







deepseek入门指南

导读
大家好,很高兴又和大家见面啦!!!
2025年伊始,DeepSeek 在全球AI业界引发广泛关注,它以2048张H800 GPU,仅用两个月就训练出了一个媲美全球顶尖水平的模型,打破了大模型军备竞赛的既定逻辑。
DeepSeek 这款AI大语言模型,想必大家现在或多或少的都已经开始接触了,我也相信有很多大佬已经开始玩转 DeepSeek 了。
但是,我同样相信有很多朋友与我一样,之前就没怎么接触过AI软件,是一个纯新手小白。那我们应该如何入门 DeepSeek 呢?
为了帮助用户全面了解和使用 DeepSeek ,清华大学新闻与传播学院新媒体研究中心元宇宙文化实验室的余梦珑博士后团队推出一套学习指南——《 DeepSeek 从入门到精通2025》。
《DeepSeek从入门到精通2025》有104页,内容涵盖DeepSeek的核心技术、应用场景、提示词优化等,还介绍了如何避免AI幻觉、如何精准设计提示语等实战经验。
这份报告为用户提供了全面了解和使用 DeepSeek 的指南,有助于推动 DeepSeek 在各个领域的应用和普及。多家公司宣布将 DeepSeek 集成到自己的产品中,如中国移动的移动云全面上线 DeepSeek ,联通云基于“星罗”平台实现多规格 DeepSeek-R1 模型适配,浙文互联将 DeepSeek-R1 作为智慧内容生态平台的核心决策模型等。
我刚好获取到了这个份学习指南的PDF版,有需要的朋友可以在我CSDN的账号——【蒙奇D索大】中进行获取,并且该资源会与CSDN发布的博文进行绑定,需要的朋友可以自行下载。
在今天的内容中,我会借助这份指南与大家一起学习如何使用DeepSeek,下面我们就将开始今天的内容!!!
一、什么是 DeepSeek?
Deepseek 即深度求索,既是一家人工智能公司,也是其一系列人工智能产品的名称。
DeepSeek是由杭州深度求索人工智能基础技术研究有限公司开发。该公司由量化对冲基金幻方量化支持创立,于2023年7月17日在杭州市拱墅区市场监督管理局登记成立。核心团队由人工智能等领域专业人士组成,在学术和产业方面均有深厚积累。
该公司从成立以来,发布了多款语言模型:
-
DeepSeek Coder:2023年11月2日发布。由一系列代码语言模型组成,在2万亿token上训练,代码占87%,有1B-33B版本。支持项目级代码补全和填充,在多种编程语言和基准测试中达开源代码模型先进性能。
-
DeepSeek LLM:2024年1月5日发布。包含670亿参数,在2万亿token数据集上训练,涵盖中英文。具备出色的推理、编码、数学和中文理解能力,在匈牙利国家高中考试中取得65分成绩,中文表现超越GPT-3.5。
-
DeepSeek Math:2024年2月5日发布。以DeepSeek-Coder-v1.5 7B为基础,在5000亿token数学相关数据等上预训练。在竞赛级MATH基准测试中取得51.7%的成绩,接近Gemini-Ultra和GPT-4性能水平。
-
DeepSeek-VL:2024年3月11日发布。开源视觉-语言模型,采用混合视觉编码器,能处理高分辨率图像,在广泛视觉-语言基准测试中性能先进或有竞争力。
-
DeepSeek-V2:2024年5月7日发布。拥有2360亿参数,中文综合能力在众多开源模型中最强,英文综合能力与LLaMA3-70B处于同一梯队,训练效率高。
-
DeepSeek-Coder-V2:2024年6月17日发布。开源混合专家代码语言模型,从DeepSeek-V2中间检查点开始,进一步预训练6万亿token,编码和数学推理能力增强,支持338种编程语言,上下文长度扩展到128K。
-
DeepSeek-V2.5:2024年9月5日发布。由DeepSeek Coder V2和DeepSeek V2 Chat合并升级,与GPT-4-Turbo等闭源模型在评测中处于同一梯队,英文综合能力与LLaMA3-70B同一梯队,在写作任务、指令跟随等多方面进行了优化。
-
DeepSeek-VL2:2024年12月13日发布。大型混合专家视觉-语言模型,在视觉问答、光学字符识别等多种任务中能力卓越,有DeepSeek-VL2-Tiny、-Small和无后缀三个变体。
-
DeepSeek-V3:2024年12月26日发布。6710亿参数的混合专家模型,激活参数370亿,在14.8万亿token上预训练。多项评测成绩超越Qwen2.5-72B和Llama-3.1-405B等开源模型,知识类任务能力显著提升。
-
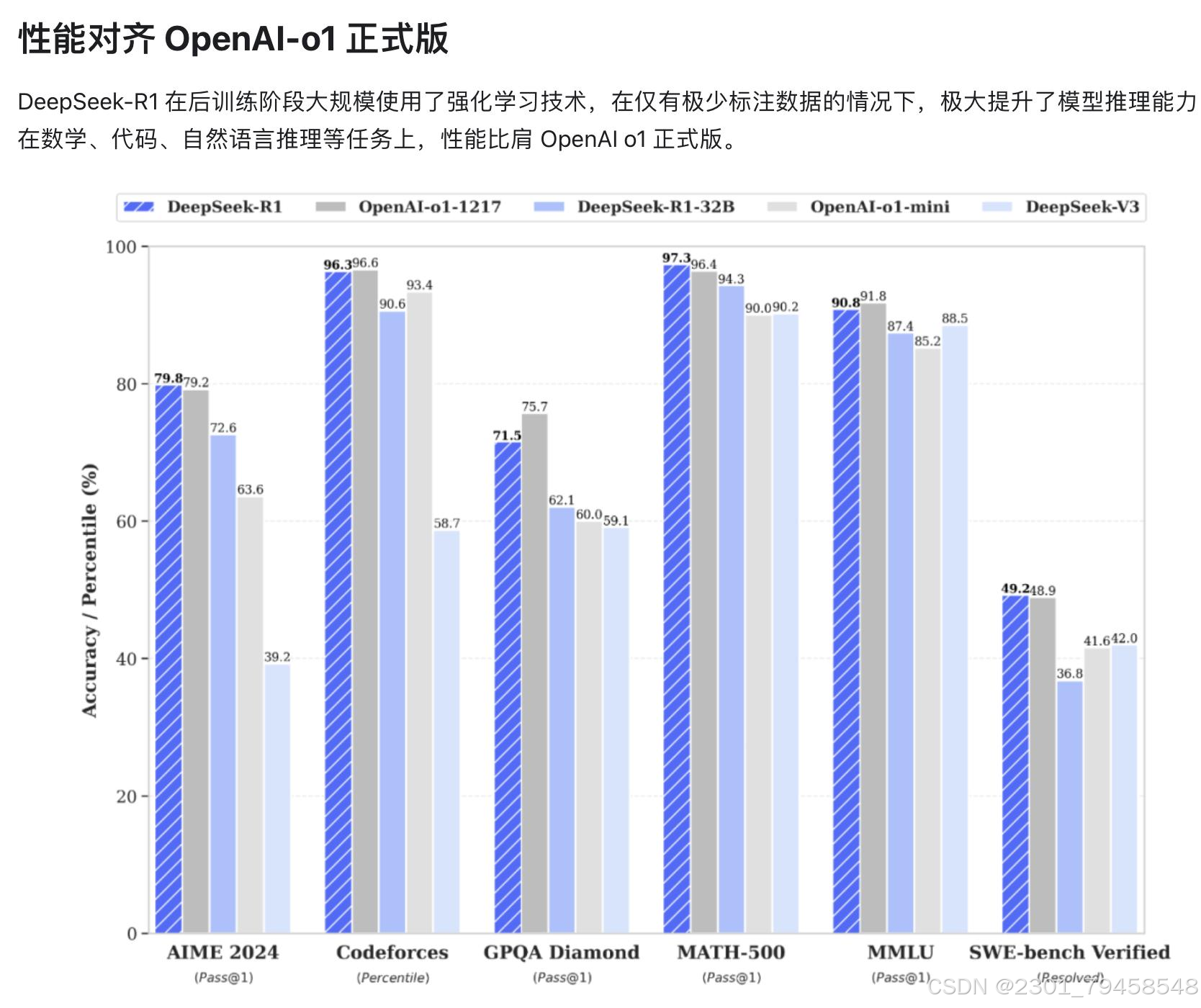
DeepSeek-R1:2025年1月20日发布。在数学、代码、自然语言推理等任务上性能比肩OpenAI o1正式版,通过大规模强化学习和冷启动技术,专注于推理和多模态任务。
-
Janus-Pro:2025年1月发布。多模态大模型,进军文生图领域。
现在我们已经知道了什么是 DeepSeek 了,那现在问题来了,我们要学习的 DeepSeek 究竟是指的该公司旗下的哪一款产品呢?
这里我就不卖关子了,我们现在要学习入门的是DeepSeek-R1,这款在性能上比肩OpenAI o1的大语言模型。
二、什么是DeepSeek-R1?
DeepSeek-R1 是幻方量化旗下大模型公司DeepSeek研发的首代开源推理大型语言模型。
发布时间:
- 2024年11月20日,DeepSeek-R1-Lite预览版上线网页端。
- 2025年1月20日,DeepSeek正式发布 DeepSeek-R1 模型,并同步开源模型权重。
模型架构:
- 采用深度Transformer架构,以DeepSeek-V3-Base模型为基础,通过使用V3的数十亿参数的密集Transformer Base子模型进行初始化,并利用自研的“群组相对策略优化”(GRPO)算法进行强化学习训练。
训练方法:
训练流程采取多阶段逐步增强策略,包括冷启动监督微调、第一阶段强化学习、拒绝采样与二次监督微调、第二阶段强化学习。
主要功能:
使用强化学习训练,推理过程包含大量反思和验证,思维链长度可达数万字。在数学、代码以及各种复杂逻辑推理任务上,取得了媲美OpenAI o1-preview的推理效果,为用户展现了o1没有公开的完整思考过程。
三、DeepSeek-R1 能够做什么?
R1 直接面向用户或者支持开发者,提供智能对话、文本生成、语义理解、计算推理、代码生成补全等应用场景;
支持联网搜索与深度思考模式,同时支持文件上传,能够扫描读取各类文件及图片中的文字内容。
以文本生成为例,我们可以通过下面的这个UML图来进行展示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 580
580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









