







 本文探讨了Hadoop与Spark的关系,解释了Spark作为Hadoop的改进产物,强调其速度快、易用性高、模块化强的特点。Spark通过内存计算和RDD实现高效处理,提供了一个全面的大数据处理框架。此外,文章还概述了Spark的架构和工作流程,包括DAG和RDD的概念,以及Job、Stage和Task的关系。
本文探讨了Hadoop与Spark的关系,解释了Spark作为Hadoop的改进产物,强调其速度快、易用性高、模块化强的特点。Spark通过内存计算和RDD实现高效处理,提供了一个全面的大数据处理框架。此外,文章还概述了Spark的架构和工作流程,包括DAG和RDD的概念,以及Job、Stage和Task的关系。
RDD的相关操作(creation, transformation, action)
Hadoop
在大数据的背景下,我们需要分布式数据存储和处理的工具,来解决一些现实问题(如:基础设施崩溃(hardware broken/network failure);data combination(处理来自多个源头的数据))(这些问题都是集中式系统面临的挑战)。因此Hadoop系统得到广泛应用。
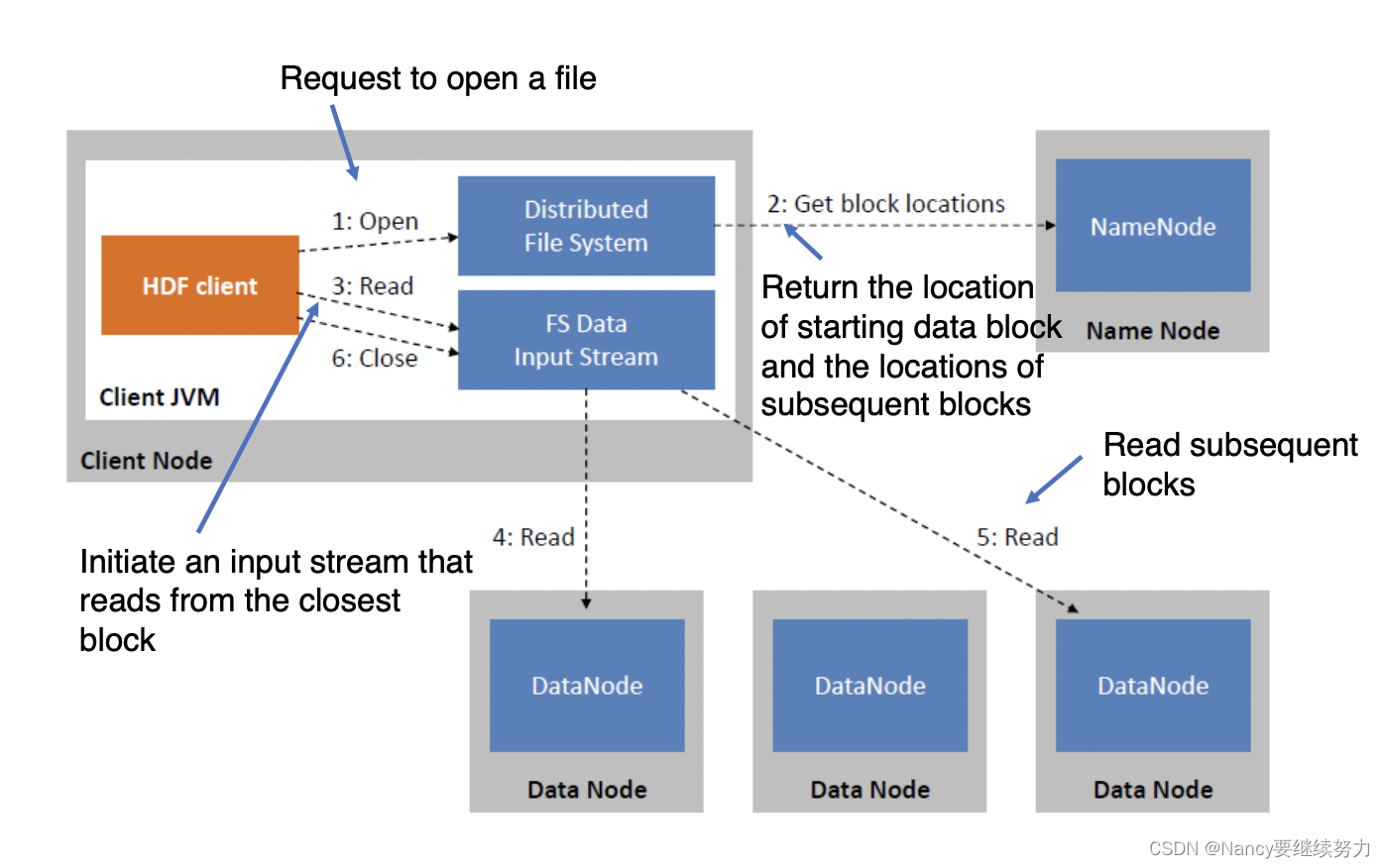
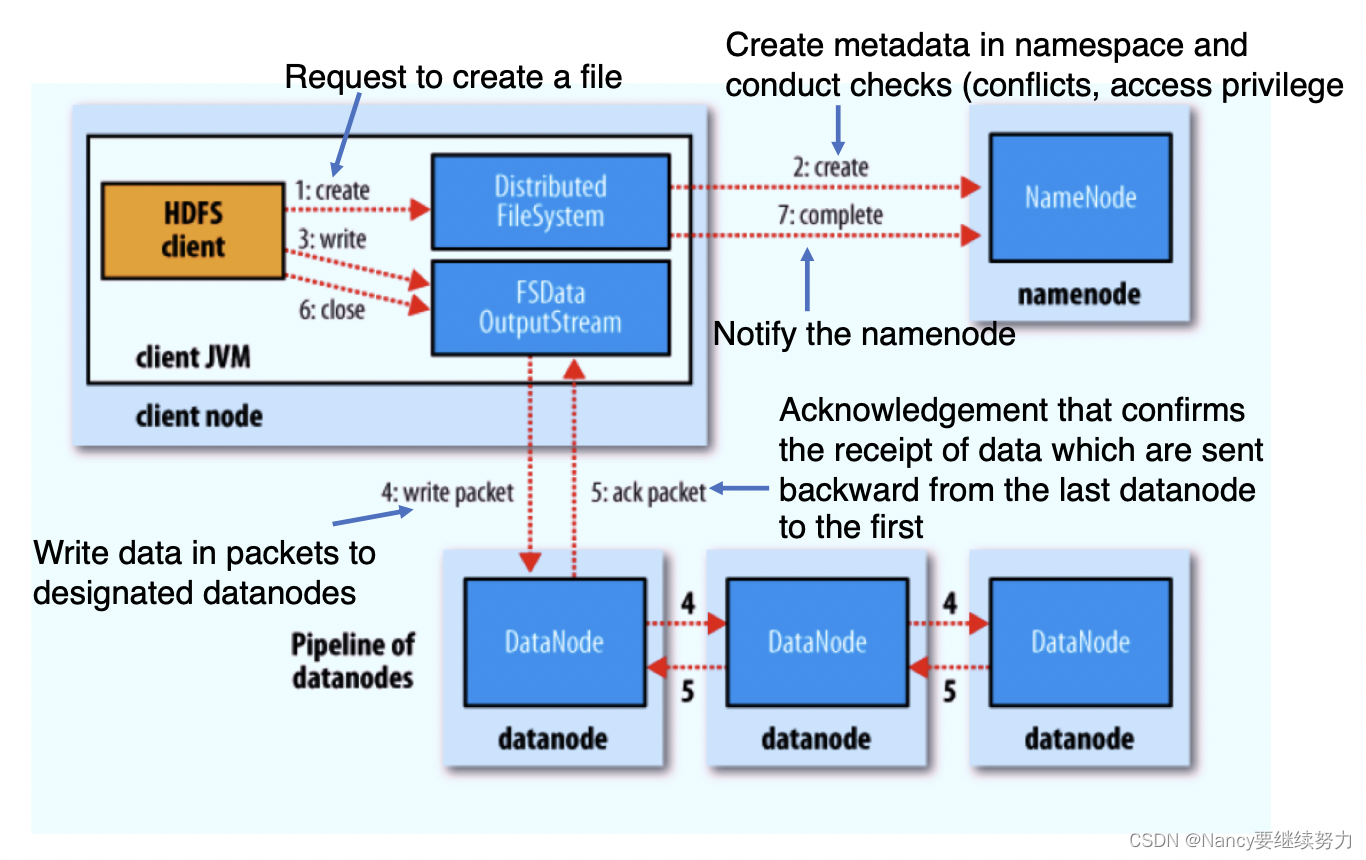
Hadoop系统分为两部分,HDFS(hadoop distributed file system) 和 MapReduce(processing framework)。 HDFS是分布式文件系统,可以进行创建、删除、移动、重命名文件、读/写文件等操作。有一个NameNode和多个DataNode,NameNode负责管理文件系统的名字空间和控制外部客户机的访问;DataNode 提供存储块,存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)中。NameNode 决定是否将文件映射到 DataNode 上的复制块上。HDFS 的主要目的是支持以流的形式访问写入的大型文件。下图为HDFS的读,写操作过程。
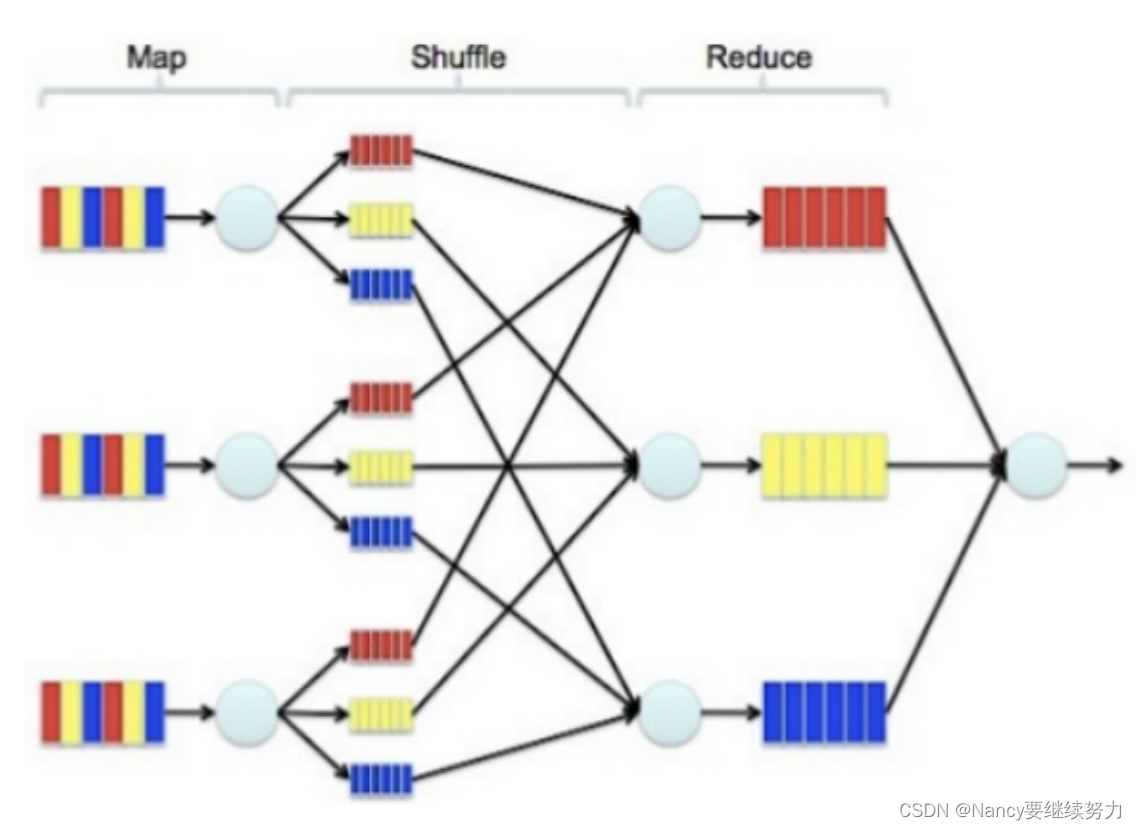
MapReduce模型由Map,shuffle,reduce这三部分组成,原理如下图:
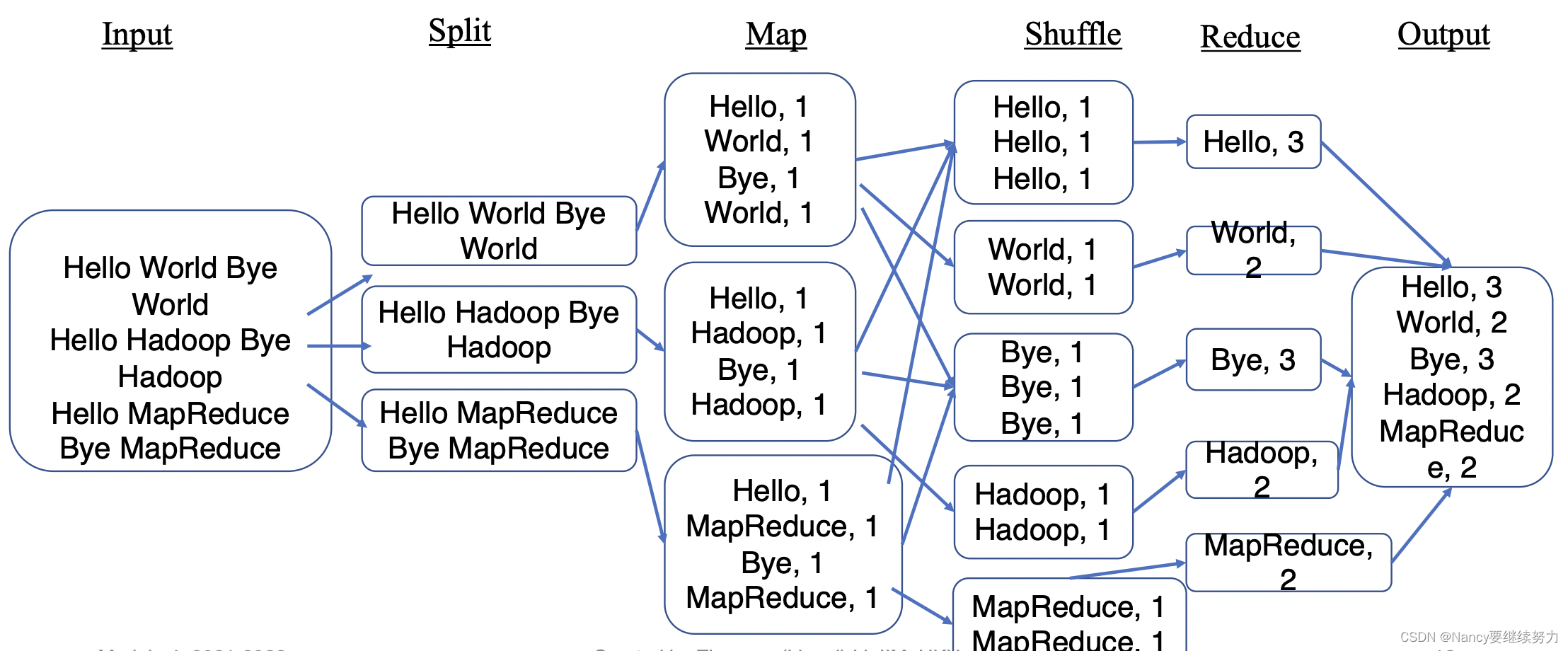
Split和Map环节的各块数据,在不同的计算机中处理;经过MapReduce的shuffle环节,再将不同单词的词频总计任务分配给不同的reducer(计算机);最后由reduce到output环节再merge到一台计算机上。最初的MapReduce模型可能效率跟不上大数据需求,但是这种编程思想是值得学习的。参考知乎问题:mapreduce为什么被淘汰了? - 知乎
Spark
这个文章写的很好:Spark: 基本架构及原理。接下来的内容很多选取自此文章。
1. Spark与Hadoop的关系
Spark是在Hadoop系统上的改进产物。它是专为大规模数据处理而设计的快速通用的计算引擎,提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实时的流数据)的大数据处理的需求。Spark本身并没有提供分布式文件系统,因此其分析大多依赖于Hadoop的分布式文件系统HDFS;Hadoop的MapReduce与spark都可以进行数据计算,而相比于Mapreduce,spark的速度更快并且提供的功能更加丰富。关系如下:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2052
2052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









