






自20世纪50年代以来,人工智能经历了漫长的发展历程,涌现出了许多具有里程碑意义的理论和技术。下面我们简要回顾人工智能的发展史,梳理一个简明的人工智能发展脉络。
人工智能的概念最早可以追溯到古希腊哲学家亚里士多德和中国古代哲学家墨子,他们探讨过关于人造机器和智能的可能性,但真正意义上的人工智能起源于20世纪。20 世纪 40 年代和 50 年代,计算机科学的发展为人工智能的研究奠定了基础。随着计算机技术的进步,人们开始尝试使用机器来模拟人类思维和解决问题的能力。
一、起源期(20世纪50年代)
1950年,英国数学家阿兰·图灵(Alan Turing)提出了著名的“图灵测试”,即通过判断一个机器是否能够展现出与人类不可区分的智能行为来定义人工智能。这一定义奠定了人工智能研究的基础。图灵测试不仅是一个思想实验,更是人工智能领域的第一块基石,是第一次有人尝试定义机器智能的标准。

阿兰·图灵
标志性成果一:达特茅斯会议(1956年)
1956年,人工智能的种子在达特茅斯学院的土壤中生根发芽。美国达特茅斯学院举办了一场为期两个月的夏季研讨会,旨在探讨人工智能这一新兴领域。在这次会议上,麦卡锡首次提出了“人工智能”这一术语,并将其定义为“制造智能机器的科学与工程”。

达特茅斯会议主要参与人员
这一年也因此被称为“人工智能元年”。当时出席大会的 10 位专家是:麦卡锡、明斯基、罗切斯特、香农、塞缪尔、纽厄尔、司马贺、塞弗里奇、所罗门诺夫和摩尔,都是人工智能领域的先驱。司马贺曾在1957 年预言十年内计算机下棋击败人类,不过实际上花了39 年。
标志性成果二:符号主义与逻辑推理
20世纪50年代,人工智能研究主要集中在符号主义方法上。符号主义认为,智能行为可以通过逻辑推理和符号操作来实现。在这一时期,纽维尔和西蒙开发了一个名为“逻辑理论家”的程序,该程序能够证明数学定理。此后,他们又开发了“通用问题求解器”,用于解决各种问题。
1952 年,美国的计算机游戏和人工智能领域先驱塞缪尔开发了第一个计算机下棋程序,被认为是最早的机器学习程序之一。塞缪尔还在1959 年首创“机器学习”一词。这一年,麦卡锡和明斯基牵头在麻省理工大学成立最早的人工智能实验室。
二、起步期(20世纪60年代)
20世纪60年代,人工智能开始从理论走向实践。研究人员开始关注如何让计算机自己学习,并尝试使用自然语言处理技术来让计算机理解人类语言。
标志性成果一:自然语言处理
20世纪60年代,人工智能研究开始关注自然语言处理。美国计算机科学家约瑟夫·魏泽堡开发了一个名为艾丽莎(ELIZA)的聊天机器人,能够模拟医生与患者之间的对话。尽管ELIZA的功能有限,但它开启了自然语言处理研究的新篇章。
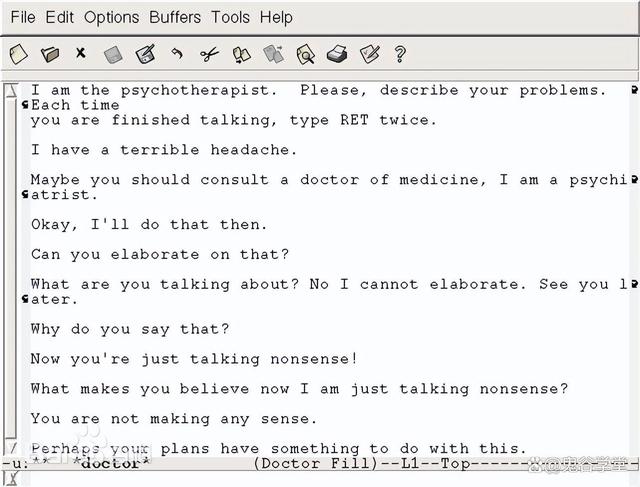
早期的聊天机器人ELIZA
标志性成果二:专家系统
在这一时期,人工智能研究开始关注知识表示和专家系统。知识表示研究如何将人类知识转化为计算机可以处理的形式,而专家系统则是一种模拟人类专家决策能力的计算机程序。其中,费根鲍姆领导的团队开发的DENDRAL系统,是第一个成功的专家系统。
专家系统是一种模拟人类专家解决问题能力的计算机程序,它通过集成特定领域的知识库和推理引擎,来模拟专家的决策过程,从而在复杂问题上提供专业建议或解决方案。这些系统通常依赖于规则和事实的集合,以及逻辑推理方法,以模拟专家的思考方式,解决特定领域的问题。

标志性成果三:感知机与神经网络
20世纪60年代,神经网络研究取得了重要进展。美国心理学家弗兰克·罗森布拉特提出了感知机模型,这是一种具有学习能力的神经网络。但在后来,由于感知机在处理非线性问题时存在局限,导致神经网络研究陷入低谷。
神经网络是一种模仿人脑神经元结构的计算模型,用于识别模式和处理复杂的数据。它由大量的节点(或称为“神经元”)组成,这些节点通过连接权重相互交流信息。神经网络通过学习输入数据与期望输出之间的关系,自动调整连接权重,从而能够对新的输入数据进行分类、识别或预测。这种学习过程通常涉及一个称为“训练”的迭代过程,其中网络不断优化其性能,直到达到一定的准确度或性能标准。
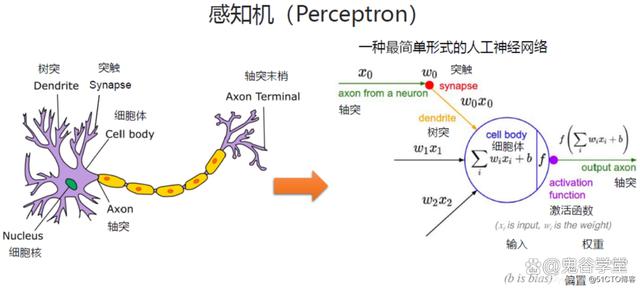
感知机是一种简单的人工神经网络,它模拟生物神经元的功能,用于二分类问题。它接收一组输入信号,这些信号通过权重加权后求和,如果加权和超过某个阈值,感知机就激活(输出1),否则不激活(输出0)。感知机是最早的机器学习模型之一,虽然它在处理复杂问题上存在局限性,但为后续更复杂神经网络的发展奠定了基础。
1961 年,第一台工业机器人 Unimate 开始在通用电气新泽西工厂试用。
也是在60年代,人们开始警惕人工智能可能给人类带来的威胁,并启发了后来众多科幻电影。
三、低谷期(20世纪70年代至80年代)
然而,人工智能的道路并非一帆风顺。20世纪70年代,人工智能研究遇到了瓶颈。由于技术限制和过高的期望,人工智能研究陷入低谷。计算机硬件性能的限制、数据不足以及算法的局限性,使得人工智能在很多领域的研究进展缓慢,导致公众对人工智能的期望过高而失望。许多研究项目无法取得预期的成果,导致资金和人才的流失。这一时期被称为“人工智能的寒冬”。尽管如此,这个时期的挑战也为后来的突破奠定了基础。

四、复苏期(20世纪80年代至21世纪初)
80年代,人工智能进入第二次发展高潮。随着计算机技术的进步和数据的积累,人工智能迎来了第二次春天。机器学习的概念开始流行,神经网络的研究也重新获得了关注。这个时期出现了很多经典的人工智能程序和算法。人工智能技术开始从实验室走向市场,许多公司开始投资于人工智能产品和服务。
标志性成果一:机器学习的兴起
20世纪80年代和 90 年代,机器学习技术的发展推动了专家系统的复兴,使人工智能研究重新焕发生机。专家系统在医疗、金融、地质勘探等领域得到了广泛应用,成为人工智能技术的一个重要分支。人们还利用数据来训练机器学习模型,使其能够自动学习和改进。IBM的“深蓝”在1997年战胜了国际象棋世界冠军,这是AI在复杂策略游戏中的一次重大胜利。
机器学习是人工智能的一个分支,它使计算机系统能够通过经验自我改进,而无需进行明确的编程。它涉及算法和统计模型的使用,这些算法和模型能够从数据中学习,并根据学到的信息做出决策或预测。简而言之,机器学习让计算机通过分析和理解大量数据,自动学习并提高其执行特定任务的能力。

标志性成果二:神经网络的复苏
在这一时期,神经网络研究逐渐复苏。反向传播算法的提出,使得多层神经网络得以训练为深度学习的发展铺平了道路。连接主义方法的兴起,也为神经网络研究提供了新的理论基础。
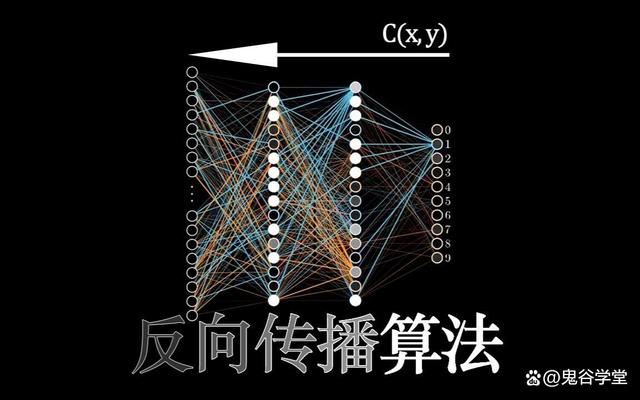
反向传播算法(Backpropagation),简称BP算法,是一种在神经网络中用于训练权重和偏置参数的高效算法。它通过计算网络输出与实际目标值之间的误差来调整网络中的参数,使得误差最小化。反向传播算法的核心是梯度下降法,它通过计算误差关于网络参数的梯度来更新这些参数。都是下一层的输入,同时应用激活函数进行非线性变换。
反向传播算法是深度学习和神经网络领域的基础,它使得复杂的神经网络模型训练成为可能,从而推动了人工智能在图像识别、语音识别、自然语言处理等多个领域的应用和发展。
五、加速期(21世纪初至2020年)
20世纪90年代,互联网的普及为人工智能研究提供了丰富的数据资源。大数据技术的发展,使得计算机可以处理和分析海量数据,为人工智能研究提供了新的机遇。
标志性成果一:深度学习与神经网络
21世纪初,深度学习技术的出现,使神经网络研究取得了突破性进展。深度学习通过构建多层神经网络,实现对复杂数据的抽象表示,从而在图像识别、语音识别等领域取得了显著成果。这一时期人工智能发展的里程碑事件包括人脸识别技术的普及应用,AlphaGo战胜人类围棋冠军等。

深度学习是机器学习的一个子领域,它通过使用多层(深层)的神经网络来模拟人脑处理数据的方式,从而实现复杂的模式识别和决策。这种学习方式特别擅长从原始数据如图像、声音和文本中自动学习高级特征,使得深度学习在图像识别、语音识别和自然语言处理等任务上取得了革命性的进展。
自我监督学习则是机器学习中的一种学习方法,它允许模型通过分析输入数据本身的结构和内在关系来自动学习特征表示,而无需外部的标签或指导。在自我监督学习中,模型通常被训练来预测数据中的某些未标记部分,或者执行一些任务,如排序、填充缺失值或识别数据中的异常模式。这种方法利用了数据的内在规律性,使得模型能够在没有显式监督信号的情况下学习有用的表示,进而可以应用于各种下游任务。
标志性成果二:人工智能应用领域的拓展
近年来,人工智能技术在各个领域的应用不断拓展。自动驾驶、智能家居、智能医疗、金融科技等新兴领域纷纷涌现,人工智能逐渐成为推动社会进步的重要力量。

六、爆发期(2020年至今)
随着计算能力的飞速提升和数据集的大规模增长,人工智能领域迎来了一个前所未有的爆发期。在这一时期,大模型的概念开始引领AI的发展,它们凭借庞大的参数数量和复杂的网络结构,在多个领域取得了突破性的进展。
在爆发期,人工智能领域经历了前所未有的增长和创新。大模型的出现不仅推动了技术的进步,也带来了新的挑战和机遇。这些模型的强大能力正在逐步改变我们与技术的互动方式,从智能助手到自动化决策系统,AI正成为我们日常生活和工作中不可或缺的一部分。
标志性成果一:大模型的兴起
如OpenAI的GPT系列和谷歌的BERT模型,它们通过数十亿甚至数千亿的参数,能够捕捉到语言的微妙细节,极大地推动了自然语言处理(NLP)的发展。这些模型在文本生成、机器翻译、问答系统等方面展现出了惊人的能力。
大模型(Large Models)指的是具有大量参数的人工智能模型,特别是在深度学习领域,这些模型通常由数十亿甚至数万亿个权重组成。这些模型之所以被称为“大”,是因为它们能够捕捉和学习数据中的复杂模式和关系,从而在各种任务上实现卓越的性能,如自然语言处理、图像识别和语音识别等。大模型通常需要大量的数据和计算资源来训练,但它们能够处理复杂的决策过程,提供更加精准和细致的预测。
标志性成果二:预训练和微调
预训练模型(如BERT、GPT)通过在大规模数据集上学习语言的通用表示,然后通过微调(fine-tuning)来适应特定任务,已成为提高AI性能的重要策略。这种方法使得模型能够快速适应新任务,且性能更加稳定。
预训练是一种在机器学习和深度学习中常用的技术,它涉及在特定任务上训练模型之前,先在大量数据上训练模型以学习通用特征。这个过程使得模型能够捕捉到数据的一般性规律,从而在后续的特定任务训练中更快地收敛,并提高最终任务的性能。预训练通常在大规模的未标记数据集上进行,目的是使模型具备一定的知识基础,之后再通过微调(fine-tuning)过程适应具体的下游任务。
标志性成果三:多模态学习
AI模型开始跨越单一数据类型的界限,通过整合视觉、语言和声音等多种信息源,实现了更为全面的理解能力。例如,CLIP(Contrastive Language–Image Pre-training)模型能够理解图像和相关描述之间的关系,从而在图像识别和视觉问答等任务上取得了显著成果。
多模态(Multimodality)是指在人工智能和机器学习领域中,模型能够处理和理解多种不同类型的数据输入(如文本、图像、声音等)的能力。这种技术使得模型可以综合多种信息源,从而更全面地理解复杂的场景和任务,提高决策的准确性和鲁棒性。多模态学习的一个关键挑战是设计能够有效融合不同模态信息的算法,以便模型能够从每种模态中提取有用的特征,并将它们结合起来进行更深层次的分析。
人工智能发展史是一部充满挑战与创新的历程。从最初的逻辑推理、专家系统,到如今的深度学习、大数据,人工智能技术不断突破传统边界,为人类社会带来了前所未有的变革。然而,人工智能的发展也面临着伦理、法律和政策等多方面的挑战。各国政府也开始关注人工智能政策,以引导和规范人工智能技术的发展。未来人工智能研究将继续致力于解决这些挑战,为人类创造更加美好的未来。
备注:图片来自鬼谷学堂

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









