







 这篇博客详细介绍了斯坦福大学机器学习课程中的单变量线性回归模型,包括模型表示、代价函数的概念及其直观理解,以及梯度下降法在寻找最优参数中的应用。通过解释代价函数的数学形式和梯度下降的原理,阐述了如何通过迭代更新参数以最小化误差,为线性回归模型的训练提供了基础。
这篇博客详细介绍了斯坦福大学机器学习课程中的单变量线性回归模型,包括模型表示、代价函数的概念及其直观理解,以及梯度下降法在寻找最优参数中的应用。通过解释代价函数的数学形式和梯度下降的原理,阐述了如何通过迭代更新参数以最小化误差,为线性回归模型的训练提供了基础。
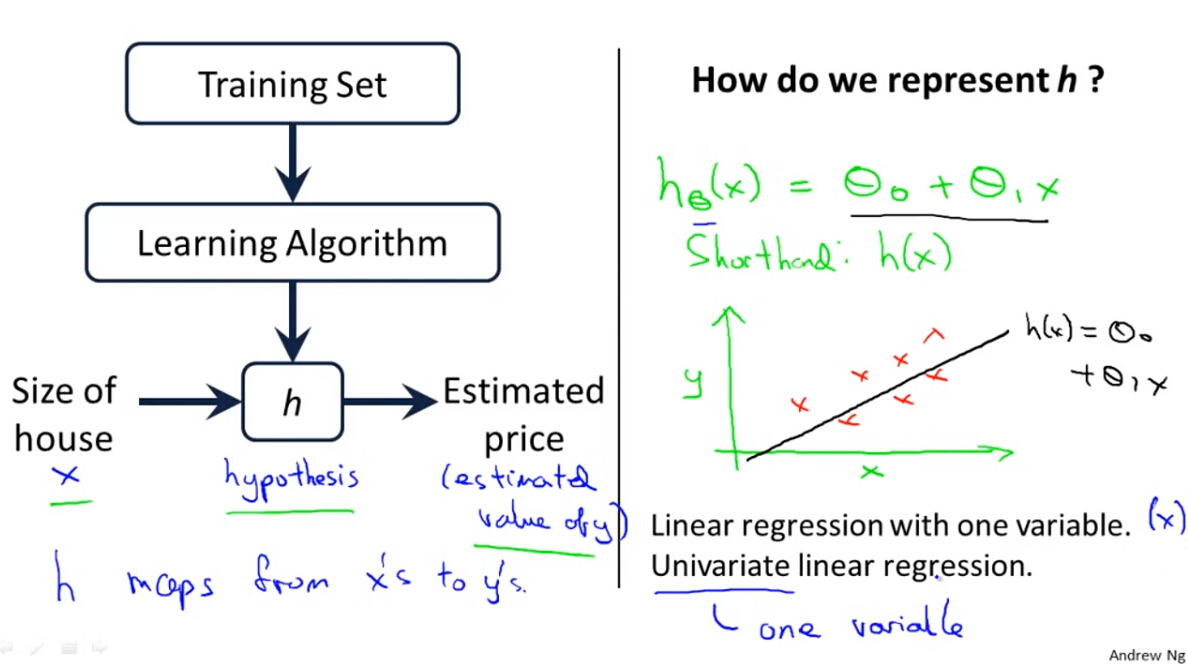
1. Model Representation
单变量线性回归即假设函数中 hθ(x) 只包含一个特征变量x,加上一个偏差值bias,即只包含两个参数 θ0 和 θ1 。
hθ(x)=θ0+θ1x
监督分类的基本流程是将训练样本输入学习算法,通过训练得到最优参数
Θ
,最后得到假设函数
h(x)
,然后用于回归预测。除了线性回归,还包括一些非线性回归,如指数、对数、多项式等。
2. Cost Function
代价函数J又叫误差平方函数,即所有样本的残差平方和。训练的目标是最小化代价函数,获取最优参数 Θ ,代价函数公式如下:
J(Θ)=12m∑i=1m(hθ(x(i))−y(i))2
目标函数是:
min J(Θ)

备注:整个课程中,除特殊说明,m都是指训练样本(training examples)的个数,n都是指特征的个数(feature),即特征维数(feature dimension),i指的是第i个样本( ith exam
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1607
1607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









