








DeepSeek R1本地化部署 Ollama + Chatbox 打造最强AI工具
本文介绍如何通过本地化部署Ollama和Chatbox,利用DeepSeek R1模型打造强大的AI工具,涵盖Ollama和Chatbox的使用方法及相关操作步骤。
一、Ollama
(一)下载Ollama
Ollama是用于管理和部署机器学习模型的工具,支持macOS、Linux、Windows系统。可在官网https://ollama.com/下载,
下载完成安装后,运行软件,在任务栏右上角会出现小羊驼🦙图标。
(二)选择模型
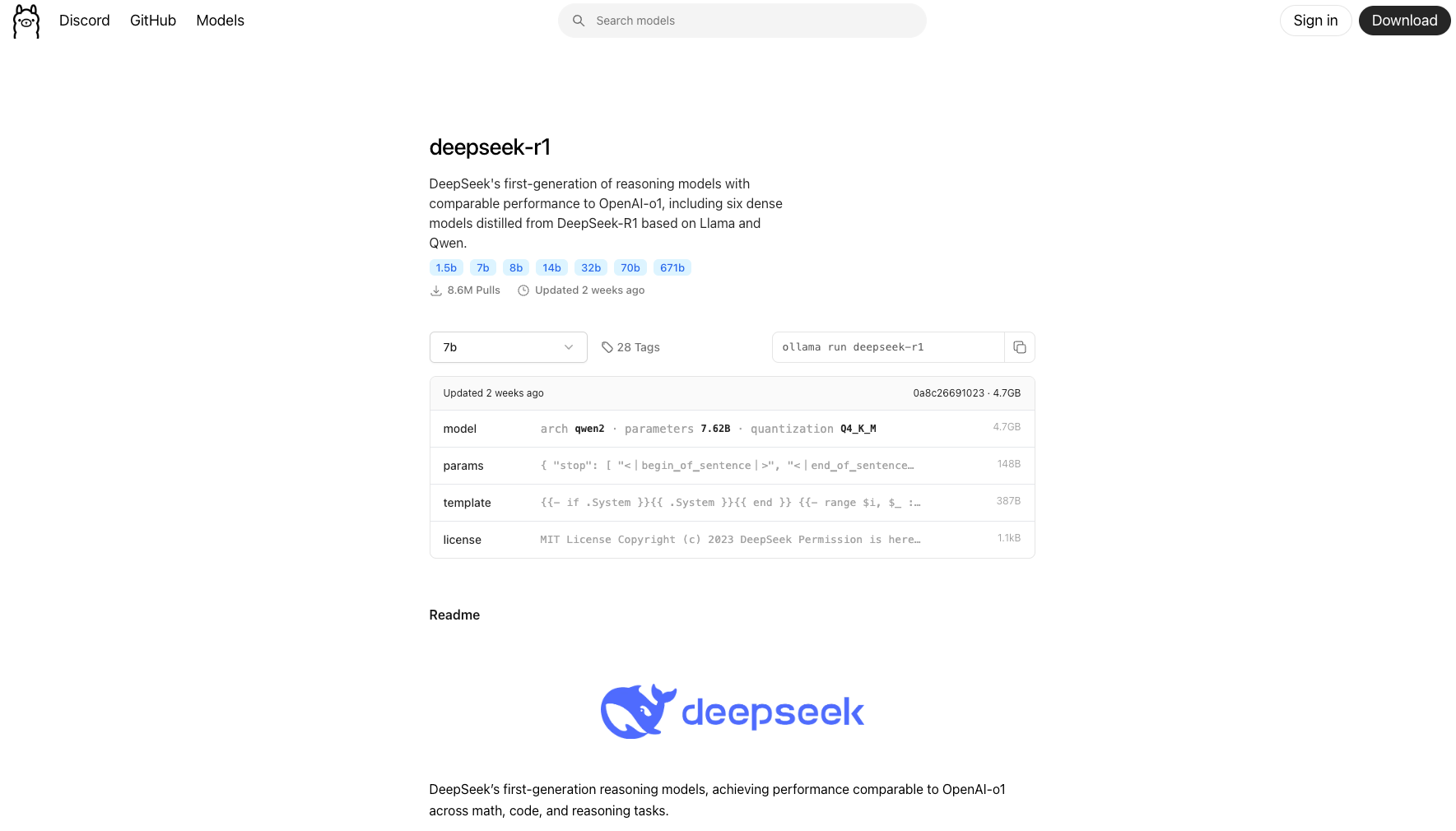
在Ollama界面点击“Search models”搜索框,可找到deepseek-r1模型。该模型有多个版本,如1.5b、7b、8b等,参数量越大模型越强大,但对计算资源要求也越高。不同模型大小对应的运行需求如下:
| 模型大小 | 显存需求(FP16推理) | 显存需求(INT8推理) | 推荐显卡 | macOS需要的RAM |
|---|---|---|---|---|
| 1.5B | ~3GB | ~2GB | RTX 2060 / Mac GPU可运行 | 8GB |
| 7B | ~14GB | ~10GB | RTX 3060 12GB/ 4070 Ti | 16GB |
| 8B | ~16GB | ~12GB | RTX 4070 / Mac GPU高效运行 | 16GB |
| 14B | ~28GB | ~20GB | RTX 4090/ A100-40G | 32GB |
| 32B | ~64GB | ~48GB | A100-80G / 2x RTX 4090 | 64GB |
(三)运行模型
确定要运行的模型后,复制指令“ollama run deepseek-r1:模型版本(如7b)”到终端运行。当进度条完成,电脑就具备了相应的推理能力。

(四)使用 && 测试
使用“ollama list”指令可查看已部署的模型,使用“ollama run 对应的模型”即可进行交互。输入“/bye”可退出。Ollama还有其他指令,具体如下:
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
二、Chatbox
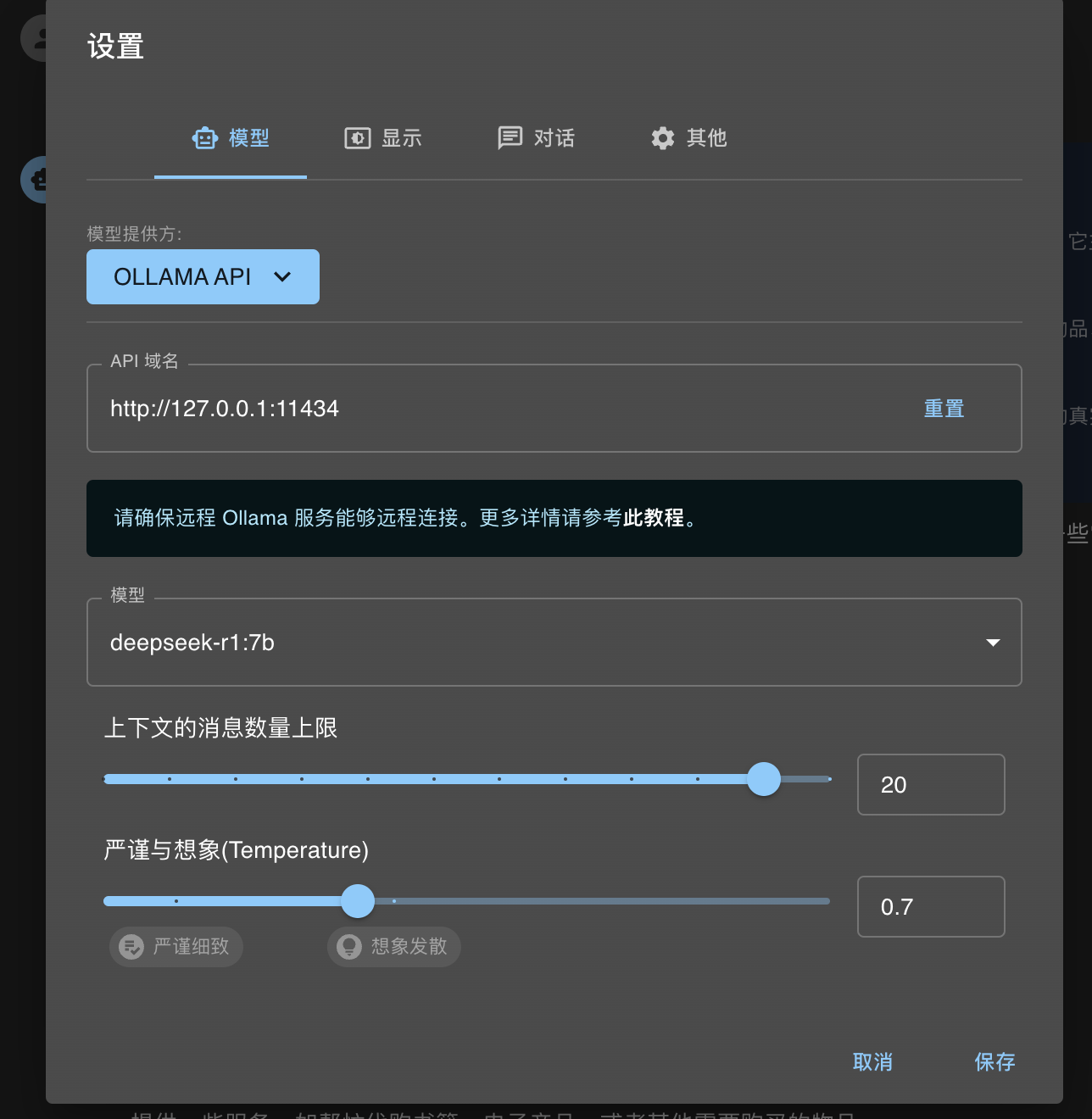
在浏览器搜索Chatbox,可下载客户端或使用网页版。设置语言为中文后,点击设置选择模型为OLLAMA API,API域名设置为“http://127.0.0.1:11434” ,选择R1模型并保存(不同操作系统设置方式不同,需按教程操作确保连接到本地服务)。之后就可以在浏览器或客户端上流畅使用R1模型。
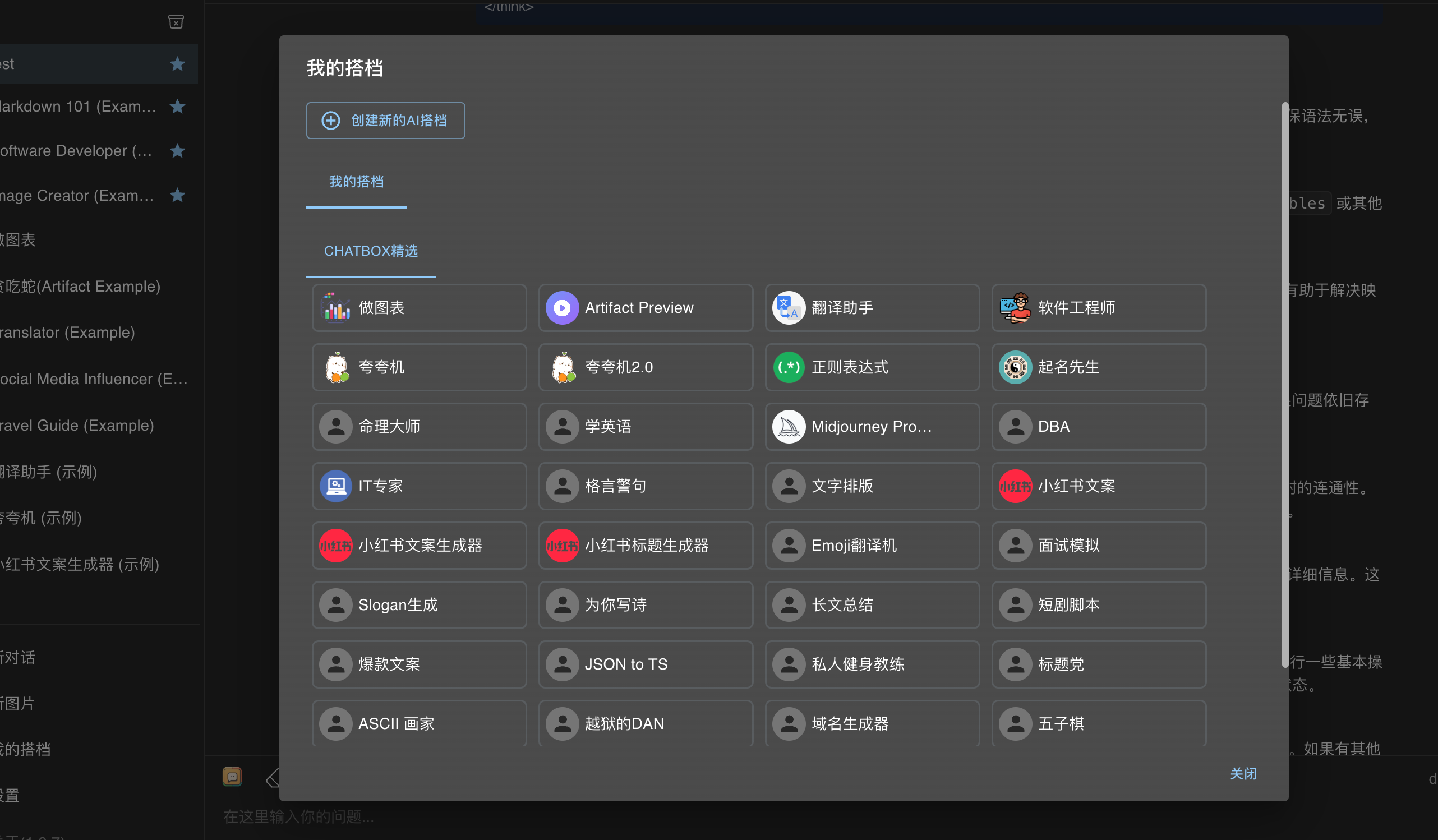
(一)创建你的专属GPTs
在Chatbox中点击“我的搭档”,可创建新的AI搭档,为其设定人格,也可选择现有的搭档,如软件工程师、夸夸机等角色。
三、共勉
以上就是利用DeepSeek R1本地化部署Ollama + Chatbox打造AI工具的全部内容,若文章对你有帮助,欢迎点赞收藏关注。


















 1491
1491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











