







朴素贝叶斯算法介绍
朴素贝叶斯,之所以称为朴素,是因为其中引入了几个假设(不用担心,下文会提及)。而正因为这几个假设的引入,使得模型简单易理解,同时如果训练得当,往往能收获不错的分类效果,因此这个系列以naive bayes开头和大家见面。
因为朴素贝叶斯是贝叶斯决策理论的一部分,所以我们先快速了解一下贝叶斯决策理论。
假设有一个数据集,由两类组成(简化问题),对于每个样本的分类,我们都已经知晓。数据分布如下图:
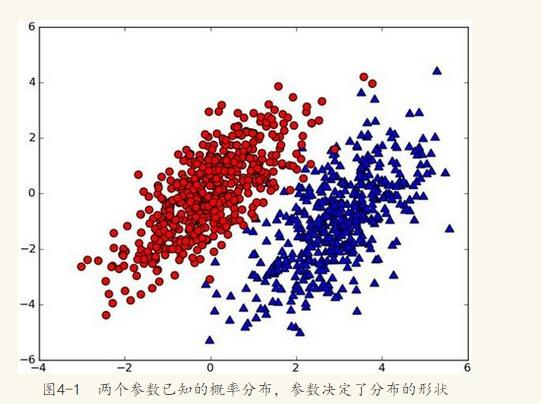
现在,出现一个新的点
(
x
,
y
)
(x,y)
(x,y),其分类位置。假设我们以
p
1
(
x
,
y
)
p_1(x,y)
p1(x,y)和
p
2
(
x
,
y
)
p_2(x,y)
p2(x,y)分别表示数据点属于红色一类的概率和属于蓝色一类的概率。
我们提出这样的规则:
如果
p
1
(
x
,
y
)
>
p
2
(
x
,
y
)
p_1(x,y)>p_2(x,y)
p1(x,y)>p2(x,y),那么点
(
x
,
y
)
(x,y)
(x,y)属于红色方,否则属于蓝色方。
换人类的语言来描述这一规则:选择概率高的一类作为新点的分类。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。
现在,用条件概率的方式定义这一贝叶斯分类准则:
p
(
r
e
d
∣
x
,
y
)
>
p
(
b
l
u
e
∣
x
,
y
)
p(red|x,y)>p(blue|x,y)
p(red∣x,y)>p(blue∣x,y),那么点
(
x
,
y
)
(x,y)
(x,y)属于红色方,否则如果
p
(
r
e
d
∣
x
,
y
)
<
p
(
b
l
u
e
∣
x
,
y
)
p(red|x,y)<p(blue|x,y)
p(red∣x,y)<p(blue∣x,y),那么点属于
(
x
,
y
)
(x,y)
(x,y)蓝色方。
所以,如果不是二元的分类,而是多元的。
那么我们只需要计算:
m
a
x
(
p
(
c
1
∣
x
,
y
)
,
p
(
c
2
∣
x
,
y
)
,
p
(
c
3
∣
x
,
y
)
,
.
.
.
)
max(p(c1|x,y),p(c2|x,y),p(c3|x,y),...)
max(p(c1∣x,y),p(c2∣x,y),p(c3∣x,y),...)
在概率论中,我们知道该公式:
p
(
c
∣
x
)
=
p
(
x
∣
c
)
p
(
c
)
p
(
x
)
p(c|x)=\frac{p(x|c)p(c)}{p(x)}
p(c∣x)=p(x)p(x∣c)p(c)
比如:
判断一条微信朋友圈是不是广告。
前置条件是:我们已经拥有了一个平日广大用户的朋友圈内容库,这些朋友圈当中,如果真的是在做广告的,会被“热心网友”打上“广告”的标签,我们要做的是把所有内容分成一个一个词,每个词对应一个维度,构建一个高维度空间 (别担心,这里未出现向量计算)。
当出现一条新的朋友圈ad,我们也将其分词,然后投放到朋友圈词库空间里。
P
(
a
d
∣
X
)
=
p
(
X
∣
a
d
)
p
(
a
d
)
p
(
X
)
P(ad|X)=\frac{p(X|ad)p(ad)}{p(X)}
P(ad∣X)=p(X)p(X∣ad)p(ad),该概率表示,已知朋友圈内容而这条朋友圈是广告的概率。这里的
X
X
X表示多个特征(词)
x
1
,
x
2
,
x
3
.
.
.
x_1,x_2,x_3...
x1,x2,x3...组成的特征向量。
所以,由公式:
P
(
n
o
t
−
a
d
∣
X
)
=
p
(
X
∣
n
o
t
−
a
d
)
p
(
n
o
t
−
a
d
)
p
(
X
)
P(not-ad | X) = \frac{p(X|not-ad)p(not-ad) }{p(X)}
P(not−ad∣X)=p(X)p(X∣not−ad)p(not−ad)
比较上面两个概率的大小,如果 p ( a d ∣ X ) > p ( n o t − a d ∣ X ) p(ad|X) > p(not-ad|X) p(ad∣X)>p(not−ad∣X),则这条朋友圈被划分为广告,反之则不是广告。
朴素贝叶斯定义
- 设 X = { x 1 , x 2 , x 3 . . . } X=\{x_1,x_2,x_3...\} X={x1,x2,x3...}为一个待分类项,而每个 x i x_i xi为 X X X的一个特征属性。
- 由目标类别集合 C = { c 1 , c 2 , c 3 , . . . } C=\{c_1,c_2,c_3,...\} C={c1,c2,c3,...}
- 计算 m a x { P ( c 1 ∣ x ) , P ( c 2 ∣ x ) , P ( c 3 ∣ x ) . . . } max\{P(c_1|x),P(c_2|x),P(c_3|x)...\} max{P(c1∣x),P(c2∣x),P(c3∣x)...},最终结果就是最大概率的那个类别。
那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做:
- 找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
- 统计得到在各类别下各个特征属性的条件概率估计。即。
- 如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
p ( c i ∣ x ) = p ( x ∣ c i ) p ( c i ) p ( x ) p(c_i|x)=\frac{p(x|c_i)p(c_i)}{p(x)} p(ci∣x)=p(x)p(x∣ci)p(ci)
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是独立的(这里要引入朴素贝叶斯假设了。如果认为每个词都是独立的特征,彼此之前没有必然联系,虽然现实中,一条朋友圈内容中,相互之间的词不会是相对独立的,因为我们的自然语言是讲究上下文的),所以有:
P
(
x
∣
c
i
)
P
(
c
i
)
=
P
(
x
1
∣
c
i
)
P
(
x
2
∣
c
i
)
.
.
.
P
(
x
n
∣
c
i
)
⋅
P
(
c
i
)
=
P
(
c
i
)
⋅
∏
j
=
1
m
P
(
x
i
∣
c
i
)
P(x|c_i)P(c_i)=P(x_1|c_i)P(x_2|c_i)...P(x_n|c_i)·P(c_i)=P(c_i)·\prod_{j=1}^{m}P(x_i|c_i)
P(x∣ci)P(ci)=P(x1∣ci)P(x2∣ci)...P(xn∣ci)⋅P(ci)=P(ci)⋅∏j=1mP(xi∣ci)
回到上一节的栗子,至此, P ( x i ∣ a d ) P(x_i|ad) P(xi∣ad)很容易求解(每个词在朋友圈里出现的概率), P ( a d ) P(ad) P(ad)为词库中广告朋友圈占所有朋友圈(训练集)的概率。我们的问题也就迎刃而解了。














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









