










过拟合形象确实是最大似然方法的一个不好的性质,但我们在使用贝叶斯方法对参数进行求和或者积分时,过拟合不会出现。回归线性模型中的最小平方方法也同样会产生过拟合。虽然引入正则化可以控制具有多个参数的模型的过拟合问题,但是这也会产生一个问题,如何确定正则化系数 λ \lambda λ 。
我们已经知道当使用平方损失函数时,最优的预测由条件期望给出即 h ( x ) = E [ t ∣ x ] = ∫ t p ( t ∣ x ) d t h(x)=E[t|x]=\int tp(t|x)dt h(x)=E[t∣x]=∫tp(t∣x)dt
最优的最小平方预测由条件均值给出即 E ( t ∣ w ) = y ( x , w ) E(\mathrm{t}|w)=y(x,w) E(t∣w)=y(x,w) 简单的推导如下: 期望损失 E [ L ] = ∫ ∫ L ( t , y ( x ) ) p ( x , t ) d x d t E[L]=\int\int L(t,y(x))p(x,t)dxdt E[L]=∫∫L(t,y(x))p(x,t)dxdt
选用平方损失 L ( t , y ( x ) ) = ( t − y ( x ) ) 2 L(t,y(x))=(t-y(x))^{2} L(t,y(x))=(t−y(x))2, E [ L ] = ∫ ∫ ( t − y ( x ) ) 2 p ( x , t ) d x d t E[L]=\int\int (t-y(x))^{2}p(x,t)dxdt E[L]=∫∫(t−y(x))2p(x,t)dxdt 变分法求解 δ E ( L ) δ y ( x ) = 2 ∫ ( y ( x ) − t ) p ( x , t ) d t = 0 \frac{\delta E(L)}{\delta y(x)}=2\int (y(x)-t)p(x,t)dt=0 δy(x)δE(L)=2∫(y(x)−t)p(x,t)dt=0化解得 ∫ y ( x ) p ( x , t ) d t = y ( x ) p ( x ) = ∫ t p ( x , t ) d t \int y(x)p(x,t)dt=y(x)p(x)=\int tp(x,t)dt ∫y(x)p(x,t)dt=y(x)p(x)=∫tp(x,t)dt y ( x ) = ∫ t p ( x , t ) p ( x ) d t = E t [ t ∣ x ] y(x)=\int\frac{tp(x,t)}{p(x)}dt=E_{t}[t|x] y(x)=∫p(x)tp(x,t)dt=Et[t∣x]
我们也可以用一种不同的方式来推导出这个结果,这也会透露出回归问题的本质。 { y ( x ) − t } 2 = { y ( x ) − E [ t ∣ x ] + E [ t ∣ x ] − t } 2 \left\{ y(x)-t\right\}^{2}=\left\{ y(x)-E[t|x]+E[t|x]-t\right\}^{2} {y(x)−t}2={y(x)−E[t∣x]+E[t∣x]−t}2带入 E [ L ] E[L] E[L]后对t进行积分得到 E [ L ] = ∫ ( y ( x ) − h ( x ) ) 2 p ( x ) d x + ∫ ∫ ( h ( x ) − t ) 2 p ( t ) d t p ( x ) d t E[L]=\int (y(x)-h(x))^{2}p(x)dx+\int\int (h(x)-t)^{2}p(t)dtp(x)dt E[L]=∫(y(x)−h(x))2p(x)dx+∫∫(h(x)−t)2p(t)dtp(x)dt E [ L ] = ∫ { y ( x ) − E [ t ∣ x ] } 2 p ( x ) d x + ∫ v a r [ t ∣ x ] p ( x ) d x E[L]=\int \left\{ y(x)-E[t|x]\right\}^{2}p(x)dx+\int var[t|x]p(x)dx E[L]=∫{y(x)−E[t∣x]}2p(x)dx+∫var[t∣x]p(x)dx
从上面的公式中我们可以看到第二项是与 y ( x ) y(x) y(x)无关的,是由数据本身的噪声造成的,表示来期望损失能够达到的最小值。第一项与 y ( x ) y(x) y(x)有关,我们需要让这一项达到最小。理论上我们如果有够多的数据那么就能精确地拟合出一个在训练集上的完美解。但通常情况下受限于数据集我们不能精确地知道回归函数 h ( x ) h(x) h(x)。
如果我们使用由参数向量 w w w控制的函数 y ( x , w ) y(x,w) y(x,w)对 h ( x ) h(x) h(x)建模,那么从贝叶斯的观点来看,模型的不确定性是通过 w w w的后验概率分布来表示的。但频率学家的方法涉及到根据数据集 D D D对 w w w进行点估计,然后试着用下面的思想实验来表示估计的不确定性。
假设我们有很多数据集,每个数据集的大小为
N
N
N,都独立地从分布
p
(
x
,
t
)
p(x,t)
p(x,t)中抽取。对于数据集
D
D
D,得到一个预测函数
y
(
x
;
D
)
y(x;D)
y(x;D),那么第一项的形式可以写成
(
y
(
x
;
D
)
−
h
(
x
)
)
2
=
(
y
(
x
)
−
E
D
[
y
(
x
;
D
)
]
+
E
D
[
y
(
x
;
D
)
]
−
h
(
x
)
)
2
(y(x;D)-h(x))^{2}=(y(x)-E_{D}[y(x;D)]+E_{D}[y(x;D)]-h(x))^{2}
(y(x;D)−h(x))2=(y(x)−ED[y(x;D)]+ED[y(x;D)]−h(x))2现在我们关于D求期望
E
D
(
y
(
x
;
D
)
−
h
(
x
)
)
2
=
(
E
D
[
y
(
x
;
D
)
]
−
h
(
x
)
)
2
+
E
D
[
(
y
(
x
;
D
)
−
E
D
[
y
(
x
;
D
)
]
)
2
]
E_{D}(y(x;D)-h(x))^{2}=(E_{D}[y(x;D)]-h(x))^{2}+E_{D}[(y(x;D)-E_{D}[y(x;D)])^{2}]
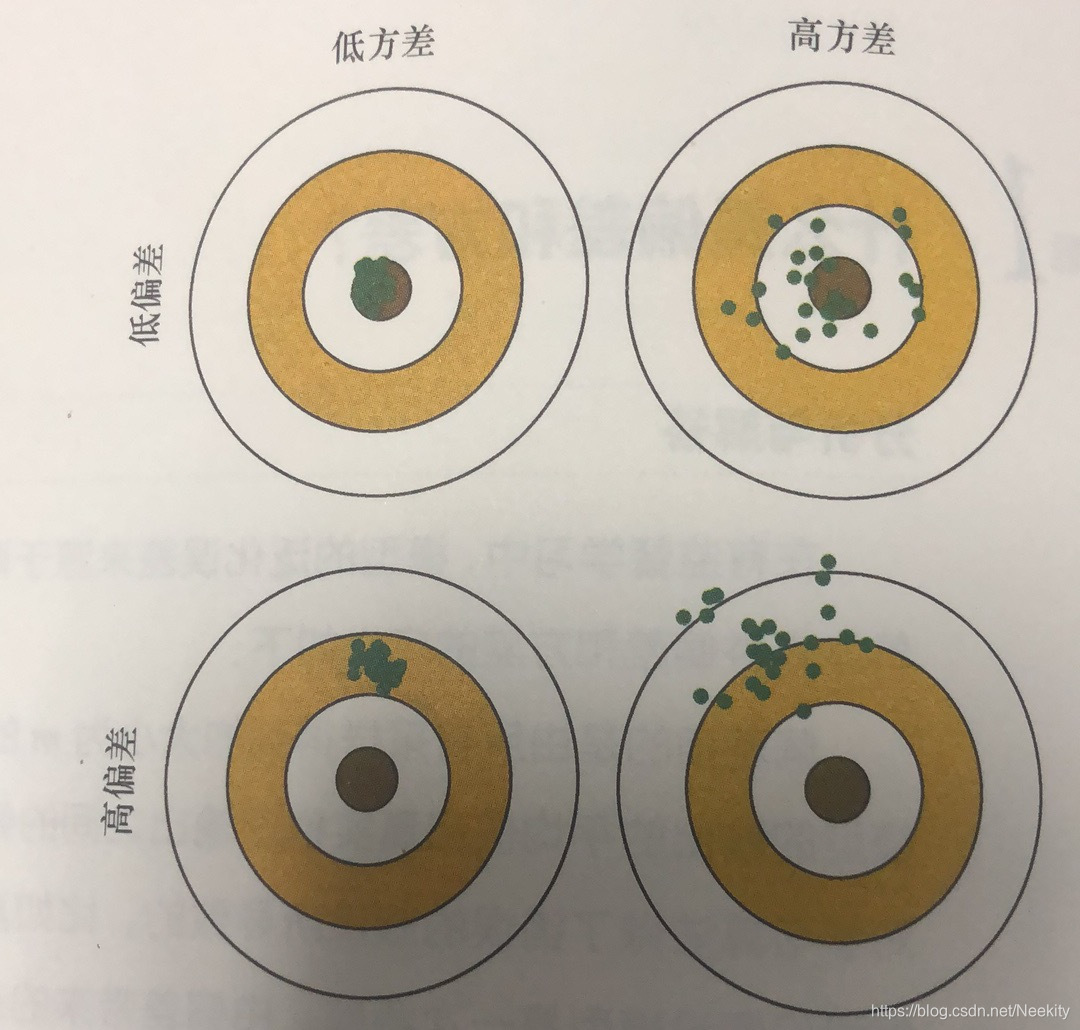
ED(y(x;D)−h(x))2=(ED[y(x;D)]−h(x))2+ED[(y(x;D)−ED[y(x;D)])2]第一项称为平方偏差,表示所有数据集的平均预测与预期的回归函数之间的差异;第二项被称为方差,度量来单独的数据集,模型所给出的解在平均值附近的波动情况。
由此我们已经得到了期望平方损失的分解
期
望
损
失
=
偏
差
2
+
方
差
+
噪
声
期望损失=偏差^{2}+方差+噪声
期望损失=偏差2+方差+噪声
我们的目标是最小化期望损失,所以最优的模型是在偏差和方差之间取得最优的平衡的模型。对于灵活的模型(
λ
\lambda
λ的取值较小)来说偏差小方差大;对于相对固定的模型(
λ
\lambda
λ的取值较大)来说偏差大方差小。所以
λ
\lambda
λ的选择要权衡两者。














 1983
1983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









