







原文:Adversarial Malware Binaries_ Evading Deep Learning for Malware Detection in Executables
这篇文章研究了那些通过学习原生字节来判别恶意软件的神经网络模型的弱点(本文研究对象是MalConv模型),提出一种基于梯度的对抗攻击方法,通过改变恶意样本少于1%数量的末尾字节,即能以很高的概率躲避检测器网络模型的检测,同时保留原有的攻击功能。
PE文件
最重要的几个节:
.text,包含代码指令;
.data,包含初始化的全局变量和静态变量;
.rdata,包含常量以及附加信息(如debug);
.idata,包含导入信息。
对PE文件的操作:可在文件中没被利用的部分插入代码(如,添加一个从不会被使用的节),也可直接在文件末尾添加字节。不过,也有相应的应对方法。对于前者,可检查节是否会被代码用到;对于后者,可检查文件头或节表。复杂的修改需要以了解文件结构为前提,比如,修改.text节可能破坏程序的完整性,再比如,往已经存在的节添加字节的话,则需同时改文件头和节表。方便起见,本文只讨论末尾添加字节的情况。
Malconv模型概述
每个字节可表示为整数0~255中某个数值。首先将文件的字节序列x处理为k个整数表示定长整数向量(长度不够则补0,过长则截断)。将每个字节嵌入为8实数向量,即相当于此时输入值x被编码为矩阵。将Z分别传给两个分别使用ReLU和sigmoid作为激活函数的卷积层(后者作为门与前者连接起来,可用以防止由sigmoid造成的梯度消失问题)。后接一维最大池化层、全连接层(用ReLU激活)。为防止过拟合,用了DeCov正则化。输出值为f(x),若大于0.5,则判定为恶意样本。

对抗攻击
问题如下表示:

f(x)是对新样本x的预测分数,d是原样本x0和新样本x的差别字节数,q表示可增删改的字节数(在本文的情况是增填字节,也可理解为修改末尾附加的字节零)。
由于嵌入层在本质上是一个匹配表,所以MalConv架构是不可微的。为解决这个问题,需先计算每个字节在经过嵌入层后所得特征向量z_j在模型f中的梯度(可理解为函数f在特征z_j处的梯度)。
算法中各符号含义:
z_j:表示由样本的第j个字节x_j经过嵌入层后得到的特征向量。
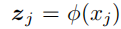
M:表示整数0~255经过嵌入后得到的256个特征向量的集合,其中的每一个向量用m_i表示(i=0,1,…,255)。
w_j:函数f在特征z_j处的梯度的负数。
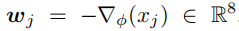
直线:
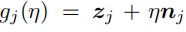
其中n_j表示与梯度相反的方向:

这条直线穿过点z_j,与向量w_j平行,η是一个变量,其是为了取遍直线上所有点。

理想状况下,假设梯度是常量,则在最小化f的过程中,点z_j沿着n_j的方向移动,最后要移到一个点,这个点是某个m_i在直线上的投影点,且该m_i到直线的距离最短;然后就将z_j对应的那个字节(即x_j)替换为m_i对应的那个字节。
对抗性恶意二进制代码的生成算法
原文如下:

输入:x0,即恶意软件,其中有k个具有信息的字节,以及d-k个填充字节;q,即填充字节中可被作为注入字节的字节数(k+q<=d);T,攻击的最大迭代数。
输出:x’,即对抗性恶意软件样本
1:设 x = x 0 x=x_0 x=x0
2:将 x x x中填充字节的前 q q q个用随机字节取代
3:初始化迭代计数器 t = 0 t=0 t=0
4:do:
5: t t t++
6: for p = 1 , . . . , q p=1,...,q p=1,...,q do
7: j = p + k j = p + k j=p+k #得到填充字节的起始处
8: w j = − ( x j ) w_j = -(x_j) wj=−(xj) #计算字节x_j的梯度
9: n j = w j ∣ ∣ w j ∣ ∣ 2 n_j = \frac{w_j}{||w_j||_2} nj=∣∣wj∣∣2wj #得到梯度的反方向的单位向量
10: for i = 0 , . . . , 255 i=0,...,255 i=0,...,255 do
11: s i = n j ∗ ( m i − z j ) s_i = n_j * (m_i - z_j) si=nj∗(mi−zj)#得到点z_j到m_i在n_j上的投影点的距离
12: d i = ∣ ∣ m i − ( z j + s i ∗ n j ) ∣ ∣ 2 d_i = ||m_i - (z_j + s_i * n_j)||_2 di=∣∣mi−(zj+si∗nj)∣∣2#得到m_i到向量n_j所在直线的距离
13: end for
14: 求 m i n { d i ∣ s i > 0 } min\{d_i | s_i > 0\} min{di∣si>0},得点m,将 x j x_j xj替代为m对应的那个字节。
15: end for
16:until f ( x ) < 0.5 f(x) < 0.5 f(x)<0.5 or t ≥ T t \ge T t≥T
17:return x’
实验
数据集:ViruShare,Citadel,APT1。通过搜索引擎得到的4000个善意文件。
攻击对象:作者自己训练的的一个MalConv,使用以上数据集,将之对半分为训练集和测试集。为消除因数据集划分形式的差异导致的偏差,作者将对网络的训练和测试过程重复了3次,然后将结果作平均计算。最终其平均准确率为92.83%±5.56%,召回率为84.68%±11.71%。
对抗攻击实验:
随机挑选200个恶意文件并使用算法1对它们作修改。设置攻击算法迭代次数为20,最大可注入字节数为10000。作为对比,除了算法1,作者还使用了注入随机字节的方法。作者计算了平均每个字节的逃避攻击成功率(即成功躲避检测的恶意文件的百分比)。
下图表示注入字节数与逃避攻击成功率的关系,蓝线表示基于梯度的攻击方法,可见其最终可达60%的成功率。

下面两个柱状图表示分别使用随机注入方法和基于梯度的攻击方法时,各个字节的分布状况(作者从成功逃避检测的对抗样本中找出一个来作统计)。可看到基于梯度的攻击方法中注入的不同字节只有大概5个。

下面的柱状图表示在字节位置离文件头越来越远时,其梯度的平均值的变化情况。可以看到其趋势是越来越小。作者的解释是,从文件头开始,越往后面,从字节中可获得的信息就越少。这也意味着,修改前面的字节可以更容易成功地逃避检测。然而修改前面的字节需要一些额外的工作来确保文件功能不变,作者称这是未来的一个工作。
















 834
834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









