






目录
引言
目标检测一直是计算机视觉领域中的一个重要方向之一。自从2013年,R-CNN算法第一次使用深度学习技术来进行目标检测开始,目标检测方向的发展便开始进入到一个加速期。
随着人们对检测速度要求的不断提高,以R-CNN为代表的two-stage检测方式逐渐显得力不从心。以Redmon为首的人们便提出了一种one-stage检测方式,这便是YOLO(You Only Look Once)系列算法的第一代。到目前为止,YOLO系列算法仍然是目标检测方向最重要的算法之一。
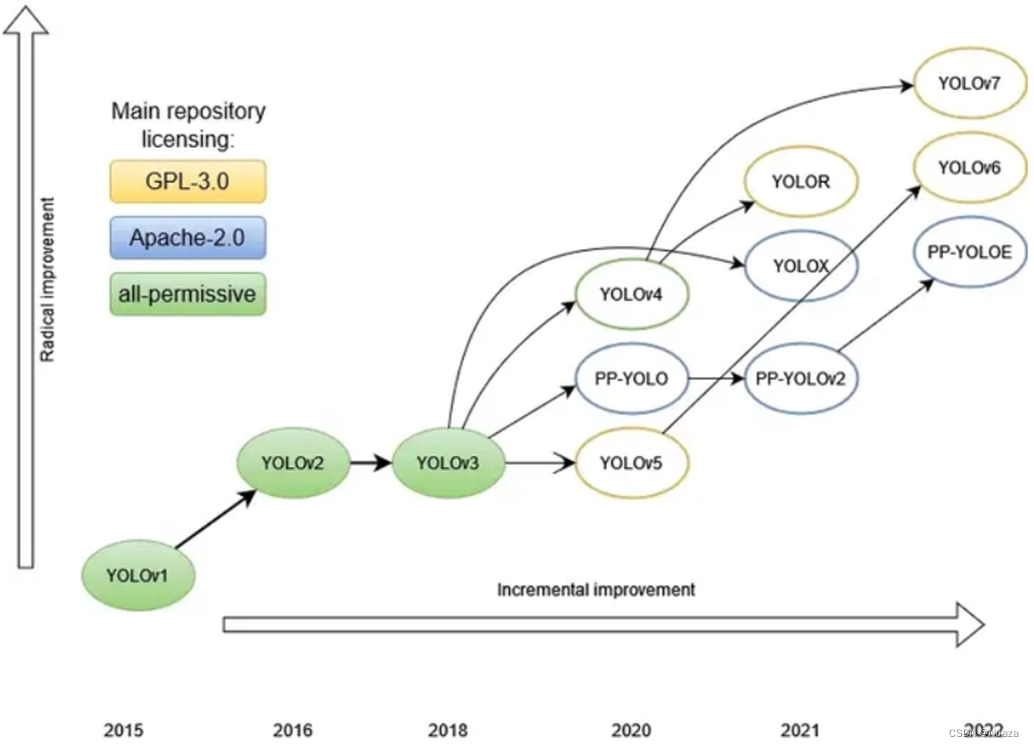
骨干网络
YOLO: GoogLeNet
准确来说,初代YOLO算法采用的其实是一种基于GoogLeNet修改而成的网络结构。GoogLeNet是由谷歌公司的Christian等人,于2014年提出的一种用于图像分类的网络结构,并获得了当时举办的ILSVRC14(ImageNet Large-Scale Visual Recognition Challenge 2014)的冠军。
在关于GoogLeNet的论文《Going deeper with convolutions》中指出,以往的网络结构都是通过增大网络结构的深度和宽度来提高其性能,但这也可能会导致网络因参数过多而出现过拟合现象。基于这种考虑,GoogLeNet提出了一种叫做Inception的模块,如下图所示。这种模块采用了多分支结构以及大量的1x1卷积,即能够达到对数据进行降维从而减少计算量的作用,也有助于网络提取到更多的特征,在确保网络规模不变的前提下提高了网络内部计算资源的利用率。

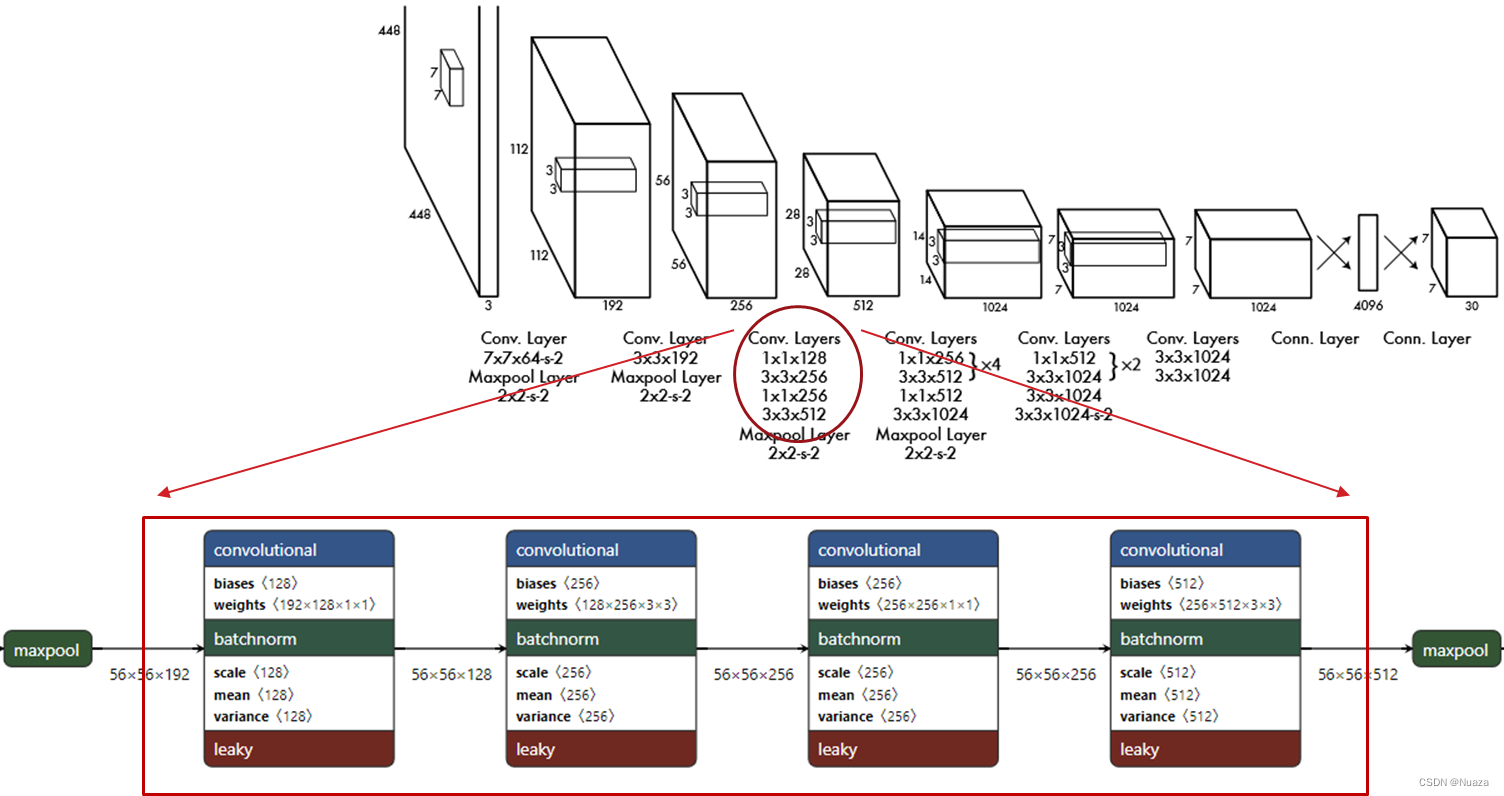
初代YOLO算法的网络结构受到GoogLeNet的启发,其内部包含有24个卷积层和2个全连接层。但与GoogLeNet采用的Inception模块不同的是,YOLO的网络结构仅仅简单使用了1x1的卷积层与3x3的卷积层串联起来,如下图所示。这样不仅进一步缩小了网络规模,使得YOLO拥有很快的检测速度,而且也能够拥有与GoogLeNet的Inception模块相近的特征提取效率和计算资源利用率。
YOLOv2(YOLO9000): DarkNet-19
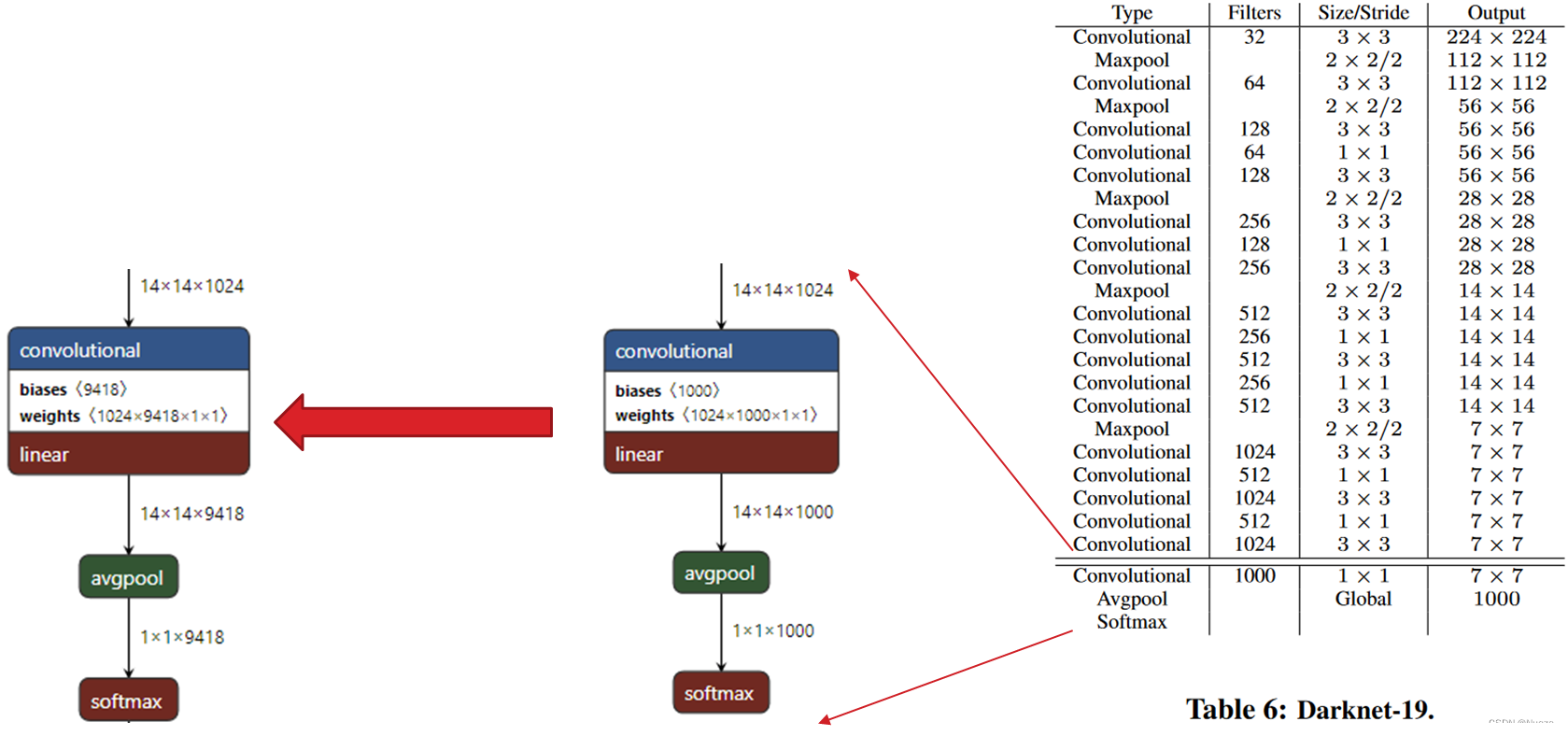
初代YOLO算法虽然其检测速度的确很快,但检测效果仍然欠佳。针对这些问题,YOLO的原作者Redmon对其进行了一系列大刀阔斧的改造,其中就包括将YOLO的骨干网络更换成其自研的DarkNet-19,作者将这种改进后的算法称为YOLOv2。然后,作者将YOLOv2在ImageNet数据集的9000多个类以及COCO数据集上进行联合训练,便得到了YOLO9000。
DarkNet-19包含有19个卷积层和5个最大池化层,如右图所示。该图为训练图像分类且只训练1000个类时所使用的网络结构。若需要训练YOLO9000,则只需要将最后一个卷积层替换成filters为9418的1x1卷积即可,如下所示。
在DarkNet-19中,作者也第一次引入了批量归一化层(即Batch Norm层),如右图所示。在每一个卷积层中都包含由一个线性卷积层,一个BN层和一个激活函数层。BN层可以使每一层输入的数据,都分布在一个均值为0,方差为1的情况下,使其满足正态分布。这样不仅能显著改善网络的收敛性,也能够使网络在不发生过拟合的情况下去除掉模型中的dropout,使得模型的结构更加规范化。
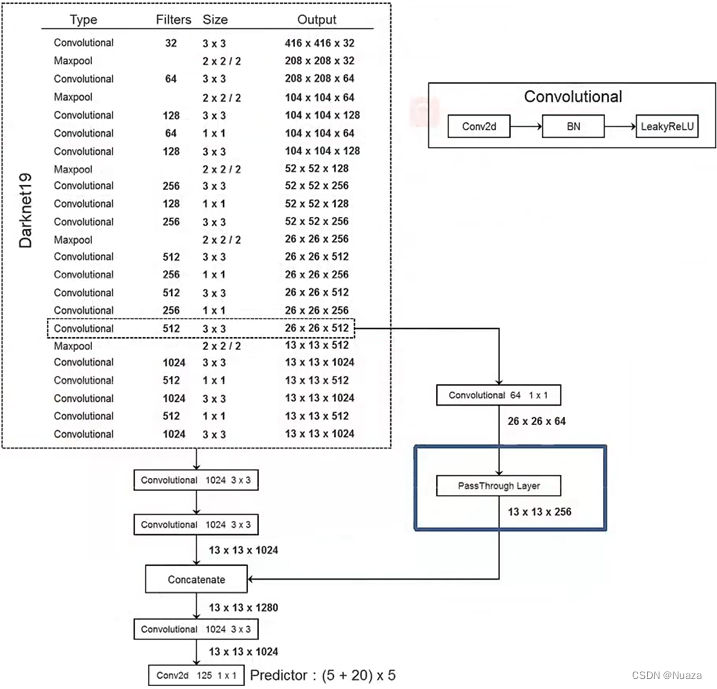
另外,作者在DarkNet-19中还引入了一种叫做“Pass Through”的结构。如下图所示。在DarkNet-19网络中的26 x 26分辨率下简单的增加了一个直通层,与网络的输出进行融合。这种类似于残差网络中的identity结构,能够使网络获得更高分辨率的特征图,增加了特征的多样性,使得模型的检测性能得到了提升。
YOLOv3/YOLOX : DarkNet-53
在YOLOv2发布两年之后,原作者Redmon在v2版本的基础上进行了一些增量式的更新,其中就包括了一个新的骨干网络:DarkNet-53。与当时最为先进的骨干网络ResNet-152相较而言,DarkNet-53在检测精度相差不大的前提之下,其检测速度和每秒运算次数都远在ResNet-152之上。
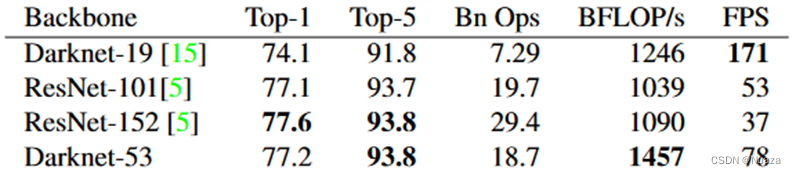
DarkNet-53的结构如下图所示,其包含有53个卷积层和一个平均池化层。DarkNet-53借鉴了ResNet里的残差结构,如下图所示,数据在通过一个1x1卷积层和一个3x3卷积层之后,与其进入到1x1卷积层之前的数据进行拼接相加,这样构成了一个残差块。同时,相较于上一代DarkNet-19,DarkNet-53还去除掉了最大池化层,转而直接使用卷积层完成下采样。在加上其只包含53个卷积层,比ResNet-152包含的152个卷积层数量也要少很多,这样便使得其能够获得比ResNet-152更好的性能。
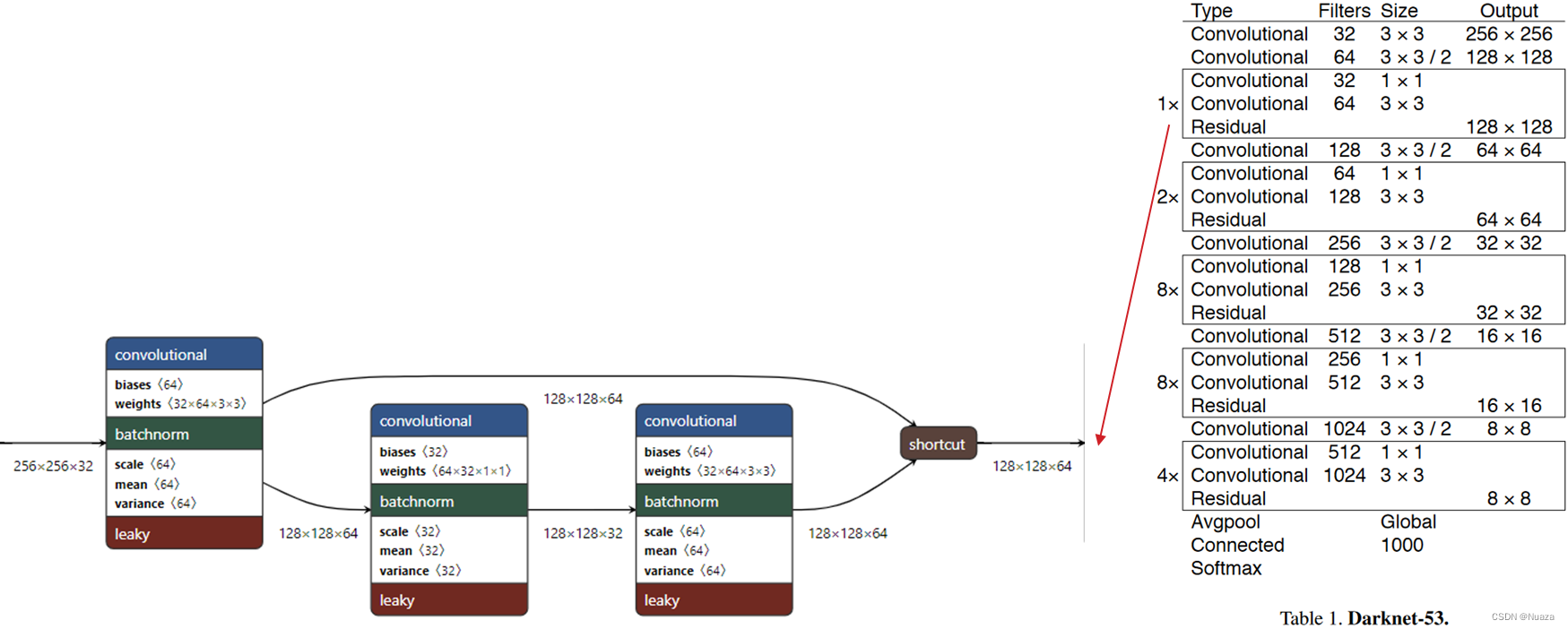
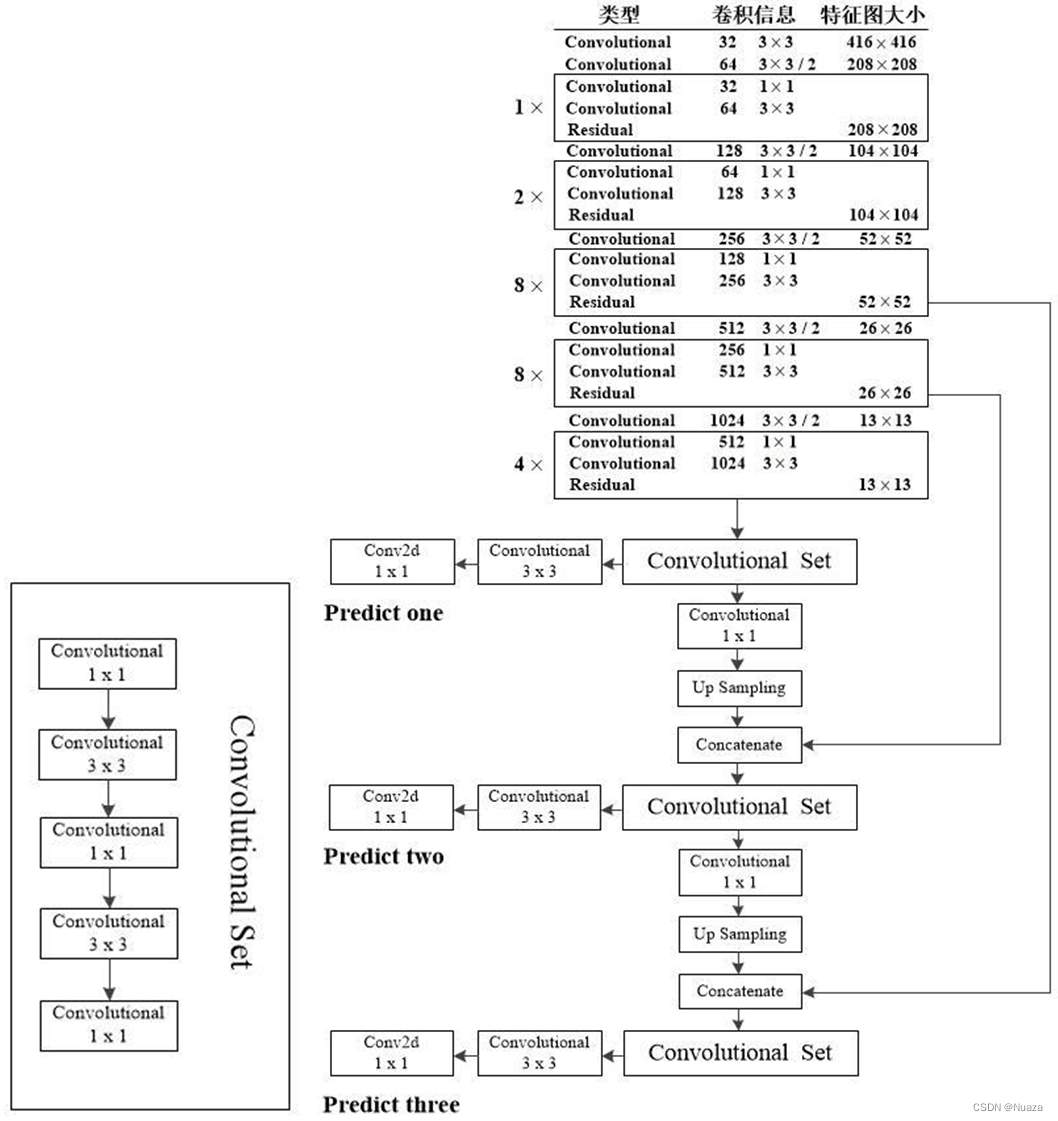
另外,在上一代DarkNet-19的“Pass Through”结构的基础之上,DarkNet-53还结合了FPN(Feature Pyramid Network)的思想,分别从网络中的52x52分辨率和26x26分辨率下的卷积层中直接取出特征图,与网络后面的输出进行拼接。这样便能够让YOLOv3同时预测出三个不同尺度的特征,对于Predict one,其特征图尺寸为13x13,适合预测尺度相对较大的目标;对于Predict two,其特征图尺寸为26x26,适合预测尺度中等的目标;对于Predict three,其特征图尺寸为52x52,细粒度最高,适合预测尺度相对较小的目标。
通过引入了残差模块和类似于特征金字塔网络的特征提取模块这些较为先进的功能,使得YOLOv3的检测性能和检测速度都得到了很大的提升。如下图所示,在COCO数据集上的mAP-50相等即纵坐标相同的情况下,YOLOv3的推理速度要明显快过RetinaNet-50和RetinaNet-101。
在YOLO的前三代作者Redmon发布完YOLOv3之后不久便退出了计算机视觉领域,之后的YOLO版本便开始由第三方作者制作,版本更迭也开始变得较为混乱。但是其骨干网络大致仍然是延续着基于DarkNet或者其改进的网络而设计的。在YOLOv3发布三年后的YOLOX中,作者Zheng Ge仍然使用的是YOLOv3的DarkNet-53作为其骨干网络,而其主要的改进点在于网络头部以及数据增强等方面。

YOLOv4/YOLOv5/YOLOv8: CSPDarkNet-53
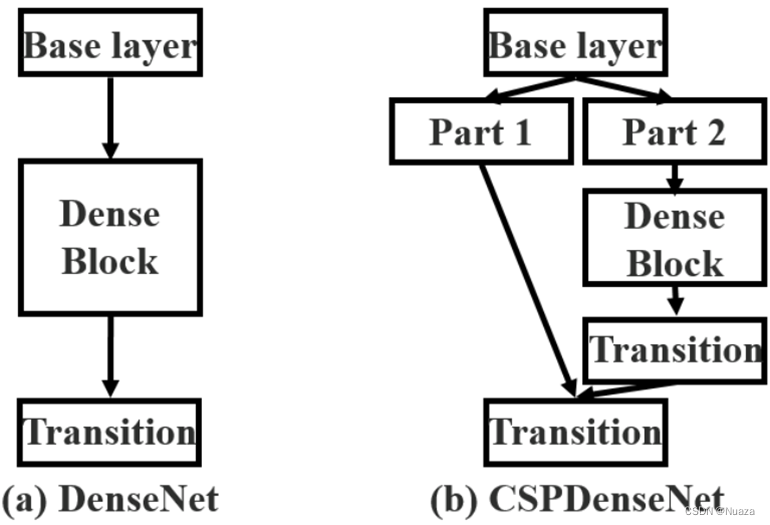
在YOLOv3发布一年之后,由Wang Chien-Yao等人提出了一个名为CSPNet(Cross Stage Partial Net)的网络,旨在降低网络整体的运算消耗量,从而可以使更多的人能够不受硬件条件限制地搭建更为先进的网络结构。以DenseNet为例,CSPNet的网络结构如下图所示。
在他们所著的论文《CSPNet: A New Backbone that can Enhance Learning Capability of CNN》中,这种CSPNet结构能够带来一下三点好处:
-
增加梯度路径:通过这种拆分与合并的策略,使得网络整体的梯度路径数量可以翻倍,使得网络的学习能力得到增强,并在轻量化的同时保证准确性。同时也能够避免直接对特征图的拷贝进行拼接所带来的一些弊端。
-
平衡各层之间的运算量:在一些网络内部存在通道数量与增长率不匹配的问题,导致产生计算瓶颈。而通过这种跨阶段式的设计,可以有效提高计算单元的利用率,从而减少不必要的运算损耗。
-
降低内存成本:在特征金字塔生成的过程中采用这种跨阶段式的方式来压缩特征映射,可以减少内存使用率。
另外,作者还提出,CSPNet可以很方便地移植到ResNet等网络中,并且与未使用CSPNet的情况相较而言,理论上能够在浮点运算相等的情况下减少内存开销。
由于CSPNet能够在不损失太多的检测精度的同时显著减少网络的开销,并且其能够移植到DarkNet-53所采用的残差结构的网络中。因此,在CSPNet发布后的第二年里,采用了CSPNet结构的YOLOv4和YOLOv5便相继问世。YOLOv4和YOLOv5其实是两个不同团队所研发出来的,但他们都同时采用了基于CSPNet和DarkNet-53相融合的骨干网络,即CSPDarkNet-53。
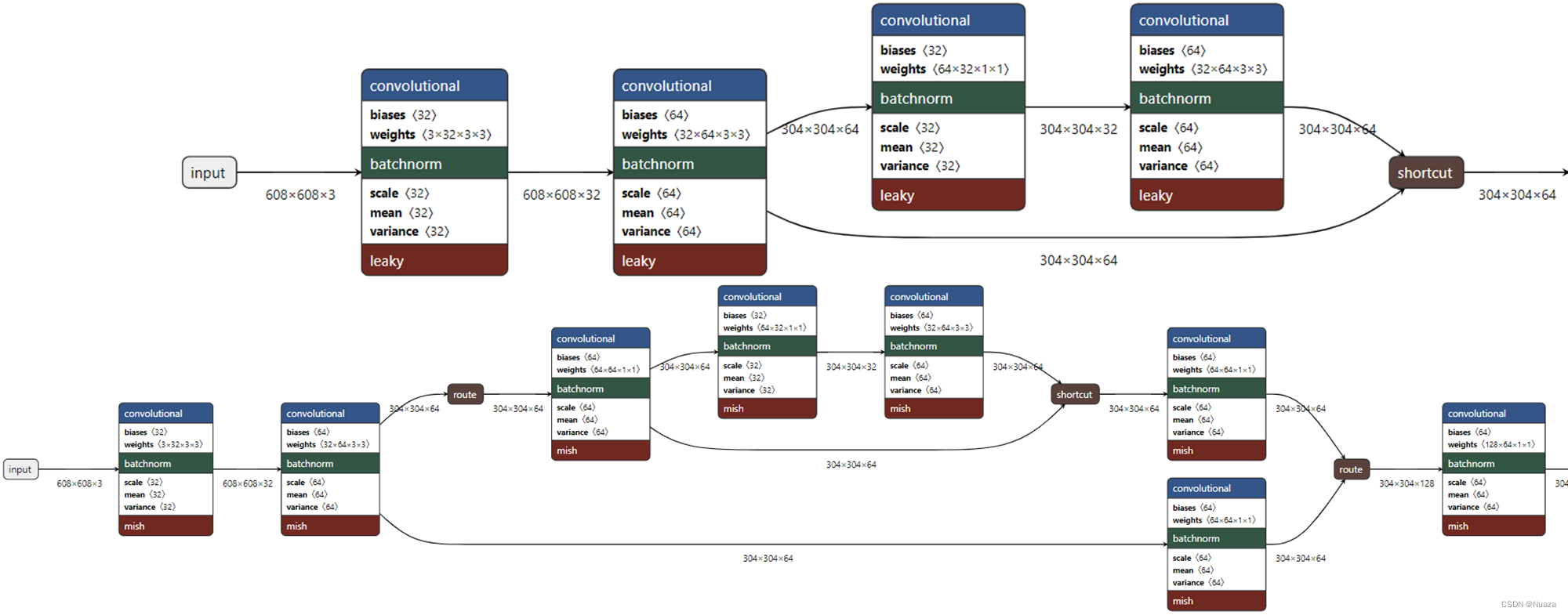
CSPDarkNet-53的整体结构与DarkNet-53是相同的,其不同的地方在于:
- 每一个残差层都包含两个部分,一个部分直接走partial transition通道接往Transition层,另一部分则进入残差块进行运算后再接往Transition层,由Transition层拼接整合后再通往下一个残差层。
- YOLOv4的CSPDarkNet-53采用Mish激活函数来替代原来的Leaky ReLU激活函数(YOLOv5的CSPDarkNet-53仍然采用原来的Leaky ReLU激活函数)。
- YOLOv5的CSPDarkNet-53在最初的版本中,在网络输入的第一层增加了Focus层,不过在之后的版本更新中被一个6x6的卷积给替代了。如下图所示。
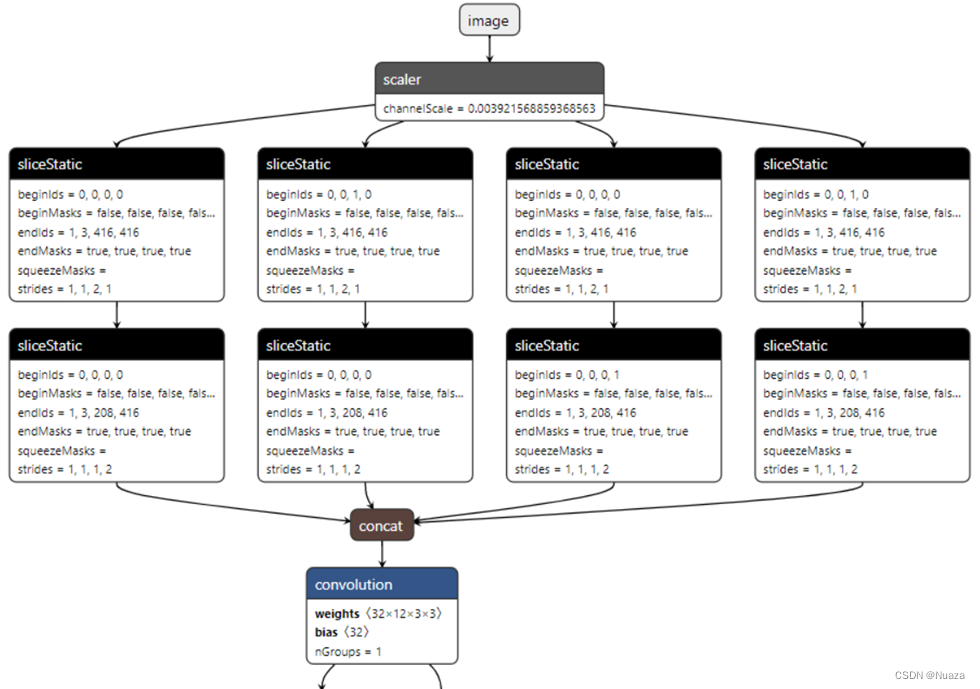
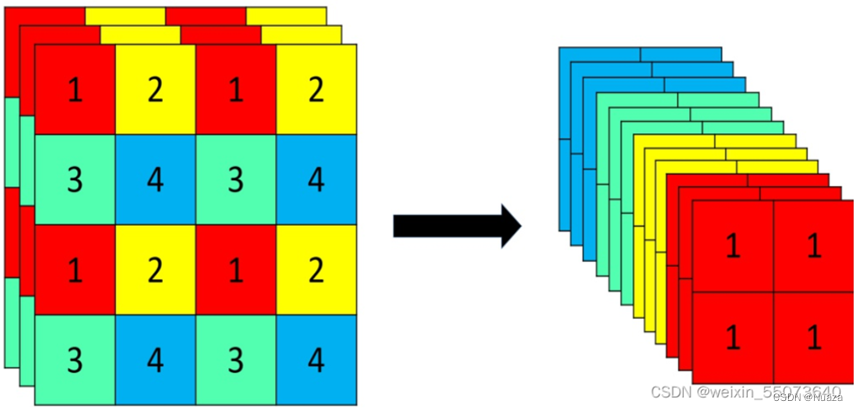
Focus层使用切片操作,将高分辨率的图片拆分成多个低分辨率的图片,如下图所示。这种操作可以减少下采样所带来的信息损失。
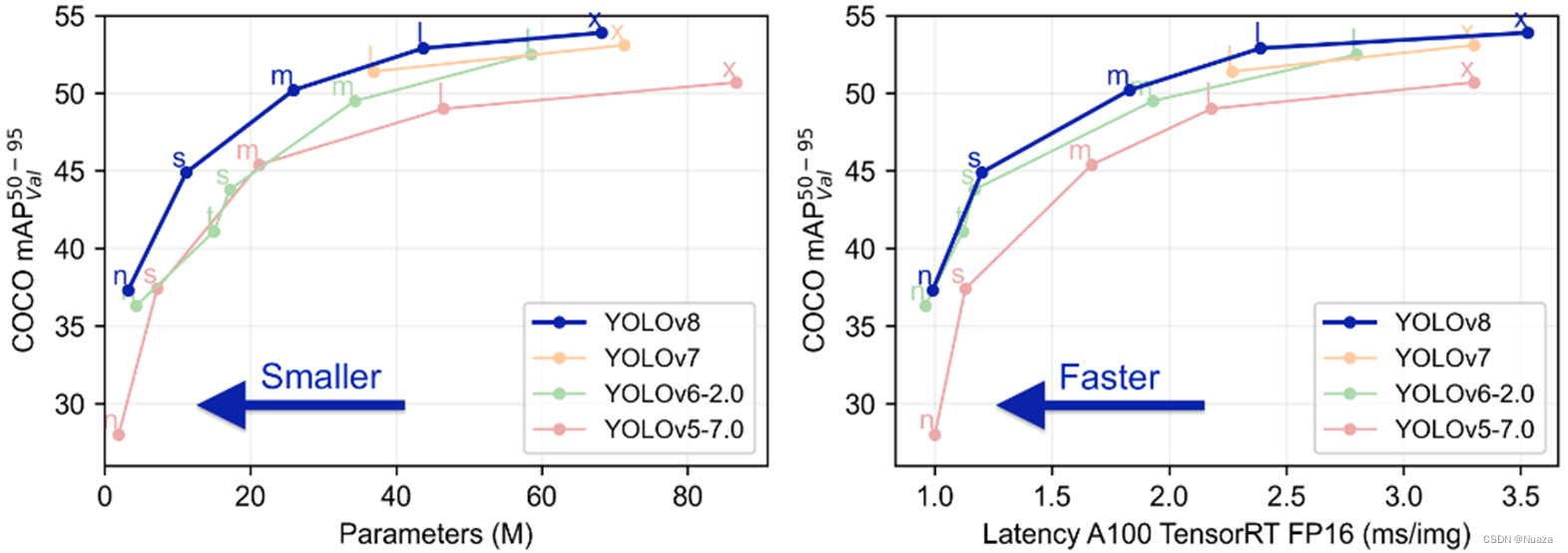
YOLOv4与YOLOv5都是基于YOLOv3的改进版本,这两者的发布间隔很短,可以认为这两个团队是各自同时使用DarkNet-53与CSPNet进行结合改造。两者的CSPDarkNet-53各有细微的差别,但整体设计思路是基本相同的,性能也相差不大。研发YOLOv4的Alexey团队在几个月后发布了Scaled-YOLOv4,将研究重点转向了对不同性能的设备所设计不同的网络结构缩放,并在2022年发布了基于E-ELAN骨干网络的YOLOv7。而研发YOLOv5的ultralytics公司则继续基于CSPDarkNet-53骨干网络,在2023年1月发布了YOLOv8。
YOLOv6: EfficientRep
在介绍YOLOv6和YOLOv7的骨干网络之前,有必要先介绍两个叫做VGG和RepVGG的网络结构。在2015年,来自牛津大学的Visual Geometry 团队发表了一篇名为《Very Deep Convolutional Networks for Large-Scale Image Recognition》的论文,在其中提出了VGG网络。VGG基于AlexNet,但提出使用大量的3x3卷积层,并辅以少量1x1卷积层来扩展网络的深度,以获得更高的检测精确度,VGG的结构如下图所示。在上文所述的ILSVRC14比赛中,VGG仅次于GoogLeNet,获得了亚军。
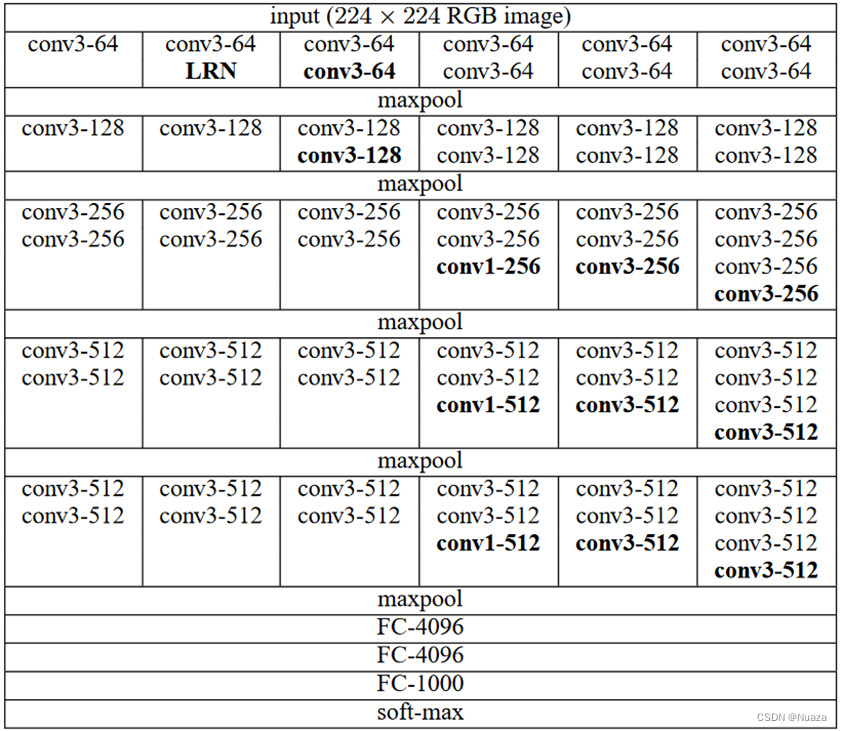
VGG首次提出了使用大量的3x3卷积来替换当时流行的一些较大卷积(5x5、7x7、9x9甚至11x11)。这是因为作者发现,在对网络的深度进行扩展时,更大的卷积层会带来相当大的计算量增长,但其对检测性能的提升却极其有限。这一思想影响了后面的大多数网络结构设计,现如今许多流行的网络结构也大都是采用的3x3或1x1卷积,极少有使用更大卷积的网络。
不过VGG的弊端也很明显,虽然作者在网络的所有层中仅使用了非常小的(3x3和1x1)卷积,但参数量仍然巨大;且由于当时的主流网络结构都是单一的线性结构,没有类似于残差之类的多分支结构,其性能水平的上限也十分有限。
在VGG问世后,随着残差结构,CSP,FPN等多分支结构的提出,网络结构也越加复杂。但在2021年,一篇名为《RepVGG: Making VGG-style ConvNets Great Again》的论文提出,它们将使用一种最新的被称为结构重参化(structural re-parameterization technique)的技术,让类似于VGG的网络在训练时采用多分支的拓扑结构,而在推理检测时将其等价转换成传统的单线性结构。如下图所示。这样便可以使得网络同时拥有多分支模型在训练时的优势(性能高)以及单线性模型在推理检测时的好处(速度快,内存开销小)。

重参化给RepVGG的性能带来了巨大的提升。在这篇论文里,作者称其在ImageNet数据集上的top-1准确率能够达到80%以上,这是首个能达到这种水平的基础模型。
RepVGG成功将重参化的思想引入了网络结构设计之中,而这也是YOLOv6和YOLOv7骨干网络设计的重要思想之一。
YOLOv6原名MT-YOLOv6,是由国内的美团视觉智能部研发的一款目标检测框架。在YOLOv6中,作者发现像RepVGG这种运用了重参化的骨干网络设计在小型网络中确实有效。但随着网络规模的扩张,这种单线性结构的网络的计算量和参数数量会呈指数增长。对此,作者自创了一个名为EfficientRep的骨干网络,其主要思想便是在小型网络中引入RepVGG的基本结构(RepVGG Block),而对于中型和大型的网络,则引入CSP来优化网络结构,作者将其命名为CSPStackRep Block。下图(a)与(b)所示为小型网络中使用的RepVGG结构,当模型进行训练任务时为(a)这种高效的多分支结构,当模型进行推理任务时切换为(b)这种快速而节省开销的单线性结构。图©为中型和大型模型所使用的CSPStackRep Block结构,其大体结构与CSPDarkNet-53相似,不过内部的残差块替换成了可进行重参化的RepVGG块。
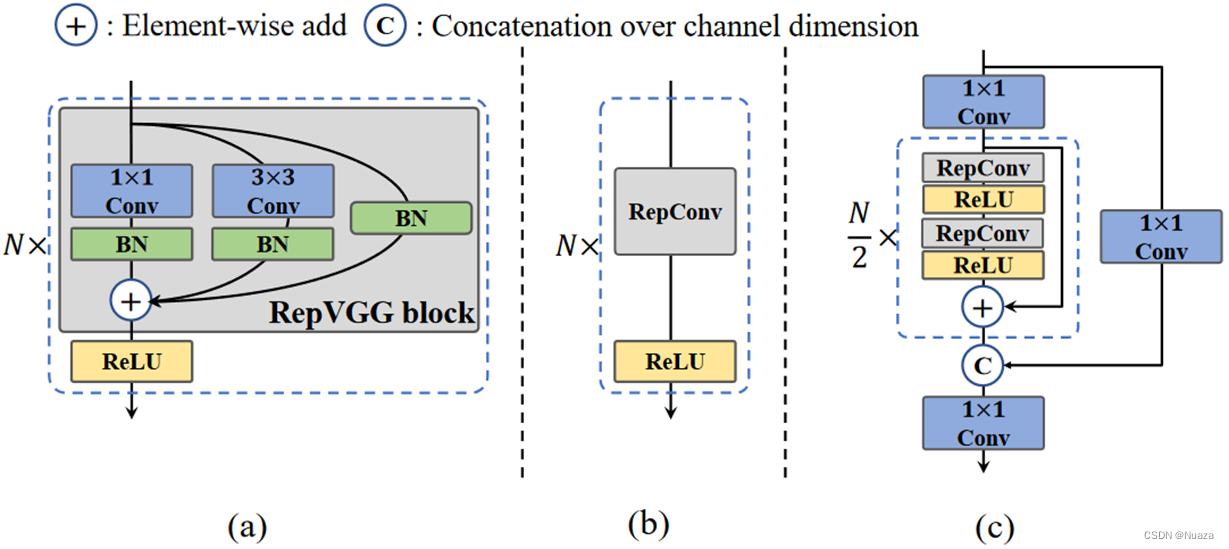
EfficientRep骨干网络是在RepVGG的基础之上,根据网络规模的大小设计了不同的网络结构,这使得YOLOv6能够在任何规模大小的情况下都能获得优于其它模型的检测性能和检测速度。
YOLOv7: E-ELAN
YOLOv7由曾经设计过YOLOv4的Alexey,和设计过CSPNet的Wang Chien-Yao等人研发而成。在Wang Chien-Yao的另一篇文章《 Designing Network Design Strategies Through Gradient Path Analysis 》,他们发现,当整个网络模型扩展到一定深度以后,如果继续堆叠计算块,则精度的增益会越来越少;在网络深度超过某个临界值以后甚至会导致其性能比浅层网络还要差。以ResNet和VoVNet,当ResNet堆叠了超过200层以后,其检测精度就不如ResNet-152;同样,当VoVNet堆叠了99层以后,其检测精度就会比VoVNet-39还差。从网络梯度路径设计的角度出发,作者推断这里VoVNet的精度退化比ResNet快得多的原因便是VoVNet的OSA模块的堆叠。每个OSA模块都包含一个transition层,这导致网络每堆叠一个OSA模块,整个网络中所有层的最短梯度路径就会加一。而残差块的堆叠只会导致最长梯度路径的增加,不会影响最短梯度路径。基于此,作者便设计了一个避免使用过多的transition层,并且能让网络在扩展时能保证最短梯度路径迅速变长的网络ELAN。如下图所示。
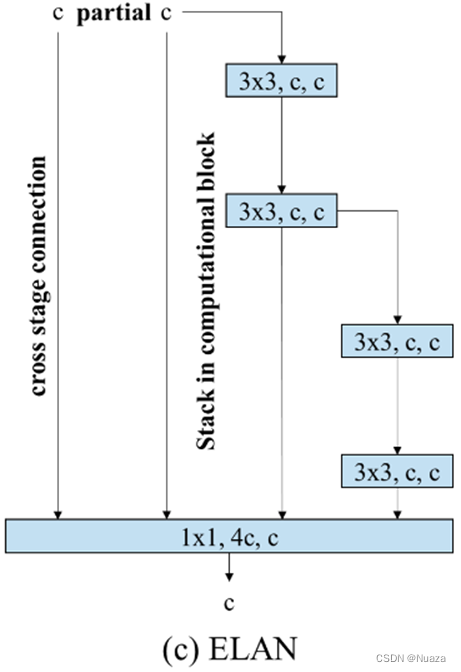
在规模较大的ELAN中,无论梯度路径长度和计算块的堆叠数量如何,它都能够达到一个较为稳定的状态。但是,如果无限制地堆叠更多的计算块时,这种稳定状态很有可能会被破坏,从而导致参数的利用率下降。基于此,作者在YOLOv7的论文中正式提出了E-ELAN骨干网络,如下图所示。 E-ELAN对基数(cardinality)使用了扩展、乱序分配以及合并操作, 其并没有改变ELAN的梯度传输结构,而是利用分组卷积增加了特征的基数,将不同分组的特征进行随机组合和基数合并。这种方式可以增强网络从不同特征图学习特征的能力,从而提高参数和计算资源的使用率,以弥补可能产生的利用率下降的问题。

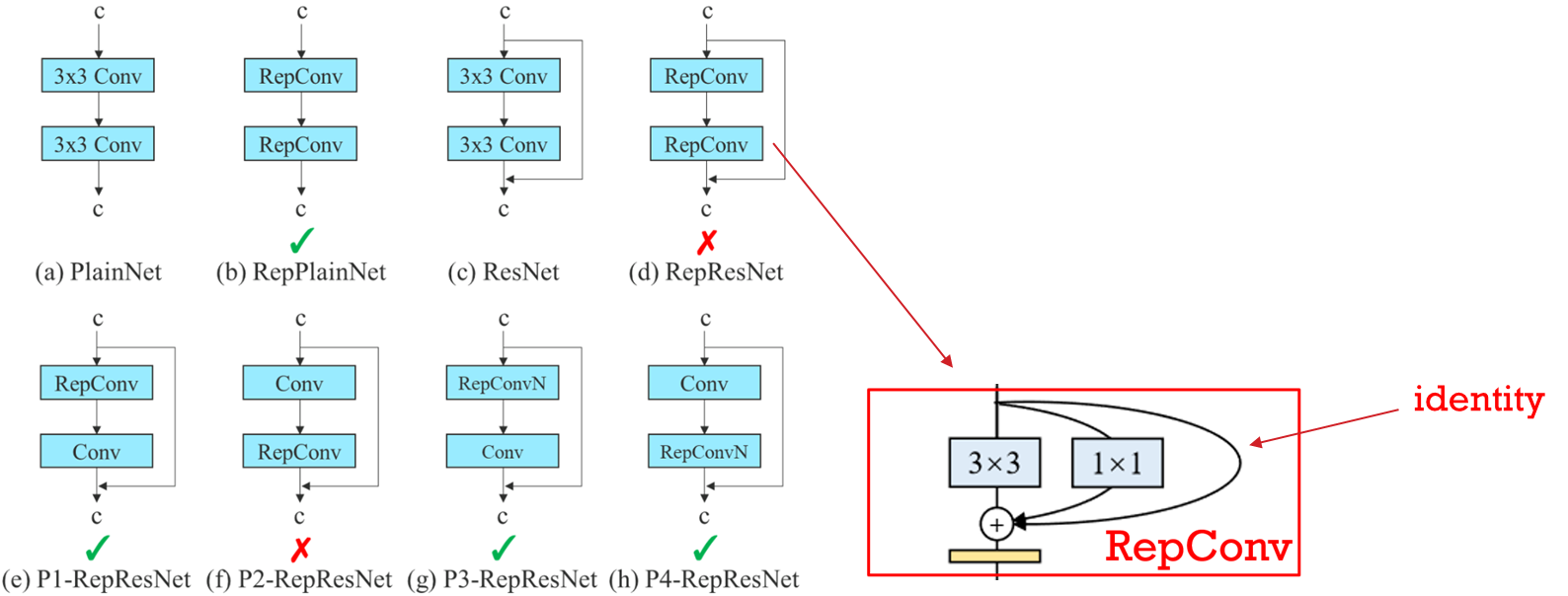
除此之外,作者也将重参化的思想引入了YOLOv7中,但他发现若直接将RepConv运用到残差网络之类的结构中时,其检测准确度反而会下降。通过分析,作者发现是因为RepConv中的identity连接破坏了ResNet原本的残差结构。如下图所示,对于单线性的网络结构,直接引入RepConv不会有什么问题,而对于诸如ResNet之类的多分支网络结构,若将网络分支拼接处的上一层卷积替换成RepConv就会导致多分支结构被破坏,从而导致精准度的下降。基于此,作者提出了一种规划的重参化卷积(Planned re-parameterized convolution),即设计了一种去掉了identity连接的重参化卷积层,称为RepConvN。如下图(g)和(h)所示,通过在E-ELAN中引入了这种卷积,使得网络模型能够在保持灵活性的同时,也能够享受到重参化模块给模型的训练和推理带来的各种优势。
总结
YOLO系列最早使用的是经Redmon修改后的GoogLeNet,但他也在基于这个骨干网络,并结合当时最新的诸如残差结构这类的多分支结构的特性,自研了DarkNet系列骨干网络,而这也是YOLO最主要的几个版本所使用的网络。在Redmon大佬退出计算机视觉领域之后,随着神经网络往多分支结构发展,其性能也在不断增强,但同时网络的参数量也开始变得越来越庞大。而CSPNet的出现便缓解了这一现象,并使人们开始注重从优化网络结构的角度出发,增强网络性能,而不是单纯地增加网络深度的角度。以Alexey为首的团队在正式接过YOLO系列后,便融合了DarkNet与CSPNet,研发出了YOLO系列最重要的骨干网络CSPDarkNet。同时也是从这一代开始,Alexey正式提出了将YOLO的骨干网络、头部和颈部分别看待,并设计了不同的训练策略、插件模块和后处理方法等,让后来者可以不用再修改骨干网络的整体架构,而只需要更改头部或颈部的模块或训练方法等就能提升网络性能。基于此,YOLOv6和YOLOv7对骨干网络的修改也已经不再是对网络整体结构的修改了,而是结合了能同时提升网络训练速度和检测精度的重参化思想,设计了不同的策略和模块。YOLOv6从网络规模出发,设计了小型网络和中大型网络使用不同的结构的策略。YOLOv7则从网络内部的卷积层入手,设计了可以在残差网络结构中正常运用重参化的卷积块。
参考文献
[1] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. arXiv preprint arXiv:1409.4842, 2014.
[2] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
[3] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 779788, 2016.
[4] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
[5] Joseph Redmon and Ali Farhadi. YOLO9000: better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 7263-7271, 2017.
[6] Joseph Redmon and Ali Farhadi. YOLOv3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018.
[7] Alexey Bochkovskiy, Chien-Yao Wang, and HongYuan Mark Liao. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934, 2020.
[8] Chien-Yao Wang, Hong-Yuan Mark Liao, Yueh-Hua Wu, Ping-Yang Chen, Jun-Wei Hsieh, and I-Hau Yeh. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 390–391, 2020.
[9] Xiaohan Ding, Xiangyu Zhang, Ningning Ma, Jungong Han, Guiguang Ding, and Jian Sun. RepVGG: Making VGG-style ConvNets Great Again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13733–13742, 2021.
[10] Chuyi Li, Lulu Li, Hongliang Jiang, Kaiheng Weng, Yifei Geng, Liang Li, Zaidan Ke, Qingyuan Li, Meng Cheng, Weiqiang Nie, Yiduo Li, Bo Zhang, Yufei Liang, Linyuan Zhou, Xiaoming Xu, Xiangxiang Chu, Xiaoming Wei, and Xiaolin Wei. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv preprint arXiv:2209.02976, 2022.
[11] Chien-Yao Wang, Alexey Bochkovskiy, and HongYuan Mark Liao. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv preprint arXiv:2207.02696, 2022.
[12] Chien-Yao Wang, Hong-Yuan Mark Liao, and I-Hau Yeh. Designing Network Design Strategies Through Gradient Path Analysis. arXiv preprint arXiv:2211.04800, 2022.
后记
这是我研一时一次组会的PPT内容,现在转成markdown文章放到CSDN上。
本人水平有限,若有有误之处欢迎批评指正。
禁止未经许可随意转载。
















 8747
8747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











