






上回我们讲到boost以及GBDT,这次我们来讲Adaboost的原理
我们之所以要进行集成学习是因为单个模型的预测效果可能不好,要想达到强分类器的效果我们就需要结合多个弱分类器。
先看一个例子在讲原理。

更具两个相邻的x的中值来选取阈值,如0.5,1.5,2.5。同时对每一个阈值要计算出准确率,也就是有多少正类,多少负类。初始化所有的权重都为0.1。 比如我们选取0.5为当前阈值。那么正类全对,负类错了5个(序号:2.3.7.8.9),误差率就是0.5.,然后我们挨个比较下面的1.5,2.5,3.5…最后得到阈值为2.5 的时候当前误差率最小–>是0.3.
然后求得如下公式,具体每个符号代表什么最后再讲 [1]:
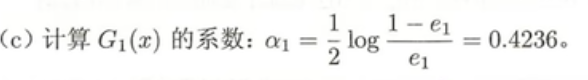
然后下一步我们就需要更新模型D1变成---->D2包括里面的w1-10都要被更新。
第二批的数据分布(w)使用此公式. [2]:
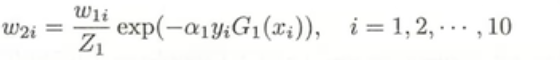
通过计算我们可以发现序号,7,8,9三个点是预测错误的点,所以他们的权值被增大**[3]**:
然后我们使用新的D2来寻找新的阈值,开始新的一轮。三轮过后我们得到三个系数,相加得到我们最后的强分类器:

下面讲一下具体原理:
首先了解一个定义:

[1] 当前模型的系数
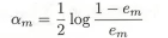
e(m)为当前的误差率,如上面例子中的0.3
[2]第二批数据分布w(i)
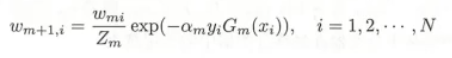
这里使用指数损失函数。
我们需要将原有数据分为,分类正确的(减少权重),分类错误的(增加权重)
对于分类正确的Zm=:
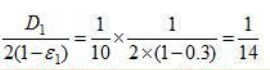
分类错误的Zm=:
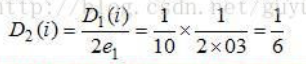
这样就得到了我们的下一批次的分布 [3]
这样我们这题的3轮下来最后得到最终的强分类器:
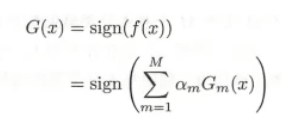
Renfernce
https://zhuanlan.zhihu.com/p/41536315















 309
309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









