







AdaBoost 算法介绍
AdaBoost算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来修改每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次得到的分类器最后融合起来,作为最后的决策分类器。
AdaBoost算法
训练数据集

-
初始化训练数据的权值分布
-
-
对M=1,2,…,m
使用具有权值分布Dm的训练数据集学习,得到基本分类器:
计算Gm(x)在训练数据集上的分类误差率:
更新训练数据集的权值分布:
-
-
Zm是规范化因子:
-
-
计算Gm(x)的系数
-
-
构建基本分类器的线性组合
-
-


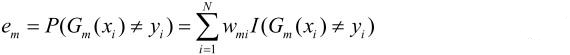
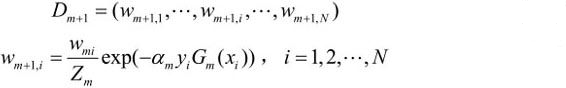
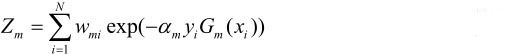


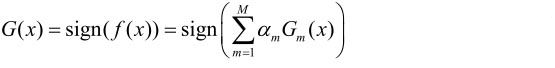
AdaBoost说明:
-
假设训练数据集具有均匀的权值分布,即每个训练样本在基本分类器的学习中作用相同,
这一假设保证第1步能够在原始数据上学习基本分类器G1(x)
- AdaBoost反复学习基本分类器,在每一轮m=1,2,…,M顺次地执行下列操作:
1.使用当前分布Dm加权的训练数据集,学习基本分类器Gm(x)。
2.计算基本分类器Gm(x)在加权训练数据集上的分类误差率:
这里,wmi表示第m轮中第i个实例的权值.
这表明,Gm(x)在加权的训练数据集上的分类误差率是被Gm(x)误分类样本的权值之和,
由此可以看出数据权值分布Dm与基本分类器Gm(x)的分类误差率的关系
3. 计算基本分类器Gm(x)的系数am。am表示Gm(x)在最终分类器中的重要性。
当em≤1/2时,am≥0,并且am随着em的减小而增大,
所以分类误差率越小的基本分类器在最终分类器中的作用越大。
4.更新训练数据的权值分布为下一轮作准备

被基本分类器Gm(x)误分类样本的权值得以扩大,而被正确分类样本的权值却得以缩小
误分类样本在下一轮学习中起更大的作用。
不改变所给的训练数据,而不断改变训练数据权值的分布,使得训练数据在基本分类器的学习中起不同的作用
- 线性组合f(x)实现M个基本分类器的加权表决。
?
AdaBoost的例子
弱分类器由x<v或x>v产生, 其阈值v使该分类器在训练数据集上分类误差率最低.

初始化数据权值分布

对于m=1
在权值分布为D1的训练数据上,阈值v取2.5时分类误差率最低,故基本分类器为

G1(x)在训练数据集上的误差率e1=P(G1(xi)≠yi)=0.3。
计算G1(x)的系数:

更新训练数据的权值分布:

分类器sign[f1(x)]在训练数据集上有3个误分类点。
对于m= 2
在权值分布为D2的训练数据上,阈值v是8.5时分类误差率最低,基本分类器为

G2(x)在训练数据集上的误差率e2=0.2143
计算a2=0.6496
更新训练数据权值分布:

分类器sign[f2(x)]在训练数据集上有3个误分类点。
对于m = 3:
在权值分布为D3的训练数据上,阈值v是5.5时分类误差率最低,基本分类器为

计算a3=0.7514
更新训练数据的权值分布
D4=(0.125,0.125,0.125,0.102,0.102,0.102,0.065,0.065,0.065,0.125)
得到:
















 5321
5321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









