







1. Conrtributuion
提出了一种网络架构
1.1 Scale-recurrent Structure
对多尺度的分析
在成熟的多尺度方法中,每个尺度的求解器和相应参数通常相同。这在直觉上是一个自然的选择,因为在每个尺度上,我们的目标都是解决相同的问题。还发现,在每个尺度上改变参数会引入不稳定性,并导致非限制解空间的额外问题。另一个问题是输入图像可能具有不同的分辨率和运动比例。如果每个尺度可调,就容易使得网络对某个分辨率或者运动比例(剧烈程度)过拟合。
概括来讲
- 各个尺度参数共享
- 适用于各种分辨率以及运动比例
在经过 e n c o d e r encoder encoder后,特征图的语义信息丰富,但是空间信息丢失较多,联合不同尺度的特征信息,是不是就能一定程度上弥补这一问题。
1.2 Recurrent modules
利用隐藏状态捕获有用信息并且利于跨尺度恢复。这是本文对这一模块的功能描述
这必须谈到 c o a r s e − t o − f i n e coarse-to-fine coarse−to−fine式的恢复。在曾经的“人类感知”的论文中,是一个三尺度输入的网络架构,其中两个尺度就是:大小为 H ∗ W ∗ 3 H*W*3 H∗W∗3和大小为 H / 2 ∗ W / 2 ∗ 3 H/2*W/2*3 H/2∗W/2∗3,经查询发现,这是一种图像处理的策略,被称为图像金字塔,上篇论文中就用到了高斯金字塔式的输入。
在这个所谓的金字塔的输入中,不同的尺度之间就可以看作一个序列,本文提出的这个循环模块,就是为了融合三个尺度之间的特征,并且这三个尺度之间的特征还是经过 e n c o d e r encoder encoder提取过的特征。
1.3 Encoder/decoder ResBlock
本文并没有采用现有的编码解码器结构,据说是直接采用的话性能不够好,因此经过自己设计。但是借鉴了现有的ResBlock,这种ResBlock源于CVPR2017【Deep Multi-scale Convolutional Neural Network for Dynamic Scene Deblurring】,它不同于ResNet中的Res模块,在其基础上去掉了两个BN层(原因是原文采用的Batch-size是2,小于平常的Batch-size,可能认为没有必要),将最后的ReLu层去掉(提升了性能)
本文提出了将残差模块应用于编码解码器框架中,但应该并非首次提出,而是在他人的基础上提出的。在设计上,由于去模糊任务中希望感受野足够大,为了处理剧烈模糊,这就会导致下采样的次数不能太多,堆叠更多级别的编码解码器模块。
1.4 Network Frame
整体结构上同U-net模型极像,在具体实施方面,借鉴了ICCV2017论文【Detail-revealing deep video super-resolution】
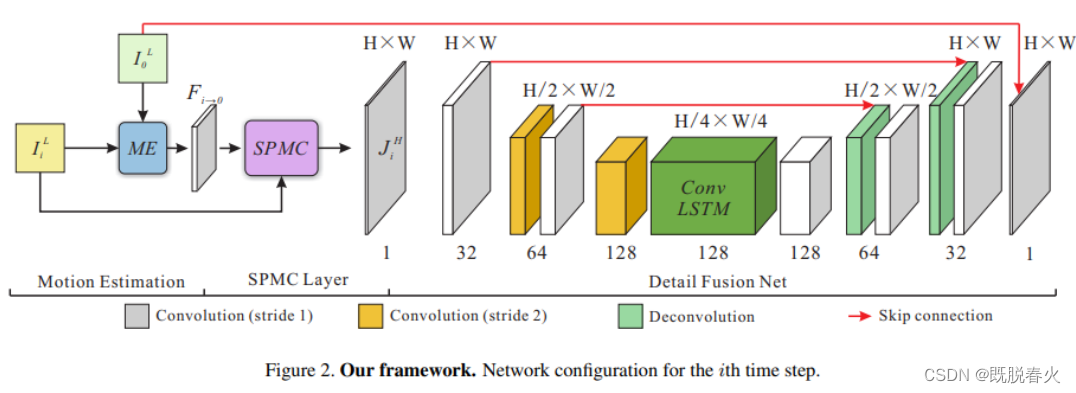
可以看出于本文提出的网络架构基本一致,通道数也相同,模块数也相同,不同的是将里面的模块替换成为了ResBlock
1.5 Summary
- 多尺度注意点(参数共享+鲁棒)
- 利用Recurrent模块实现中间特征的融合
- 运动模糊希望要较大的感受野(减少下采样+增多堆叠模块+5X5卷积)
2 Loss
对不同尺度采用了L2正则。应用完全变异和对抗性损失后,发现L2范数性能足够
3. Experiment
Dataset
Gopro Dataset
共3214对模糊/清晰图片,使用2103对训练,1111对测试
在变体实验和对比实验中均用到
Köhler Dataset
CVPR2016【A Comparative Study for Single Image Blind Deblurring】
真实场景:100张模糊图片(以man-made、natural、people/face、saturated、text描述图片内容),但是没有清晰图片。
合成场景:25张清晰图像,100张“uniform blurred”图像和100张“non-uniform blurred”图像,每张清晰图像都对应8张模糊的图像。
应该是仅用于对比试验
评价指标
- PSNR
- SSIM
- 参数量
- 处理时间
3.1 变体实验
3.2 相关方法
【Dynamic scene deblurring】ICCV2013
【Learning a convolutional neural network for non-uniform motion blur removal】CVPR2015
【Deep multi-scale convolutional neural network for dynamic scene deblurring】CVPR2017














 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









