






模型反演攻击:Neural Network Inversion in Adversarial Setting via Background Knowledge Alignment

背景
定义:
旨在通过模型的预测输出获取关于模型的训练数据或者测试数据的信息

方法
此前的模型反演攻击的方法主要有以下两类:
Optimization-based approach:
把反演问题变为一个优化问题,通过梯度构建出最佳的对应于目标类的数据
x
^
\widehat{x}
x
,目标是使得
F
w
(
x
)
F_{w}(x)
Fw(x)与
F
w
(
x
^
)
F_{w}(\widehat{x})
Fw(x
)尽可能接近。这一方法要求target model对于攻击者为白盒,生成的图像与真实的图像会有比较大的出入,而且该方法对于复杂模型如CNN无效。且在做测试的时候耗时比较长。
training-based approach:
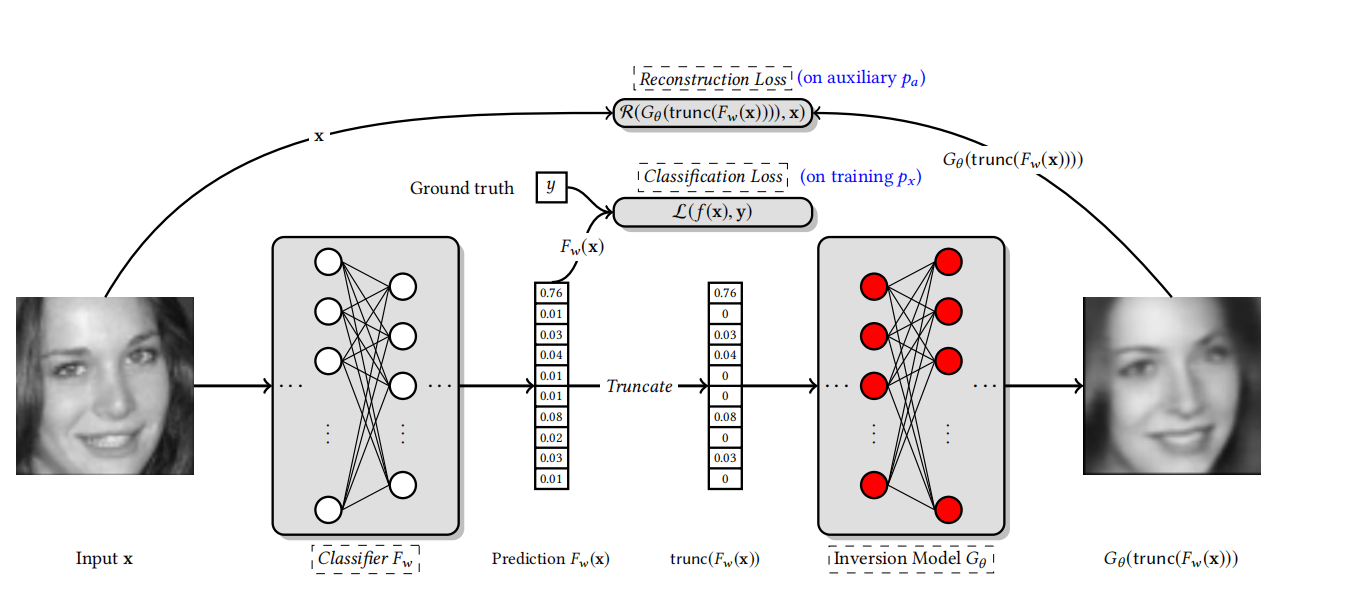
为了最大程度上重构一个图像,需要在和target model相同的training dataset上训练第二个模型
G
G
G。
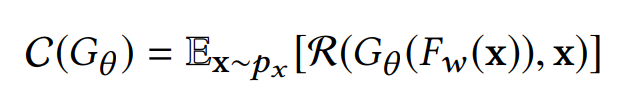
R R R是损失函数,文中选择了L2范数。 F w ( x ) F_{w}(x) Fw(x)是Target model在x上的输出, G θ ( F w ( x ) ) G_{\theta}(F_{w}(x)) Gθ(Fw(x))是经过重构之后的 x ^ \widehat{x} x ,目标是最小化 R ( x ^ , x ) R(\widehat{x},x) R(x ,x)。这种方法在训练的时候需要消耗大量的时间,但是在测试的时候很快。
攻击场景设定
两种典型的反演攻击的设定:
Data Reconstruction:
给定一个分类器的预测向量,要重构出所对应的输入
Training class inference:
恢复分类器的每个类的有语义的数据,例如人脸识别系统,要恢复出该系统所能识别的所有人脸的照片。
本文设置了三种攻击场景:
1.试图通过截断的输出向量来恢复输入数据
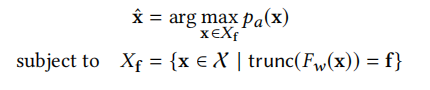
2.希望找到分类器的每个输出类的代表性数据,类似于training class inference
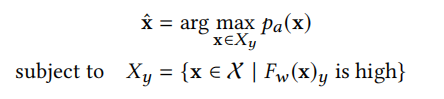
其中1,2中的 p a p_{a} pa表示的是比Target model的训练数据更加广泛数据分布,当目标模型为一个人脸识别系统的时候,这里的 p a p_{a} pa表示的就是一个很大的人脸库。 f f f是给定的截断的输出向量。
3.恶意的模型设计者,构建一个 F w ( x ) F_{w}(x) Fw(x)使其能够更好通过截断的输出向量来恢复受害者的输入数据
本文设定的前两种攻击场景的区别:
- 黑盒模型,只能获取模型的输出向量,而且攻击者可能只能获得部分的输出向量(截断)。而且由于不完整的输出向量对图像重构有很大影响。
截断的含义:

- 对抗性设置下,攻击者没有分类器的训练数据
方法论
对于1,2的攻击场景只需要通过优化下面这个损失函数即可,其中场景2对应于 m = 1 m=1 m=1的情况,即只知道样本的类信息。
核心公式:
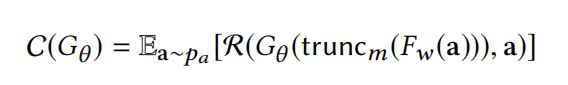
其中 a a a属于辅助数据集 D a u x i l i a r y D_{auxiliary} Dauxiliary,采样自 p a p_a pa。
对于攻击场景3,则是需要训练一个 F w ( x ) F_{w}(x) Fw(x)来帮助对数据的重构,因此在原本的分类模型的损失函数 L D ( f w ) L_{D}(f_{w}) LD(fw)后加一个正则项 R D ( f w , G θ ) R_{D}(f_{w},G_{\theta}) RD(fw,Gθ)来帮助 G θ G_{\theta} Gθ的训练,因为这个情况是恶意的设计者,所以他们可以获取训练数据,因此 x ∈ D x\in D x∈D。
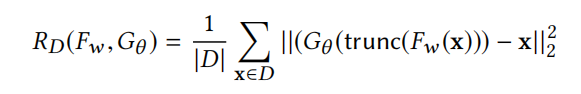
结果:
辅助训练集的选取:
本文选择了三类辅助训练集,分别为Same,Generic,还有Distinct这三类。以手写数字识别为例。
Same:
训练集为50%的数据,测试集为50%的数据,辅助数据集为那50%的测试数据
Generic:
80%的只还有某五类标签的数据,20%与训练集相同标签的剩余数据,辅助数据集:其余五类标签的数据
Distinct:
训练集为80%的数据,测试集为20%的数据,辅助数据集为CIFAR10
结果发现辅助数据集如果和Target model的训练数据集越相似则重构的效果越好,而当辅助数据集与Target model的训练数据集差别很大(Distinct)则效果较差。
截断的效果:
m较小的时候泛化能力比较强,倾向于为通用人脸。当m增大是,面部细节才逐渐增多,其中有趣的是红色方框中的那一列,在m较小的时候生成的为正面人脸,而当m逐渐增大的时候才倾向于生成与Groud Truth相似的侧面人脸。因为正面人脸能够比侧面的人脸能够更好的避免过拟合。
















 2055
2055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









