" }"); // 增强for System.out.print("{ "); for (Map.Entry<Long, String> entry : hashMap.entrySet()) { System.out.print("key = " + entry.getKey() + " and value = " + entry.getValue() + ", "); } System.out.println(" }"); // lambda表达式 System.out.print("{ "); hashMap.forEach((key, value) -> { System.out.print("key = " + key + " and value = " + value + ", "); }); System.out.println(" }"); // stream单线程流 System.out.print("{ "); hashMap.entrySet().stream().forEach((entry -> { System.out.print("key = " + entry.getKey() + " and value = " + entry.getValue() + ", "); })); System.out.println(" }"); // parallelStream多线程流 => 输出结果不可预知 System.out.print("{ "); hashMap.entrySet().parallelStream().forEach((entry -> { System.out.print("key = " + entry.getKey() + " and value = " + entry.getValue() + ", "); })); System.out.println(" }"); // TODO 其他内置方法 containsValue containsKey clear ... } -
底层逻辑
jdk8 后底层由
数组&链表&红黑树实现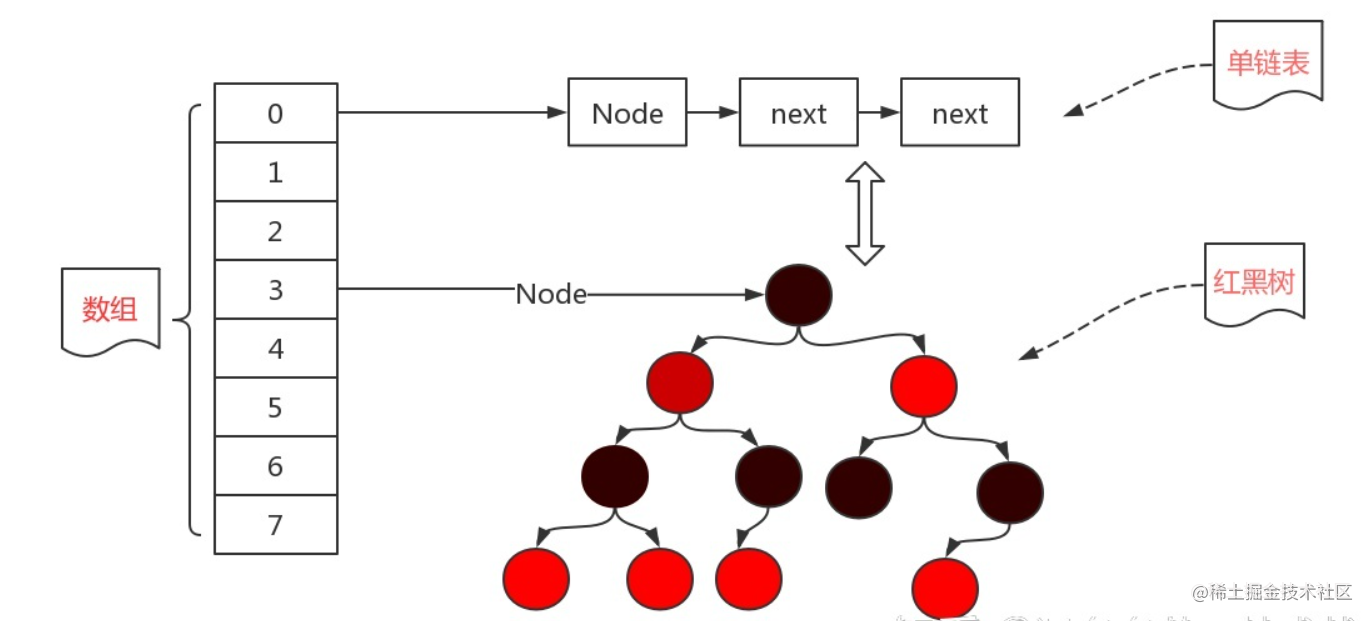
-
扩容机制
HashMap底层是一个数组,发现数组长度不够了,就需要进行扩冲容量的操作。
- 相关参数:初始容量
initialCapacity,负载因子loadFactor。通过设定参数,可以进一步影响阈值大小。 - 扩容的阈值:
threshold= = =capacity∗ * ∗loadFactor(容量 ∗ * ∗ ) - 当前 HashMap 所能容纳键值对数量的最大值,超过扩容的阈值,则进行扩容
- 相关参数:初始容量
-
快速失败机制
Java 非安全集合中的一种普遍机制,这种机制可以让集合在遍历时,如果有线程对集合进行了修改、删除、增加操作,会触发并发修改异常。其实现机制是在遍历前保存一份
modCount,在每次获取下一个要遍历的元素时会对比当前的modCount和保存的modCount是否相等。- 避免由于并发修改导致一些未知的问题,并通过提前失败提高性能。
Properties
主要用于读取Java的配置文件(
.properties文件,是以键值对的形式进行参数配置的)
-
基本操作
读、写配置文件
public static void PropertiesDemo() { // 1. 构造 Properties properties = new Properties(); try { // 2. 读取文件 => 注意默认是不按顺序读取的 properties.load(new FileInputStream("src/demo.properties")); Enumeration fileName = properties.propertyNames(); while (fileName.hasMoreElements()) { String key = (String) fileName.nextElement(); String value = properties.getProperty(key); System.out.println(key + " = " + value); } // 3. 写入文件 properties = new Properties(); FileOutputStream outputStream = new FileOutputStream("src/demo.properties",true); //true表示追加 properties.setProperty("fifth", "5"); properties.setProperty("sixth","6"); properties.store(outputStream,"test"); outputStream.close(); // TODO 如何按顺序写入和读取? } catch (IOException e) { throw new RuntimeException(e); } }目录结构
执行前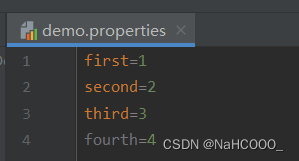
执行后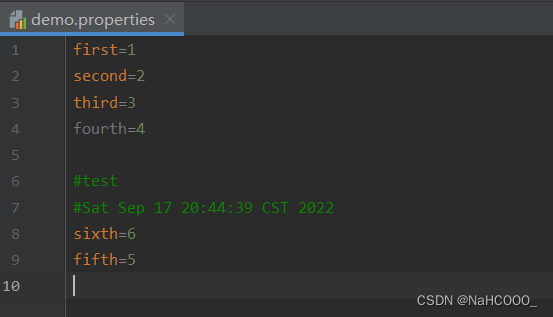
写在最后
感谢各位能看到这里,如果文章中有什么不对或者缺少一些相关内容,还望大佬们海涵,可以在评论区提出,我会尽快做出修改,谢谢。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









