







目录
一、文件内容查看命令
cat
cat [OPTION]… [FILE]…
常见选项
-E #显示行结束符$
-A #显示所有控制符。Tab:^I;0d:^M;0a:$
-n #每一行编号
-b #非空行编号
-s #压缩连续的空行成一行
nl 显示行号
tac 行倒序显示
rev 同一行倒序显示
hexdump
查看非文本文件内容
-C #十六进制和ASCII显示
-s N #跳过前N个字节
-n length #规定输入长度
二、分页查看文件内容
常用来查看日志
more
more [OPTIONS…] FILE…
- 常用选项
-d #在底部显示提示
-s #压缩连续空行
- 命令选项
h #显示帮助
= #显示行号
:f #显示文件名和当前行号
回车键 #下一行
空格键 #翻页
!CMD #执行命令
less
less [OPTIONS…] FILE…
- 常用选项
-N #显示行号
-s #压缩连续空行
-e
-S
- 命令选项
:h #帮助
/string #搜索
b #向上翻
:!CMD #执行命令
三、显示文本前面或后面的内容
head 显示文件或标准输入的前面行
head [OPTION]… [FILE]…
常用选项
-n N | --lines=N #N为正数或纯数字:前N行;N为负数:[文件头,N-1]
-N #前N行
-c N | --bytes=N #前N个字节
-q | --quiet | --silent #不输出文件名
-v | --verbose #输出文件名
-z | --zero-terminated
tail 查看文件或标准输入的倒数行
tail [OPTION]… [FILE]…
常用选项
-n N | --lines=N #N为负数或纯数字:后N行;N为正数:[N,文件尾]
-N #后N行
-c N | --bytes=N #后N个字节
-f | --follow=descriptor #跟踪变化,常用于日志监控
-F
-q | --quiet | --silent #不输出文件名
-z
四、cut 按列抽取文本
cut OPTION… [FILE]…
常用选项
-d STRING #指定分割符。默认:Tab
-f #要显示的列。-f1、-f1,2,3、-f 2-4,5
--output-delimiter=STRING #输出时用指定字符代替分割符
-b
-c
-s
-z
五、paste 合并多个文件同行号的行到一行
paste OPTION… [FILE]…
常用选项
-d STRING #指定分割符。默认为TAB
-s #将一个文件合成一行显示
-z
seq 100 | paste -s -d'+' | bc #求和1到100
六、wc 收集文本统计数据
wc OPTION… [FILE]…
默认统计行数、单词总数、字节总数
-l #统计行数
-w #统计单词数
-c #统计字节数
-m #统计字符总数
-L #显示文件中最长行的长度
七、sort 文本排序
sort OPTION… [FILE]…
默认以行为单位,从行首至行尾按ASCII升序排序
-t STRING #指定分割符
-k N #指定排行列
-n #按数字大小升序排序
-r #降序。倒序
-b #忽略文件中的空白
-u #去重
-f
-h
-M
-R
-z
八、uniq 去重
uniq [OPTION]… [INPUT [OUTPUT]]
从输入中删除前后相连的重复的行。常和sort配合使用
-c #显示每行出现的次数
-d #仅显示有重复的行
-u #仅显示不重复的行
-D
-z
九、比较文件
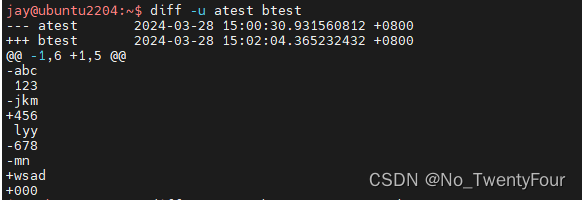
diff
diff [OPTION]… FILES
-u #规定输出的文件格式
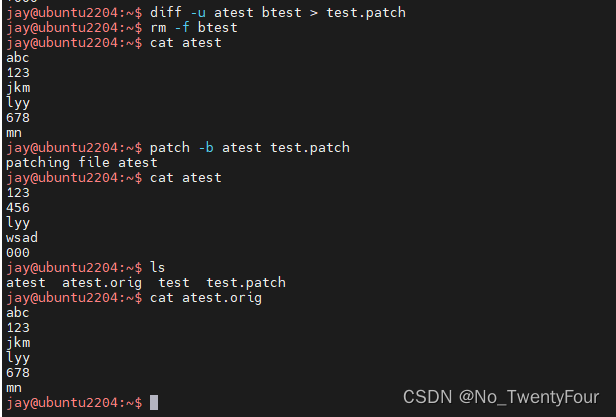
patch
patch [OPTION]… [ORIGFILE [PATCHFILE]]
-b #备份
vimdiff 比较两个文件的不同
相当于 vim -d
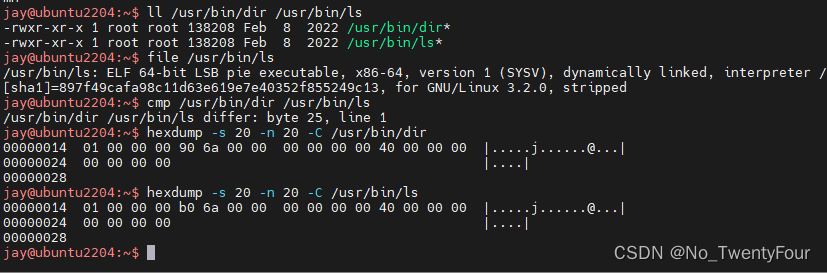
cmp 查看二进制文件的不同
十、正则表达式 Regular Expressions
分类:
基本正则表达式 BRE Basic Regular Expressions
扩展正则表达式 ERE Extended Regular Expressions
基本正则表达式元字符
- 字符匹配
. #任意单个字符(除\n),可以是一个汉字或其他单个文字
[] #任意括号中的单个字符。[.]:一个.
[^] #任意不是括号中的单个字符
[:lower:] #单个小写字母。写法:[[:lower:]]
[:upper:] #单个大写字母
[:alpha:] #单个大小写字母
[:alnum:] #单个大小写字母或数字
[:digit:] #单个十进制数字
[:xdigit:] #单个十六进制数字
[:blank:] #单个空白字符(空格和制表符)
[:space:] #比[:blank:]范围广。空格、制表符(水平和垂直)、换行符、回车符等
[:cntrl:] #单个不可打印的控制字符(退格、删除、警铃...)
[:graph:] #单个可打印的非空白字符
[:print:] #单个可打印字符
[:punct:] #单个标点符号
\s
\S
\w
\W
- 匹配次数
* #前面一个字符>=0次。贪婪模式,尽可能长的匹配
.* #任意长度的任意字符
\? #可有可无:前面一个字符0次或1次
\+ #前面一个字符>=1次
\{n\} #前面一个字符n次
\{m,n\} #前面一个字符次数[m,n]
\{,n\} #前面一个字符次数[0,n]
\{m,\} #前面一个字符次数[m,无穷]
- 位置锚定
^ #行首
$ #行尾
^$ #空行
^[[:space:]]*$ #空白行
\< | \b #词首
\> | \b #词尾
\<PATTERN\> #单词:字母、数字、下划线
- 分组
(1)后向引用
\1:第一个括号的内容
\2:第二个括号的内容
...
(2)| 或
a\|b #a或b
12a\|b #12a或b
12a\|12b #12a或12b
12\(a\|b\) #12a或12b
扩展正则表达式元字符
1. 字符匹配(同)
2. 匹配次数
?
+
{}
3. 位置锚定(同)
\<\>
4. 分组
()
|
十一、文本处理三剑客
grep:配合正则表达式基于行过滤文本
sed:Stream EDitor。文本编辑工具
awk:Linux上实现gawk。文本报告生成器
grep Global search REgular expression and Print out the line
grep [OPTIONS…] PATTERN [FILE…]
-F #不支持正则表达式,等价于fgrep
-E #使用ERE,等价于egrep
-e #逻辑“或”。-e PAT1 -e PAT2
-m N #取匹配的前N行
-v #取反,取不匹配的行
-i #忽略字符大小写
-n #显示行号
-c #只显示匹配的行数
-o #仅显示匹配到的内容
-q #静默模式,不打印内容。若匹配成功,$?==0;反之,$?==1
-A N #显示匹配到的行及后N行
-B N #显示匹配到的行及前N行
-C N #显示匹配到的行及前后N行
-f file #从文件中读取匹配规则
-r #递归匹配,不处理链接
-R #递归匹配,处理链接
-l FILES #仅显示匹配到的文件的文件名
-H FILES #还要显示内容来自的文件
-c #统计匹配成功的行的数量
-w #匹配整个单词。-w root == '\<root\>'
sed Stream EDitor
-
工作原理
sed是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到最后一行。
每当处理一行时,把当前处理的行存储在临时缓冲区 模式空间(PatternSpace) 中,接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。
vim将文件全加载到内存中,不适合改大文件
-
sed 用法
sed [OPTION]… {script-only-if-no-other-script} [input-file]…
sed '' #script为空。等待标准输入,默认直接输出
sed '' file #默认输出file内容
(1)常用选项
-n #不输出模式空间内容至屏幕,即关闭自动打印
-e #多个script,或的关系。-e script1 -e script2
-E | -r #使用ERE
-i #修改文件。-i.bak备份
(2)script格式:地址 + 命令
AddrCmd #地址+命令。在哪些行,执行什么操作
AddrCmd;AddrCmd;... #多个脚本写在一起,用';'隔开
a)地址
#为空,则对全文处理
N #第N行
$ #最后一行
/PATTERN/ #匹配到PATTERN的每一行
M,N #第M行至第N行
M,+N #第M行至第M+N行
/pat1/,/pat2/
M,/pat/
/pat/,N
1~2 #步长。1、1+2、1+2+2、...奇数行
2~2 #偶数行
b)命令
p #打印当前模式空间内容,追加到默认输出之后
= #为模式空间中的行打印行号
a [\]text #在指定行后追加文本。可用\n实现多行追加。加\,则其后面的内容(包括空白符)都会追加!!
i [\]text #在指定行前追加文本。可用\n实现多行追加。不加\,则从非空字符开始追加!!
c [\]text #替换指定行为text。可用\n实现一行换多行;也可实现多行换一行
d #删除模式空间中匹配的行,并立即开始下一次循环
! #模式空间中匹配地址取反:不满足匹配地址的行执行命令
命令----搜索替换
s/pattern/replace/修饰符 #分割符可换:s///、s@@@、s###
#修饰符
g #行内全局替换
p #显示替换成功的行
w file #将替换成功的行存至file中
i | I #忽略大小写
#后向引用
\1 #第一个分组
\2 #第二个分组
...
& #所有搜索内容
注意:用sed取命令中的某些可变量时,将其(),用后向引用输出
取IP地址:

取分区利用率:

- sed高级用法(4.2.3)
tips
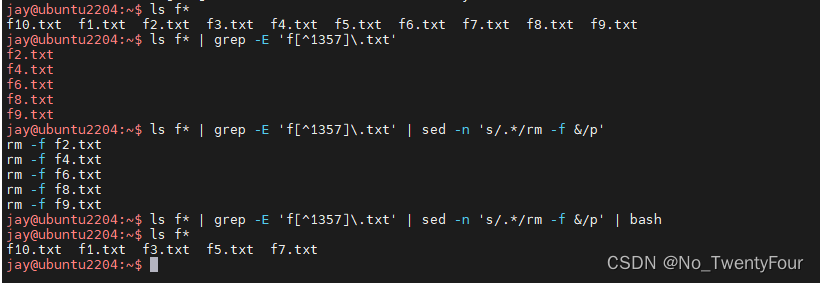
非交互式删除文件















 671
671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









