






1、数据的读取
读取数据
import pandas as pd
import numpy as np
air = pd.read_csv("D:\\DM\\air_data_test.csv")
df = pd.DataFrame(air)
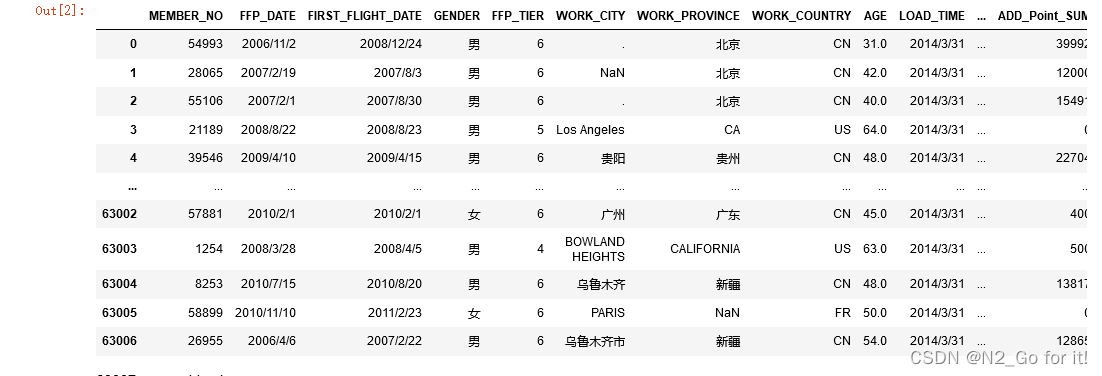
df
数据信息
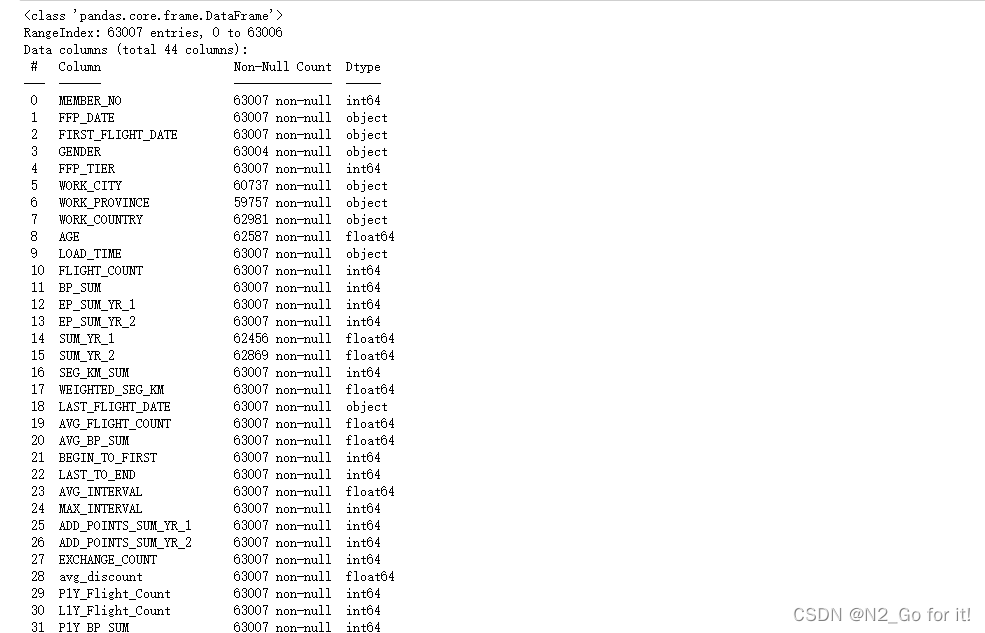
df.info()
#数据冗余
df.duplicated()
删除冗余行
df.drop_duplicates(inplace=True)
查看每列索引号和标签

for i,v in enumerate(df.columns):
print(i,v)
2、描述性统计分析
#从原数据的表格可以看到存在票价为0、工作城市为空值、年龄信息存在错误等情况。查看每列属性观测值中数值个数、最大值、最小值、以及四分位数等
#对数据的基本描述
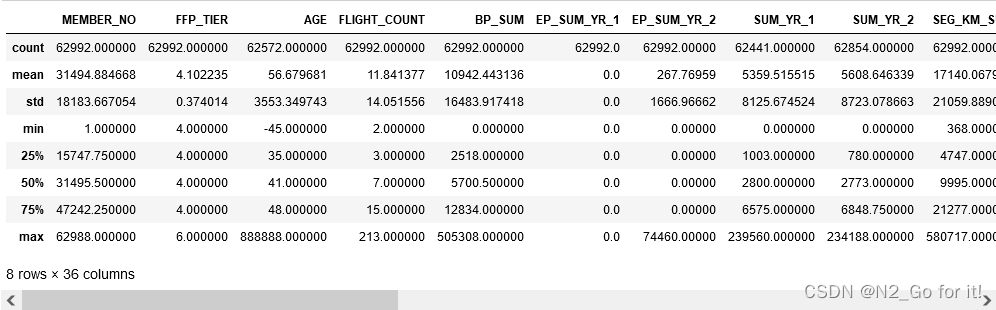
df.describe()
分布分析
(1)客户基本信息分布分析
使年龄不合理值为空值
df.loc[df['AGE']==888888]=None
df.loc[df['AGE']==-45]=None
处理缺失值-直接删除缺失值
df.dropna(axis=0,inplace=True)
import matplotlib.pyplot as plt
提取会员年龄
age =df['AGE'].dropna()
age = age.astype('int64')
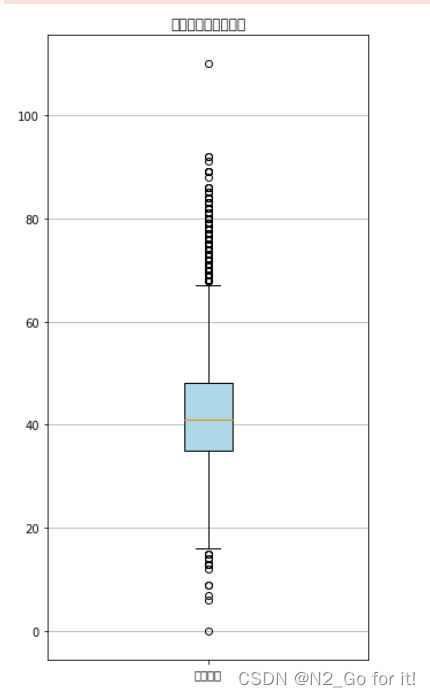
绘制会员年龄分布箱型图
fig = plt.figure(figsize = (5 ,10))
plt.boxplot(age,
patch_artist=True,
labels = ['会员年龄'], # 设置x轴标题
boxprops = {'facecolor':'lightblue'}) # 设置填充颜色
plt.title('会员年龄分布箱线图')
#### 显示y坐标轴的底线
```python
plt.grid(axis='y')
plt.show()
plt.close
3倍标准差外的数据存在较多 差异较大
提取会员入会年份
from datetime import datetime
ffp = df['FFP_DATE'].apply(lambda x:datetime.strptime(x,'%Y/%m/%d'))
ffp_year = ffp.map(lambda x : x.year)
绘制各年份会员入会人数直方图
fig = plt.figure(figsize = (8 ,5)) # 设置画布大小
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示
plt.rcParams['axes.unicode_minus'] = False
plt.hist(ffp_year, bins='auto', color='#0504aa')
plt.xlabel('年份')
plt.ylabel('入会人数')
plt.title('各年份会员入会人数')
plt.show()
plt.close
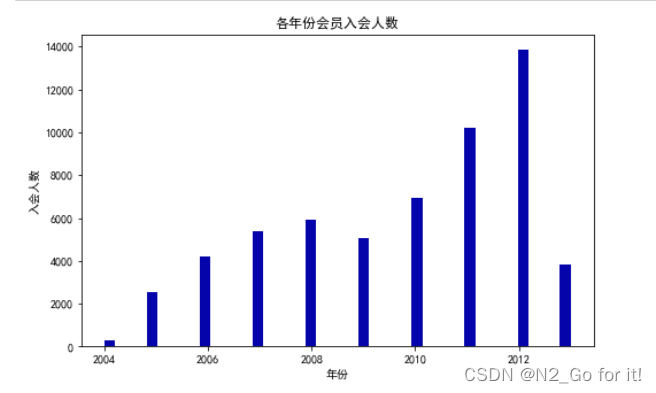
会员入会人数随着年份的增加总体呈现上升趋势
提取会员不同性别人数
male = pd.value_counts(df['GENDER'])['男']
female = pd.value_counts(df['GENDER'])['女']
绘制会员性别比例饼图
fig = plt.figure(figsize = (7 ,4)) # 设置画布大小
plt.pie([ male, female], labels=['男','女'], colors=['lightskyblue', 'lightcoral'],
autopct='%1.1f%%')
plt.title('会员性别比例')
plt.show()
plt.close

会员中男性数量远大于女性
提取会员总累计积分
ps = df['Points_Sum']
绘制会员总累计积分箱线图
fig = plt.figure(figsize = (5 ,8))
plt.boxplot(ps,
patch_artist=True,
labels = ['总累计积分'], # 设置x轴标题
boxprops = {'facecolor':'lightblue'}) # 设置填充颜色
plt.title('客户总累计积分箱线图')

显示y坐标轴的底线
plt.grid(axis='y')
plt.show()
plt.close
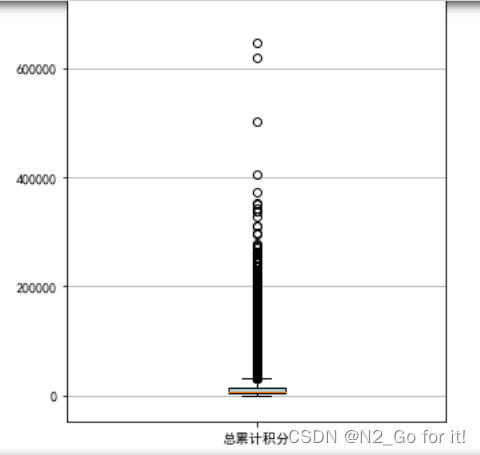
3倍标准差外的数据存在较多 客户总累计积分差异较大
(2)客户乘机信息分布分析
乘机信息类别
lte = df['LAST_TO_END']
fc = df['FLIGHT_COUNT']
sks = df['SEG_KM_SUM']
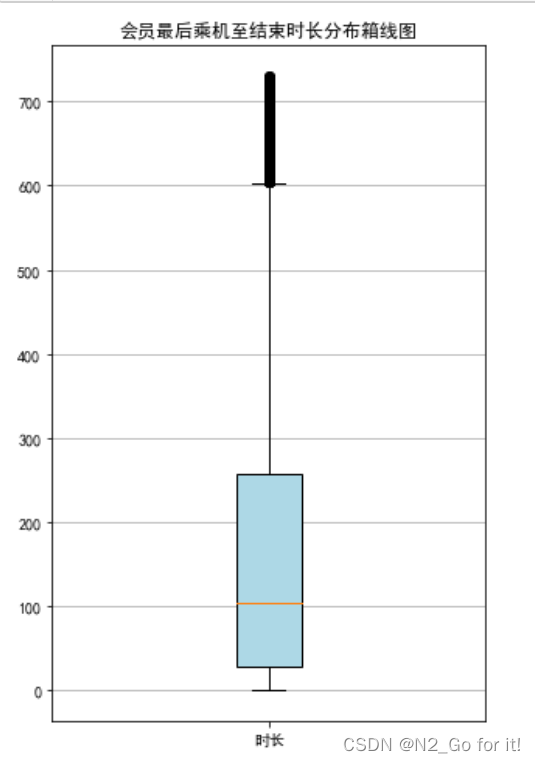
绘制最后乘机至结束时长箱线图
fig = plt.figure(figsize = (5 ,8))
plt.boxplot(lte,
patch_artist=True,
labels = ['时长'], # 设置x轴标题
boxprops = {'facecolor':'lightblue'}) # 设置填充颜色
plt.title('会员最后乘机至结束时长分布箱线图')
显示y坐标轴的底线
plt.grid(axis='y')
plt.show()
plt.close
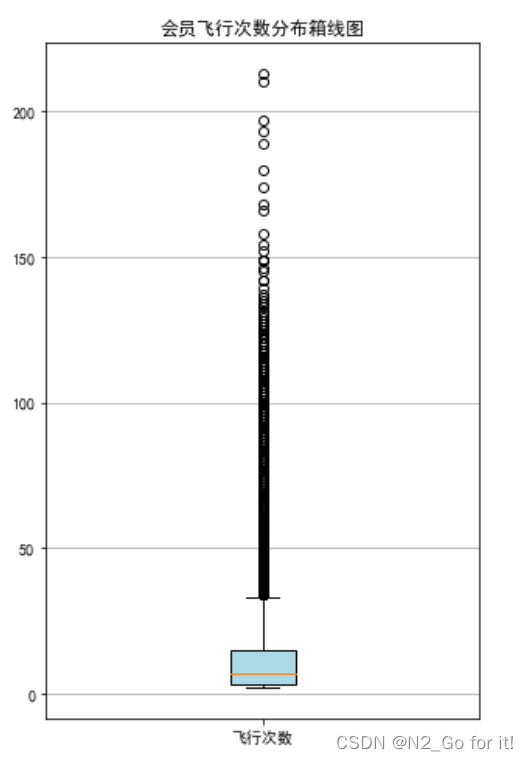
绘制客户飞行次数箱线图
fig = plt.figure(figsize = (5 ,8))
plt.boxplot(fc,
patch_artist=True,
labels = ['飞行次数'], # 设置x轴标题
boxprops = {'facecolor':'lightblue'}) # 设置填充颜色
plt.title('会员飞行次数分布箱线图')
显示y坐标轴的底线
plt.grid(axis='y')
plt.show()
plt.close
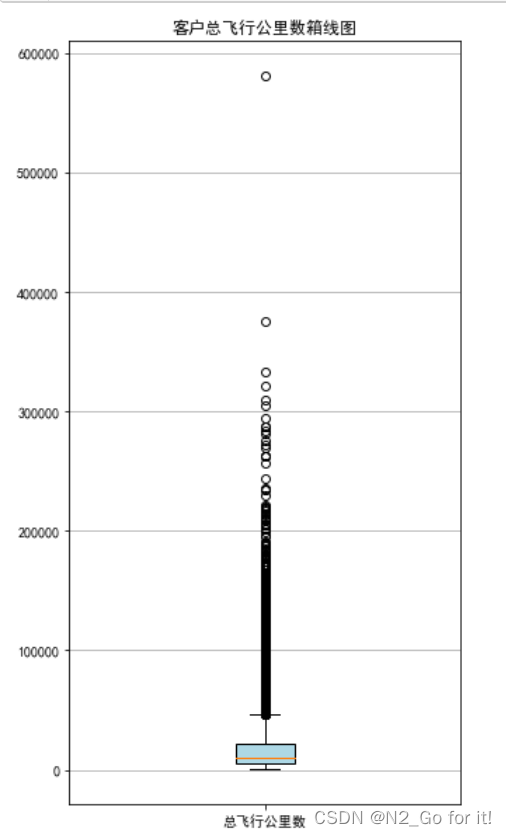
绘制客户总飞行公里数箱线图
fig = plt.figure(figsize = (5 ,10))
plt.boxplot(sks,
patch_artist=True,
labels = ['总飞行公里数'], # 设置x轴标题
boxprops = {'facecolor':'lightblue'}) # 设置填充颜色
plt.title('客户总飞行公里数箱线图')
显示y坐标轴的底线
plt.grid(axis='y')
plt.show()
plt.close
(3)积分信息分布分析
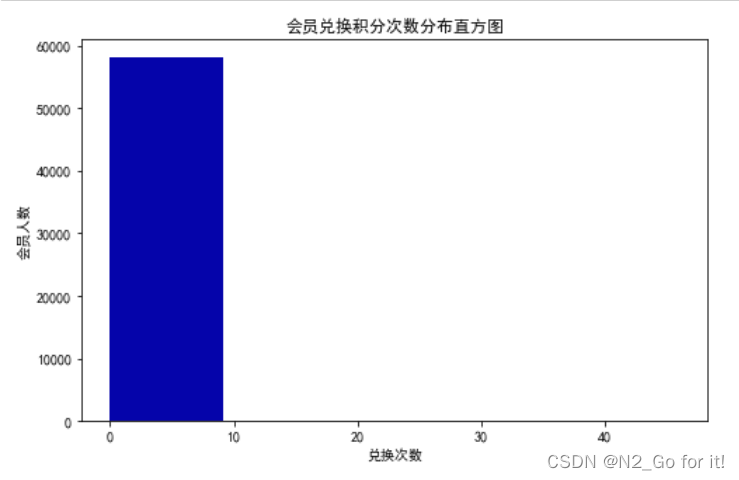
提取会员积分兑换次数
ec = df['EXCHANGE_COUNT']
绘制会员兑换积分次数直方图
fig = plt.figure(figsize = (8 ,5)) # 设置画布大小
plt.hist(ec, bins=5, color='#0504aa')
plt.xlabel('兑换次数')
plt.ylabel('会员人数')
plt.title('会员兑换积分次数分布直方图')
plt.show()
plt.close
提取会员总累计积分
ps = df['Points_Sum']
绘制会员总累计积分箱线图
fig = plt.figure(figsize = (5 ,8))
plt.boxplot(ps,
patch_artist=True,
labels = ['总累计积分'], # 设置x轴标题
boxprops = {'facecolor':'lightblue'}) # 设置填充颜色
plt.title('客户总累计积分箱线图')
显示y坐标轴的底线
plt.grid(axis='y')
plt.show()
plt.close
相关性分析
提取属性并合并为新数据集
data_corr = df[['FFP_TIER','FLIGHT_COUNT','LAST_TO_END',
'SEG_KM_SUM','EXCHANGE_COUNT','Points_Sum']]
age1 = df['AGE'].fillna(0)
data_corr['AGE'] = age1.astype('int64')
data_corr['ffp_year'] = ffp_year
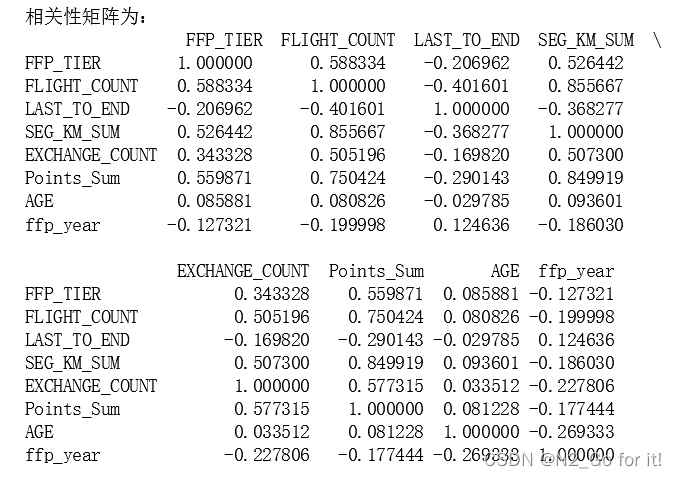
计算相关性矩阵
dt_corr = data_corr.corr(method = 'pearson')
print('相关性矩阵为:\n',dt_corr)
绘制热力图
import seaborn as sns
plt.subplots(figsize=(10, 10)) # 设置画面大小
sns.heatmap(dt_corr, annot=True, vmax=1, square=True, cmap='Blues')
plt.show()
plt.close
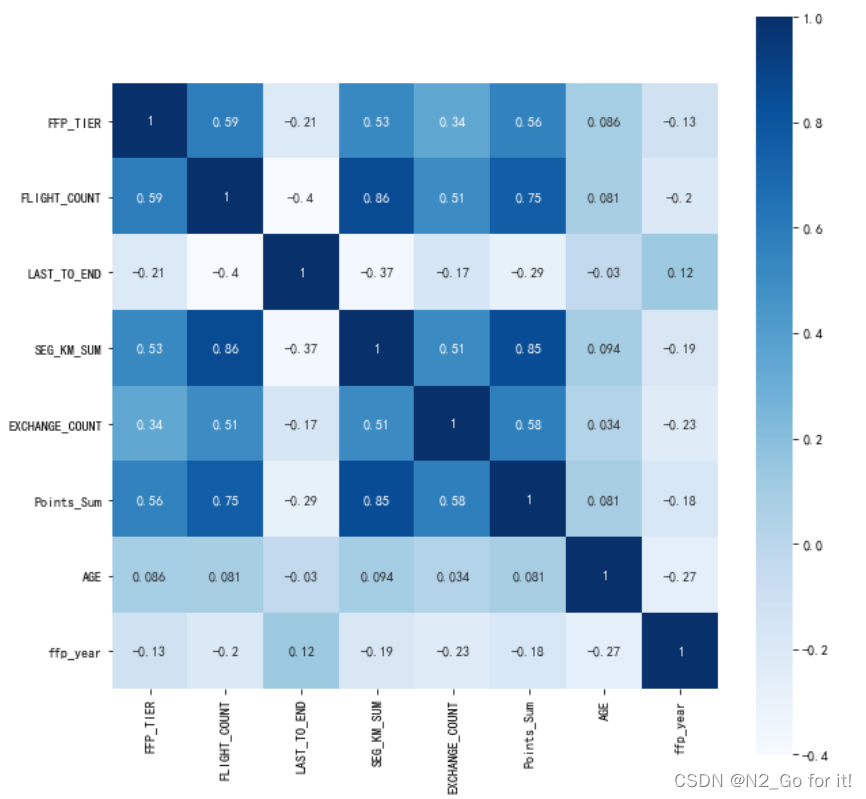
通过热力图直观的看到各个变量之间的相关关系。
数据预处理
1、数据清洗
观察数据发现原数据存在许多问题,例如票价为空值,总飞行公里数为0,数据重复等数据错误,可能是登记信息产生的错误,数据量大,去除之后影响不大,因此对这些数据进行丢弃
import numpy as np
df = "D:/DM/air_data_test.csv"#原数据
cleanedfile = "D:/DM/data_cleaned.csv" # 数据清洗后保存的文件路径
读取数据
airline_data = pd.read_csv(df,encoding = 'utf-8')
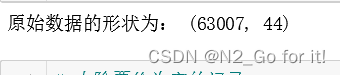
print('原始数据的形状为:',airline_data.shape)
去除票价为空的记录
airline_notnull = airline_data.loc[airline_data['SUM_YR_1'].notnull() &
airline_data['SUM_YR_2'].notnull(),:]
print('删除缺失记录后数据的形状为:',airline_notnull.shape)
只保留票价非零的,或者平均折扣率不为0且总飞行公里数大于0的记录。
index1 = airline_notnull['SUM_YR_1'] != 0
index2 = airline_notnull['SUM_YR_2'] != 0
index3 = (airline_notnull['SEG_KM_SUM']> 0) & (airline_notnull['avg_discount'] != 0)
index4 = airline_notnull['AGE'] > 100 # 去除年龄大于100的记录
airline = airline_notnull[(index1 | index2) & index3 & ~index4]
print("数据清洗后数据的形状为:",airline.shape)
airline.to_csv(cleanedfile) # 保存清洗后的数

从上面的的输出结果可以看到GENDER WORK_CITY WORK_PROVINCE WORK_COUNTRY AGE SUM_YR_1 SUM_YR_2 这些列存在缺失值以及数据有冗余接下来对对数据进行去除空值以及去除冗余行
2、数据变换
属性选择、构造与数据标准化
读取数据清洗后的数据
cleanedfile = 'D:\\DM\\data_cleaned.csv' # 数据清洗后保存的文件路径
airline = pd.read_csv(cleanedfile, encoding = 'utf-8')
选取需求属性
airline_selection = airline[['FFP_DATE','LOAD_TIME','LAST_TO_END',
'FLIGHT_COUNT','SEG_KM_SUM','avg_discount']]
print('筛选的属性前6行为:\n',airline_selection.head())

构造属性L
L = pd.to_datetime(airline_selection['LOAD_TIME']) - \
pd.to_datetime(airline_selection['FFP_DATE'])
L = L.astype('str').str.split().str[0]
L = L.astype('int')/30
合并属性
airline_features = pd.concat([L,airline_selection.iloc[:,2:]],axis = 1)
airline_features.columns = ['L','R','F','M','C']
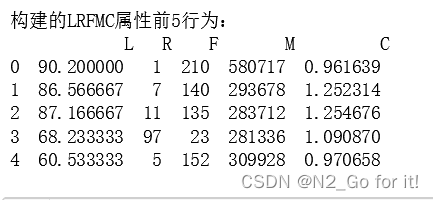
print('构建的LRFMC属性前5行为:\n',airline_features.head())
airline_features.to_excel('D:/DM/聚类RFM.xls')
数据标准化
```python
from sklearn.preprocessing import StandardScaler
data = StandardScaler().fit_transform(airline_features)
np.savez('D:\\DM\\airline_scale.npz',data)
print('标准化后LRFMC五个属性为:\n',data[:5,:])

from sklearn.cluster import KMeans
模型构建
读取标准化后的数据
airline_scale = np.load('D:\\DM\\airline_scale.npz')['arr_0']
k = 5 # 确定聚类中心数
构建模型,随机种子设为123
kmeans_model = KMeans(n_clusters = k,n_jobs=4,random_state=123)
fit_kmeans = kmeans_model.fit(airline_scale) # 模型训练
# 查看聚类结果
```python
kmeans_cc = kmeans_model.cluster_centers_ # 聚类中心
print('各类聚类中心为:\n',kmeans_cc)
kmeans_labels = kmeans_model.labels_ # 样本的类别标签
print('各样本的类别标签为:\n',kmeans_labels)
r1 = pd.Series(kmeans_model.labels_).value_counts() # 统计不同类别样本的数目
print('最终每个类别的数目为:\n',r1)
输出聚类分群的结果
cluster_center = pd.DataFrame(kmeans_model.cluster_centers_,\
columns = ['ZL','ZR','ZF','ZM','ZC']) # 将聚类中心放在数据框中
cluster_center.index = pd.DataFrame(kmeans_model.labels_ ).\
drop_duplicates().iloc[:,0] # 将样本类别作为数据框索引
print(cluster_center)

%matplotlib inline
import matplotlib.pyplot as plt
客户分群雷达图
labels = ['ZL','ZR','ZF','ZM','ZC']
legen = ['客户群' + str(i + 1) for i in cluster_center.index] # 客户群命名,作为雷达图的图例
lstype = ['-','--',(0, (3, 5, 1, 5, 1, 5)),':','-.']
kinds = list(cluster_center.iloc[:, 0])
由于雷达图要保证数据闭合,因此再添加L列,并转换为 np.ndarray
cluster_center = pd.concat([cluster_center, cluster_center[['ZL']]], axis=1)
centers = np.array(cluster_center.iloc[:, 0:])
分割圆周长,并让其闭合
n = len(labels)
angle = np.linspace(0, 2 * np.pi, n, endpoint=False)
angle = np.concatenate((angle, [angle[0]]))
绘图
fig = plt.figure(figsize = (8,6))
ax = fig.add_subplot(111, polar=True) # 以极坐标的形式绘制图形
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
画线
for i in range(len(kinds)):
ax.plot(angle, centers[i], linestyle=lstype[i], linewidth=2, label=kinds[i])
添加属性标签
ax.set_thetagrids(angle * 180 / np.pi, labels)
plt.title('客户特征分析雷达图')
plt.legend(legen)
plt.show()
plt.close
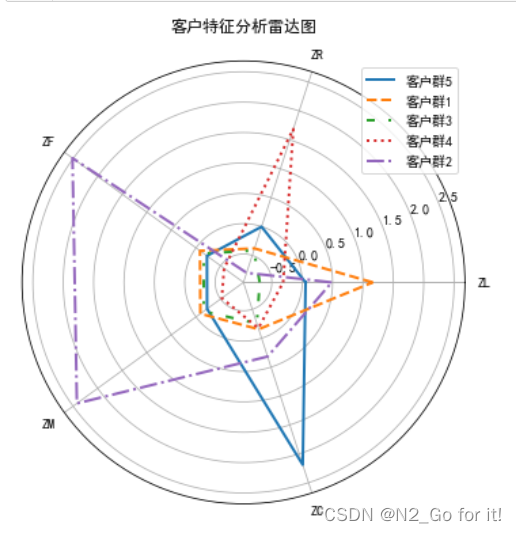
#其中,客户群1在特征F、M处的值最大,在特征R处的值较小,客户群1的会员频繁乘机且近期都有乘机记录;
客户群2在特征C上的值最大,且在特征F上的值最小,说明客户群2是偏好乘坐高级舱位的客户群;
客户群3在特征L处的值最大,在特征R处的值都较小,客户群3入会时间较长,飞行频率也较高,是有较高价值的客户群;
客户群4在所有特征上的值都很小,且在特征L处的值最小,说明客户群4属于新入会员较多的客户群;
客户群5在特征R处的值最大,在特征F、M处的值较小,其他特征值都比较适中,说明客户群5已经很久没有乘机,是人会时间较短的低价值的客户群;
data
k = 3 # 聚类的类别
threshold = 2 # 离散点阈值
iteration = 1000 # 聚类最大循环次数
data = pd.read_excel('D:\\DM\\聚类RFM.xls', index_col = 'Id') # 读取数据
data_zs = 1.0*(data - data.mean())/data.std() # 数据标准化
from sklearn.cluster import KMeans
model = KMeans(n_clusters = k, n_jobs = 4, max_iter = iteration) # 分为k类,并发数4
model.fit(data_zs) # 开始聚类
标准化数据及其类别
r = pd.concat([data_zs, pd.Series(model.labels_, index = data.index)], axis = 1) # 每个样本对应的类别
r.columns = list(data.columns) + ['聚类类别'] # 重命名表头
r['聚类类别'].value_counts()
model.cluster_centers_[:,1:4]
r[['R', 'F', 'M']][r['聚类类别'] == 0]
norm = []
for i in range(k): # 逐一处理
norm_tmp = r[['R', 'F', 'M']][r['聚类类别'] == i]-model.cluster_centers_[:,1:4][i]
norm_tmp = norm_tmp.apply(np.linalg.norm, axis = 1) # 求出绝对距离
norm.append(norm_tmp/norm_tmp.median()) # 求相对距离并添加
norm = pd.concat(norm) # 合并
import matplotlib.pyplot as plt
plt.figure(figsize=(10,8))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
norm[norm <= threshold].plot(style = 'go') # 正常点
discrete_points = norm[norm > threshold] # 离群点
discrete_points.plot(style = 'ro')
for i in range(len(discrete_points)): # 离群点做标记
id = discrete_points.index[i]
n = discrete_points.iloc[i]
plt.annotate('(%s, %0.2f)'%(id, n), xy = (id, n), xytext = (id, n))
plt.xlabel('编号')
plt.ylabel('相对距离')
plt.show()















 1994
1994











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









