







骨龄是骨骼年龄的简称,需要借助于骨骼在X光摄像中的特定图像来确定。通常要拍摄左手手腕部位的X 光片,医生通过X光片观察来确定骨龄。
在2006年,《中华-05》骨龄标准被编入《中华人民共和国行业标准》,成为中国目前唯一的行业骨龄标准。而在《中华-05》中作者一般推荐使用RUS-CHN计分法。

图中黄色高亮的地方,每个高亮都是需要医生看的关节,医生做骨龄的时候,需要对每个关节,根据骨 骺的发育情况。判断对应的等级。再查表,计算13个关节的等级分数之和,到【RUS-CHN骨成熟百分位 数标准曲线】中,找到分数对应的年龄。
骨龄评估是衡量生长发育的重要方法,但传统方法繁琐耗时,依赖医生经验。
我们项目利用深度学习算法,训练模型自动识别分析X光片中的骨骼图像,实现骨龄评估的自动化与智能化。自动化评估提高工作效率,减轻医生负担,增加关注其他病情的时间。同时,提高评估准确性和客观性,避免人为误差和偏见。
此外,自动化评估有助于优化医疗资源配置,高效处理大量骨龄评估任务,释放资源关注更紧急病情,提高医疗服务质量和及时援助。
骨龄评估自动化与智能化提高效率和准确性,优化医疗资源配置,对未来医疗科技发展有重要作用,为人类健康事业贡献力量。
目录
在文章中,我会上传本次项目,项目中无数据集,附带txt格式标注文件,数据集和大多互联网平台数据相同,可以通过文件比对,二转请表明出处,出现任何额外收费等行为与本人无关
1.数据处理
通过对下载的数据集进行观察,可以得到,数据集是存在明显瑕疵的:数据模糊不清晰,数据量小(注意数据量虽然少,但是不增样。如果增样的化,就需要重新标注数据)。
OpenCV 直方图均衡化
什么是直方图均衡化? 是一种提高图像对比度的方法,拉伸图像灰度值范围。 简单来说, 一般情况,可以看到像素主要集中在中间的一些强度值上。 直方图均衡化要做的就是拉伸这个范围,就是像素主要几种区间。 像素分布率较低像素值,对其应用均衡化后(将像素分布较高的区间拉伸,得到 了新的直方图。
因为直方图均衡化处理之后,原来比较少像素的灰度会被分配到别的灰度去,像素相对集中, 处理后 灰度范围变大,对比度变大,清晰度变大,所以能有效增强图像。
而在直方图均衡化的对比度明显提高时,也同时提高了噪声的对比度。
通过自适应直方图均衡化,我们将输入图像划分为M × N网格。然后我们对网格中的每个单元进行均衡处理,从而获得更高质量的输出图像。
缺点是,自适应直方图均衡化的计算复杂度更高
import os
import cv2
from tqdm import tqdm
path = r"data/voc/VOCdevkit/VOC2007/JPEGImages"
if __name__ == '__main__':
for name in tqdm(os.listdir(path)):
img_path = os.path.join(path,name)
img=cv2.imread(img_path,0)
clahe=cv2.createCLAHE(tileGridSize=(3,3))
dst =clahe.apply(img)通过循环遍历,对收集到的手掌X光片图片文件进行直方图均衡化处理,以提高图像对比度,拉伸图像灰度值范围。处理后,图像灰度范围变大,对比度变大,清晰度变大,有效增强图像质量。 直方图均衡化的作用包括:
* 增强图像对比度:扩展灰度级范围,使图像细节更清晰可见。
* 增强图像细节:使纹理、边缘等细微特征更明显。
* 提升图像质量:改善视觉效果,使图像更鲜明、生动。
* 应用于图像增强和预处理:改善视觉效果,提升后续算法性能。
而以下代码旨在从 Pascal VOC 格式的 XML 注释文件中提取所有独特的目标类别名称。通过遍历指定目录下的 XML 文件,并解析每个文件中的目标标签,代码将收集并输出所有出现过的类别。此过程有助于构建数据集中目标类别的全面列表,为后续的模型训练和数据分析提供支持。
import os
from tqdm import tqdm
import xml.etree.ElementTree as ET
path="data/voc/VOCdevkit/VOC2007/Annotations"
if __name__ == '__main__':
list_cls = []
for name in tqdm(os.listdir(path)):
xml_path = os.path.join(path,name)
tree=ET.parse(xml_path)
root=tree.getroot()
list_cls=[]
for obj in root.iter('object'):
cls=obj.findtext('name')
if cls not in list_cls:
list_cls.append(cls)
print(list_cls)Data_getclasses:遍历指定路径下的XML标签文件,提取出所有不重复的目标类别,并将其保存在一个列表中。这对于后期数据集的统计分析、模型训练和评估等任务都很有用。
'''
拆分数据集: 训练集:验证集:测试集 = 7:2:1
'''
import os
import random
train_val_percent = 0.9
train_percent = 0.9 #这里的 train_percent 是指占 train_val_percent 中的
# xml 标签文件
base_path='data/voc/VOCdevkit/VOC2007'
xml_file_path =base_path+ r'\Annotations'
txt_save_path =base_path+r'\ImageSets'
# 判断txt_save_path文件夹路径如果不存在,就创建出来
if not os.path.exists(txt_save_path):
os.makedirs(txt_save_path)
# 统计标签文件xml的总数
total_xml = os.listdir(xml_file_path)
num = len(total_xml)
list_index = range(num) # 获取随机0 到 num-1的数字,作为索引值
# 计算训练集和验证集的数据量
train_val_num = int(num * train_val_percent)
# 计算训练集的数据量
train_num = int(train_val_num * train_percent)
# 获取列表 list_index 中 指定长度的随机数
train_val_indexs = random.sample(list_index, train_val_num)
train_indexs = random.sample(train_val_indexs, train_num)
# 打开四个文件 trainval.txt、test.txt、train.txt、val.txt 用来保存分出来的数据名称
file_train_val = open(os.path.join(txt_save_path, 'trainval.txt'), 'w')
file_train = open(os.path.join(txt_save_path, 'train.txt'), 'w')
file_test = open(os.path.join(txt_save_path, 'test.txt'), 'w')
file_val = open(os.path.join(txt_save_path, 'val.txt'), 'w')
for i in list_index:
# 获取到xml的文件名称,不要后缀
name = total_xml[i][:-4] + '\n'
# 判断当前的索引值i是在哪部分
if i in train_val_indexs:
# 在训练集或者验证集中
file_train_val.write(name)
if i in train_indexs:
# 在训练集中
file_train.write(name)
else:
# 在验证集中
file_val.write(name)
else:
# 在测试集中
file_test.write(name)
# 关闭资源
file_train_val.close()
file_train.close()
file_test.close()
file_val.close()data_split:把数据集拆分成为:训练集、验证集、测试集 ,且拆分比例为7:2:1。将数据集拆分为训练集、验证集和测试集可以用于模型的训练和评估。训练集用于训练模型,验证集用于调整模型的超参数和防止过拟合,测试集用于最终评估模型的性能。拆分数据集可以有效地帮助训练和评估机器学习模型,提高模型的泛化能力,并确保模型在真实场景中的可靠性和效果。
import os
import shutil
import xml.etree.ElementTree as ET
from tqdm import tqdm
sets = ['train', 'test', 'val']
classes = ['Radius', 'Ulna', 'MCPFirst', 'MCP', 'ProximalPhalanx', 'DistalPhalanx', 'MiddlePhalanx']
def voc2yolo(image_id):
in_file = open(annotations_path % image_id, encoding='utf-8')
out_file = open(labels_path + r'\%s.txt' % image_id, 'w', encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
img_w = int(size.findtext('width'))
img_h = int(size.findtext('height'))
for obj in root.iter('object'):
cls = obj.findtext('name')
difficult = obj.findtext('difficult')
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
bndbox = obj.find('bndbox')
xmin = int(bndbox.findtext('xmin'))
ymin = int(bndbox.findtext('ymin'))
xmax = int(bndbox.findtext('xmax'))
ymax = int(bndbox.findtext('ymax'))
if xmax > img_w:
xmax = img_w
if ymax > img_h:
ymax = img_h
w = xmax - xmin
h = ymax - ymin
cx = xmin + w / 2
cy = ymin + h / 2
w = round(w / img_w, 6)
h = round(h / img_h, 6)
cx = round(cx / img_w, 6)
cy = round(cy / img_h, 6)
out_file.write(f"{cls_id} {cx} {cy} {w} {h}\n")
out_file.close()
def read_files():
for img_set in sets:
img_path = imageSets_path % (img_set)
with open(img_path, 'r', encoding='utf-8') as file:
image_ids = [item.strip() for item in file.readlines()]
list_file = open(os.path.join(base_path, f'{img_set}.txt'), 'w')
for image_id in tqdm(image_ids):
voc2yolo(image_id)
list_file.write(os.path.join(images_path, f'{image_id}.png\n'))
list_file.close()
base_path = 'data/voc/VOCdevkit/VOC2007'
imageSets_path = os.path.join(base_path, r'ImageSets\%s.txt')
annotations_path = os.path.join(base_path, r'Annotations\%s.xml')
labels_path = os.path.join(base_path, 'labels')
images_path = os.path.join(base_path, 'images')
JPEGImages_path = os.path.join(base_path, 'JPEGImages')
if __name__ == '__main__':
print("数据处理 开始")
if not os.path.exists(labels_path):
os.makedirs(labels_path)
if os.path.exists(images_path):
shutil.rmtree(images_path)
shutil.copytree(JPEGImages_path, images_path)
read_files()
print("数据处理 完成")将VOC格式的数据集转换为YOLO格式,为后续目标检测模型训练做准备。将VOC格式的数据集转换为YOLO格式能够与YOLO算法和相关模型兼容,以便进行目标检测模型的训练和使用。
import cv2
img = cv2.imread('images/1841.png', flags=0)# 直方图均衡化
dst = cv2.equalizeHist(img)#cv2.imshow('dst', dst)
# cv2.waitKey(0)
cv2.imwrite("images/dst.png",dst)
# 自适应直方图均衡化
chahe =cv2.createCLAHE(tileGridSize=(3,3))
dst2 = chahe.apply(img)
cv2.imwrite('images/dst2.png',dst2)对输入的灰度图像进行直方图均衡化和自适应直方图均衡化处理,并将处理后的图像保存到指定的文件中,以增强图像对比度和细节。
import os.path
import torch
import common
import numpy as np
from PIL import Image
from torch.utils.data import Dataset,DataLoader
from torchvision.transforms import Compose, ToTensor, Resize, ToPILImage, InterpolationMode
data_transforms = Compose([Resize(size=(224, 224), interpolation=InterpolationMode.NEAREST),
ToTensor()])
class My_dataset(Dataset):
def __init__(self, file_path, mode):
super().__init__()
self.data_list = []
if mode == 'train':
file_path = os.path.join(file_path, 'train.txt')
elif mode == 'test':
file_path = os.path.join(file_path, 'test.txt')
else:
print('mode 不正确')
return
with open(file_path, 'r') as f:
lines = f.readlines()
for line in lines:
# D:\myfiles\datasets\arthrosis3\arthrosis\DIP\5\DIP_1306251.png 4
info = line.strip().split()
img_path, label = info[0], info[1]
self.data_list.append([img_path, int(label)])
def __getitem__(self, idx):
img_path, label = self.data_list[idx]
img = Image.open(img_path)
img = common.trans_square(img) # 正方形
img = img.convert('L') # 灰度图
img = data_transforms(img) # CHW
label = torch.tensor([label]).squeeze()
return img, label
def __len__(self):
return len(self.data_list)
if __name__ == '__main__':
data = My_dataset("data/arthrosis/DIP", 'train')
train_loader = DataLoader(data, batch_size=10, shuffle=True)
for x,y in train_loader:
print(x.shape)
print(y.shape)
break
自定义一个数据集类,用于加载图像数据集并准备成可以用于 PyTorch 模型训练的数据格式,为模型训练提供了数据准备和加载的基础功能。
import os
import random
import glob
import cv2
from PIL import Image
def opt_img(img_path):
'''
数据预处理:自适应直方图均衡化
'''
# 自适应直方图均衡化
img = cv2.imread(img_path, 0)
clahe = cv2.createCLAHE(tileGridSize=(3, 3), clipLimit=2.0)
dst = clahe.apply(img)
cv2.imwrite(img_path, dst)
# img_path = 'DIP_58532.png'
def img_rotate(img_path, flag=5):
'''
数据增样:左右15度内选择
'''
img = Image.open(img_path)
for i in range(flag):
rota = random.randint(-15, 15)
dst = img.rotate(rota)
# img_path = 'DIP_58532{i}.png'
file_path_name, _ = img_path.split(".")
dst.save(file_path_name + f"{i}.png")
def data_img(path):
'''
图像处理
'''
# path = r'D:\myfiles\datasets\arthrosis2\arthrosis\MCP'
for folder in os.listdir(path):
folder_path = os.path.join(path, folder)
if os.path.isfile(folder_path):
continue
print(folder_path)
list_img_name = glob.glob(folder_path + '/*')
count = len(list_img_name)
print("增样前:" + str(count))
# print(folder_path)
for img_name in os.listdir(folder_path):
img_path = os.path.join(folder_path, img_name)
# print(img_path)
# 自适应直方图均衡化(去雾操作)
opt_img(img_path)
# 数据增样
img_rotate(img_path)
# 获取图片数据的数量
list_img_name = glob.glob(folder_path+'/*')
count = len(list_img_name)
# 当前等级下数量不足1000就增样
if count < 1000:
# 数据增样
img_rotate(img_path, flag=1000-count)
list_img_name = glob.glob(folder_path + '/*')
count = len(list_img_name)
print("增样后:" + str(count))
def data_split(path):
'''
数据拆分:训练集train和验证集test
'''
# path = r'D:\myfiles\datasets\arthrosis2\arthrosis\MCP'
train_ratio = 0.9
train_list = []
test_list = []
for folder in os.listdir(path):
folder_path = os.path.join(path, folder)
if os.path.isfile(folder_path):
continue
img_names = os.listdir(folder_path)
train_num = len(img_names) * train_ratio
random.shuffle(img_names)
for index, img_name in enumerate(img_names):
if index < train_num:
train_list.append(os.path.join(folder_path, img_name) + " " + str(int(folder) - 1) + '\n')
else:
test_list.append(os.path.join(folder_path, img_name) + " " + str(int(folder) - 1) + '\n')
random.shuffle(train_list)
random.shuffle(test_list)
with open(os.path.join(path, "train.txt"), 'w') as f:
f.writelines(train_list)
with open(os.path.join(path, "test.txt"), 'w') as f:
f.writelines(test_list)
if __name__ == '__main__':
path = 'data/arthrosis'
for cat in os.listdir(path):
cat_path = os.path.join(path, cat)
data_img(cat_path)
data_split(cat_path)首先进行自适应直方图均衡化去雾,再进行数据增样,随机旋转生成多角度图像,并保存。接着遍历指定文件夹下图像进行同样处理,数量不足1000的类别进行更多增样。最后,将处理后的数据拆分为训练集和验证集,并写入对应文件。对医学影像数据进行预处理、增强和拆分,以便进行后续的机器学习模型训练和验证。
2.模型研发
我们使用的模型是yolov5。
在文件夹yolov5-master\data\coco128.yaml, 文件也可以保存在其他路径
# Classes
names:
0: Radius
1: Ulna
2: MCPFirst
3: MCP
4: ProximalPhalanx
5: DistalPhalanx
6: MiddlePhalanx
修改:yolov5-master\models\yolov5s.yaml
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 7 # number of classes
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
anchors:
- [10, 13, 16, 30, 33, 23] # P3/8
- [30, 61, 62, 45, 59, 119] # P4/16
- [116, 90, 156, 198, 373, 326] # P5/32修改trian.py文件,需要修改 epochs=100 、workers=1、resume=False 的值。
parser.add_argument("--weights", type=str, default=ROOT / "yolov5s.pt", help="initial weights path")
parser.add_argument("--cfg", type=str, default="", help="model.yaml path")
parser.add_argument("--data", type=str, default=ROOT / "data/VOC.yaml", help="dataset.yaml path")
parser.add_argument("--hyp", type=str, default=ROOT / "data/hyps/hyp.scratch-low.yaml", help="hyperparameters path")
parser.add_argument("--epochs", type=int, default=5, help="total training epochs")
parser.add_argument("--batch-size", type=int, default=16, help="total batch size for all GPUs, -1 for autobatch")使用yolov5-master\detect.py来进行侦测
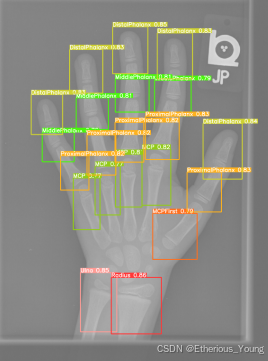
3.关节筛选
def bone_filter(data):
if data.shape[0] == 21:
# 0: Ulna
ulna = filter(data, [0], 0)
# 1: Radius
radius = filter(data, [0], 1)
# 2: MCPFirst
mcpFirst = filter(data, [0], 2)
# 3: MCP
mcp = filter(data, [0, 2], 3)
# 4: ProximalPhalanx
proximalPhalanx = filter(data, [0, 2, 4], 4)
# 5: DistalPhalanx
distalPhalanx = filter(data, [0, 2, 4], 5)
# 6: MiddlePhalanx
middlePhalanx = filter(data, [0, 2], 6)
return torch.cat([distalPhalanx, middlePhalanx, proximalPhalanx, mcp, mcpFirst, ulna, radius], 0)
else:
print("侦测结果错误")
return-
检查数据形状:
if data.shape[0] == 21:: 确保数据的第一个维度大小为 21,这通常表示数据有 21 个类别。
-
分类和过滤:
- 通过调用
filter函数,对不同的骨骼部位进行分类和过滤。每个骨骼部位的过滤条件不同:ulna: 过滤类别为 0 的数据。radius: 过滤类别为 1 的数据。mcpFirst: 过滤类别为 2 的数据。mcp: 过滤类别为 3,且类别为 0 或 2 的数据。proximalPhalanx: 过滤类别为 4,且类别为 0、2 或 4 的数据。distalPhalanx: 过滤类别为 5,且类别为 0、2 或 4 的数据。middlePhalanx: 过滤类别为 6,且类别为 0 或 2 的数据。
- 通过调用
-
拼接和返回结果:
torch.cat(...): 将不同骨骼部位的过滤结果按指定顺序拼接起来,然后返回。
4.小模型训练
import torch.optim
from tqdm import tqdm
import my_datasets
from torch.utils.data import DataLoader
from torchvision import models
from torch import nn
device = torch.device('cuda' if torch.cuda.is_available() else 'cup')
arthrosis = {'MCPFirst': ['MCPFirst', 11], # 第一手指掌骨
'DIPFirst': ['DIPFirst', 11], # 第一手指远节指骨
'PIPFirst': ['PIPFirst', 12], # 第一手指近节指骨
'MIP': ['MIP', 12], # 中节指骨(除了拇指剩下四只手指)(第一手指【拇指】是没有中节指骨的))
'Radius': ['Radius', 14], # 桡骨
'Ulna': ['Ulna', 12], # 尺骨
'PIP': ['PIP', 12], # 近节指骨(除了拇指剩下四只手指)
'DIP': ['DIP', 11], # 远节指骨(除了拇指剩下四只手指)
'MCP': ['MCP', 10]} # 掌骨(除了拇指剩下四只手指)
def train(item):
path = fr'data/arthrosis/{item}'
# 加载数据
train_dataset = my_datasets.My_dataset(path, mode='train')
train_loader = DataLoader(train_dataset, batch_size=20, shuffle=True)
test_dataset = my_datasets.My_dataset(path, mode='test')
test_loader = DataLoader(test_dataset, batch_size=20, shuffle=True)
# 网络
net = models.resnet18()
net.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
net.fc = nn.Linear(512, arthrosis[item][1])
net = net.to(device)
# 损失函数
loss_func = nn.CrossEntropyLoss()
# 优化器
opt = torch.optim.Adam(net.parameters())
best_acc = 0.
epochs = 100
for epoch in range(epochs):
# 开始训练
net.train()
train_loss = 0.
for img, lable in tqdm(train_loader):
img, lable = img.to(device), lable.to(device)
out = net(img)
loss = loss_func(out, lable)
opt.zero_grad()
loss.backward()
opt.step()
train_loss = train_loss + loss.item()
print(f"epoch == > {epoch}, train_loss = {train_loss/len(train_loader)}")
# 开始验证
net.eval()
test_loss = 0.
acc = 0.
for img, label in tqdm(test_loader):
img, label = img.to(device), label.to(device)
out = net(img)
loss = loss_func(out, label)
# 准确率
acc1 = torch.mean(torch.eq(out.argmax(dim=1), label).float())
acc = acc + acc1.item()
test_loss = test_loss + loss.item()
print(f"epoch == > {epoch} , test_loss = {test_loss/len(test_loader)}, acc = {acc/len(test_loader)}")
# 模型保存
if acc > best_acc:
torch.save(net.state_dict(), f"params/{item}_best.pt")
best_acc = acc
if acc/len(test_loader) > 0.98:
break
if __name__ == '__main__':
for item in arthrosis:
print(item)
train(item)-
数据准备:
- 从
my_datasets模块中加载自定义的数据集类My_dataset。 - 使用
DataLoader加载训练集和测试集。
- 从
-
模型定义:
- 使用
torchvision.models中的resnet18作为基础网络。 - 修改网络的第一层卷积和全连接层,以适应单通道输入和特定类别数。
- 使用
-
训练和评估:
- 使用交叉熵损失函数和 Adam 优化器进行训练。
- 每个 epoch 计算训练损失和测试损失,并评估准确率。
- 保存最佳模型,并在测试集准确率超过 98% 时停止训练。
5.pyside6部署
class MainWindow(QMainWindow, Ui_MainWindow):
def __init__(self):
super().__init__()
self.setupUi(self)
self.bing_slots()
self.my_detect = load_files.My_Detect(r'C:\Users\Lenovo\Desktop\yolov5arth',
r'C:\Users\Lenovo\Desktop\yolov5arth\best.pt')
self.img_path = None
#设置背景
def set_background(self):
background = QLabel(self)
pixmap = QPixmap(r"C:\Users\Lenovo\Desktop\yolov5arth\555.jpg") # 背景图片文件路径
background.setPixmap(pixmap)
background.resize(self.size())
background.lower()
def open_img(self):
self.label_2.setText("")
self.output.setPixmap(QPixmap())
print("点击了【选择X光片】按钮")
filepath = QFileDialog.getOpenFileName(self, dir=r'C:\Users\Lenovo\Desktop\yolov5arth\data\data_use', filter='*.png;*.jpg;*jpeg')
print(filepath)
self.img_path = filepath[0]
self.input.setPixmap(QPixmap(filepath[0]))
def detect_img(self):
print("点击了【侦测】按钮")
sex = 'boy' if self.radioButton.isChecked() else 'girl'
path_yolov5 = r'C:\Users\Lenovo\Desktop\yolov5arth'
path_pt = r'C:\Users\Lenovo\Desktop\yolov5arth\best.pt'
img_path = self.img_path
self.model_v5 = torch.hub.load(path_yolov5,
'custom',
path=path_pt,
source='local')
results = self.model_v5(img_path)
img = cv2.imread(img_path)
# 获取检测的目标坐标点
boxes = results.xyxy[0] # 关节数量21
boxes = common.bone_filter(boxes) # 关节数量13
print(self.img_path)
result, img = self.my_detect.detect2(self.img_path, sex)
self.label_2.setText(result)
h, w, c = img.shape
qimg = QImage(img, w, h, w*c, QImage.Format_RGB888)
self.output.setPixmap(QPixmap.fromImage(qimg))
# 绑定槽
def bing_slots(self):
self.pushButton.clicked.connect(self.open_img)
self.pushButton_2.clicked.connect(self.detect_img)
在虚拟环境中部署pyside6,使用designer对ui进行设计,将ui文件转化为py文件,并绑定信号和槽
6.特殊功能设计
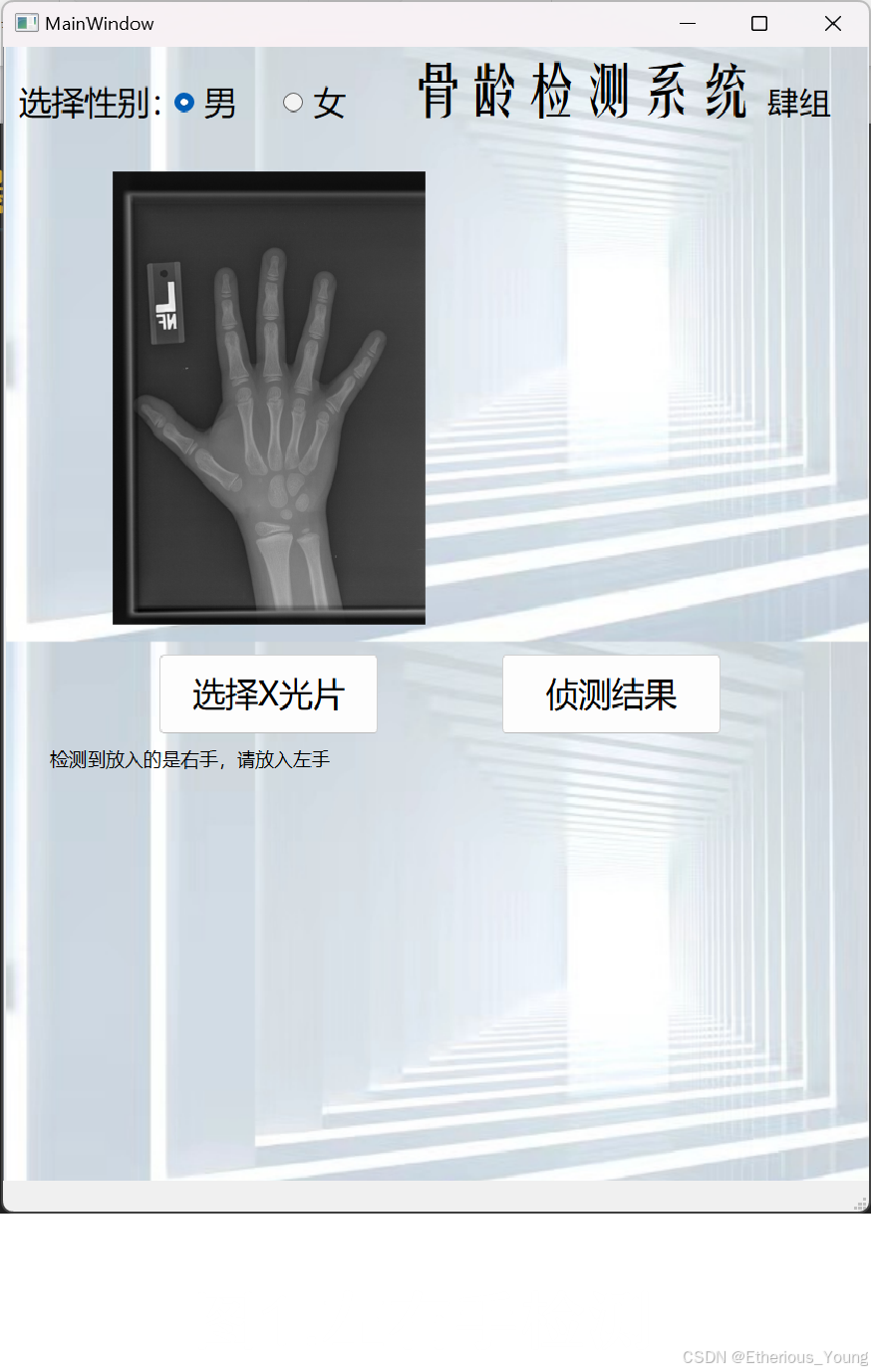
在骨龄检测中,对导入图片是需要要求的,首先需要是x光片,其次是要求是左手。
def detect_img(self):
print("点击了【侦测】按钮")
sex = 'boy' if self.radioButton.isChecked() else 'girl'
# 左右手检测
path_yolov5 = r'C:\Users\Lenovo\Desktop\yolov5arth'
path_pt = r'C:\Users\Lenovo\Desktop\yolov5arth\best.pt'
img_path = self.img_path
self.model_v5 = torch.hub.load(path_yolov5,
'custom',
path=path_pt,
source='local')
results = self.model_v5(img_path)
img = cv2.imread(img_path)
# 获取检测的目标坐标点
boxes = results.xyxy[0] # 关节数量21
boxes = common.bone_filter(boxes) # 关节数量13
if boxes is None:
self.label_2.setText("检测错误,请检查图片是否为x光片")
else:
MCPFirstCx = boxes[torch.where(boxes[:, 5] == 2)][0]
ulnaCx = boxes[torch.where(boxes[:, 5] == 1)][0]
if MCPFirstCx[0] < ulnaCx[0]:
self.label_2.setText("检测到放入的是右手,请放入左手")
else:
print(self.img_path)
result, img = self.my_detect.detect2(self.img_path, sex)
self.label_2.setText(result)
h, w, c = img.shape
qimg = QImage(img, w, h, w*c, QImage.Format_RGB888)
self.output.setPixmap(QPixmap.fromImage(qimg))对函数进行重写,加入了两个if语句,便可以达到此效果。
7.成果展示





















 1650
1650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











