






 本文介绍了如何利用TensorFlow框架和Docker环境,通过转移学习对图像进行单标签分类。特别是,文章详细阐述了如何启动TensorFlow,设置工作目录,下载和准备数据,以及训练Inception v3模型。训练过程包括生成瓶颈文件、训练网络的最后一层,并在训练结束后使用再训练模型进行图像测试。
本文介绍了如何利用TensorFlow框架和Docker环境,通过转移学习对图像进行单标签分类。特别是,文章详细阐述了如何启动TensorFlow,设置工作目录,下载和准备数据,以及训练Inception v3模型。训练过程包括生成瓶颈文件、训练网络的最后一层,并在训练结束后使用再训练模型进行图像测试。
本文叙述了如何在tensorflow框架下,与docker容器一起对图像进行训练,实现单标签分类。通过这篇文章,您将学习如何在单个机器上安装和运行TensorFlow,并将训练一个简单的分类器来分类花卉图像。
在这个实验中,我们将使用转移学习,这意味着我们从已经培养了另一个问题的模型为开始。然后,我们将再次训练类似的问题。从头开始深入学习可能需要几天的时间,但可以在短时间内完成转移学习。
我们将使用Inception v3网络。初始v3使用2012年的数据对ImageNet大型视觉识别挑战进行了培训,它可以区分1000种不同的类,如Dalmatian or dishwasher。我们将使用这个相同的网络,但是根据我们自己的例子来重新编写一些少量的类。
关于实现过程可以详细参见:https://codelabs.developers.google.com/codelabs/tensorflow-for-poets/#1
一.启动tensorflow
首先启动docker;
测试docker是否安装:
docker run hello-world对应的输出应该为:
Hello from Docker!
This message shows that your installation appears to be working correctly.
如果出现:
docker:cannot connect to the Docker daemon at Unix:///var/run/docker.sock. Is the docker daemon running?表示你并没有安装docker,你需要下载并安装docker。
然后测试tensroflow是否存在:
docker run -it tensorflow/tensorflow:1.1.0 bash如果没有安装tensorflow,这条命令会自动帮你下载和安装tensorflow:1.1.0
二.建立工作目录
下面我们将在docker中建立工作目录,现在主机下建立工作目录tf_files
mkdir tf_files建立好工作目录之后,需要将主机目录下的工作目录与docker中的目录进行共享,以及为tensorboard发布端口号6006:
docker run -it \
--publish 6006:6006 \
--volume ${HOME}/tf_files:/tf_files \
--workdir /tf_files \
tensorflow/tensorflow:1.1.0 bash
此时,你的工作路径应该变为:
root@xxxxxxxxx:/tf_files#其中xxxxxxxx为你的docker名称,
你也可以在主机环境下(非docker环境)使用命令行来观测你docker的名称及编号以及其他粗略情况
docker ps -a如果你不小心退出了docker环境,你可以使用如下命令进入docker:
docker start xxxxxxx
docker attach xxxxxxx
其中xxxxxx为你docker的名称或编号。
三.下载图片
首先我们需要下载图片,下面的命令行为下载图片并进行解压
curl -O http://download.tensorflow.org/example_images/flower_photos.tgz
tar xzf flower_photos.tgz
若你下载到的图片位于主机中,你还需要将这个图像文件复制到docker容器中,命令行为:
docker cp /tf_files/flower_photos.tgz xxxxxx:/tf_files其中第一个/tf_files/flowe_photos.tgz为主机下的flower_phtots的路径,而第二个xxxxxx:/tf_files为复制在docker中的路径,其中xxxxx为docker的名称或编号。
你可以使用下面命令来观察图片内容:
ls flower_photos这个文件夹中包含了5个标签的花的类型,并且每个标签各含有650张左右的图片,你可以使用如下命令对图片进行缩减,这样你就会减少训练集,从而可以快点看到训练结果:
ls flower_photos/roses | wc -l
rm flower_photos/*/[3-9]*
ls flower_photos/roses | wc -l
四.训练Inception
重新训练脚本是张量回流的一部分,但它不作为pip包的一部分安装。所以你需要手动下载到当前目录:
curl -O https://raw.githubusercontent.com/tensorflow/tensorflow/r1.1/tensorflow/examples/image_retraining/retrain.py现在有了训练数据以及训练器,我们可以开始训练v3网络了:Inception是一个巨大的图像分类模型,具有数百万个可以区分大量图像的参数。我们只是训练该网络的最后一层,所以培训将在合理的时间内结束。
开始训练之前确保tensorboard对训练过程进行监控:
tensorboard --logdir training_summaries &如果你出现了以下结果:
ERROR:tensorflow:TensorBoard attempted to bind to port 6006, but it was already in use这说明你的tensorbaord正在使用,你可以使用如下命令将其关掉:
pkill -f "tensorboard"现在开始你的图像再训练(注意--summaries dir选项,将训练进度报告发送到张量板正在监视的目录):
python retrain.py \
--bottleneck_dir=bottlenecks \
--how_many_training_steps=500 \
--model_dir=inception \
--summaries_dir=training_summaries/basic \
--output_graph=retrained_graph.pb \
--output_labels=retrained_labels.txt \
--image_dir=flower_photos
其中参数how_many_training_steps=500,是使迭代次数为500以方便快速观察训练结果,如果不加上这行,那么将会使用默认的迭代次数4000进行训练。
在训练时我们可以先来看下如下要素:
bottleneck

Inception v3模型由堆叠在一起的许多层组成,TensorBoard的简化图像如上所示。 这些层是预先训练的,并且在查找和总结有助于对大多数图像进行分类的信息方面已经非常有价值。 对于这个codelab,你只训练最后一层(下图中的final_training_ops)。 虽然以前的所有层都保留了已经训练好的状态。
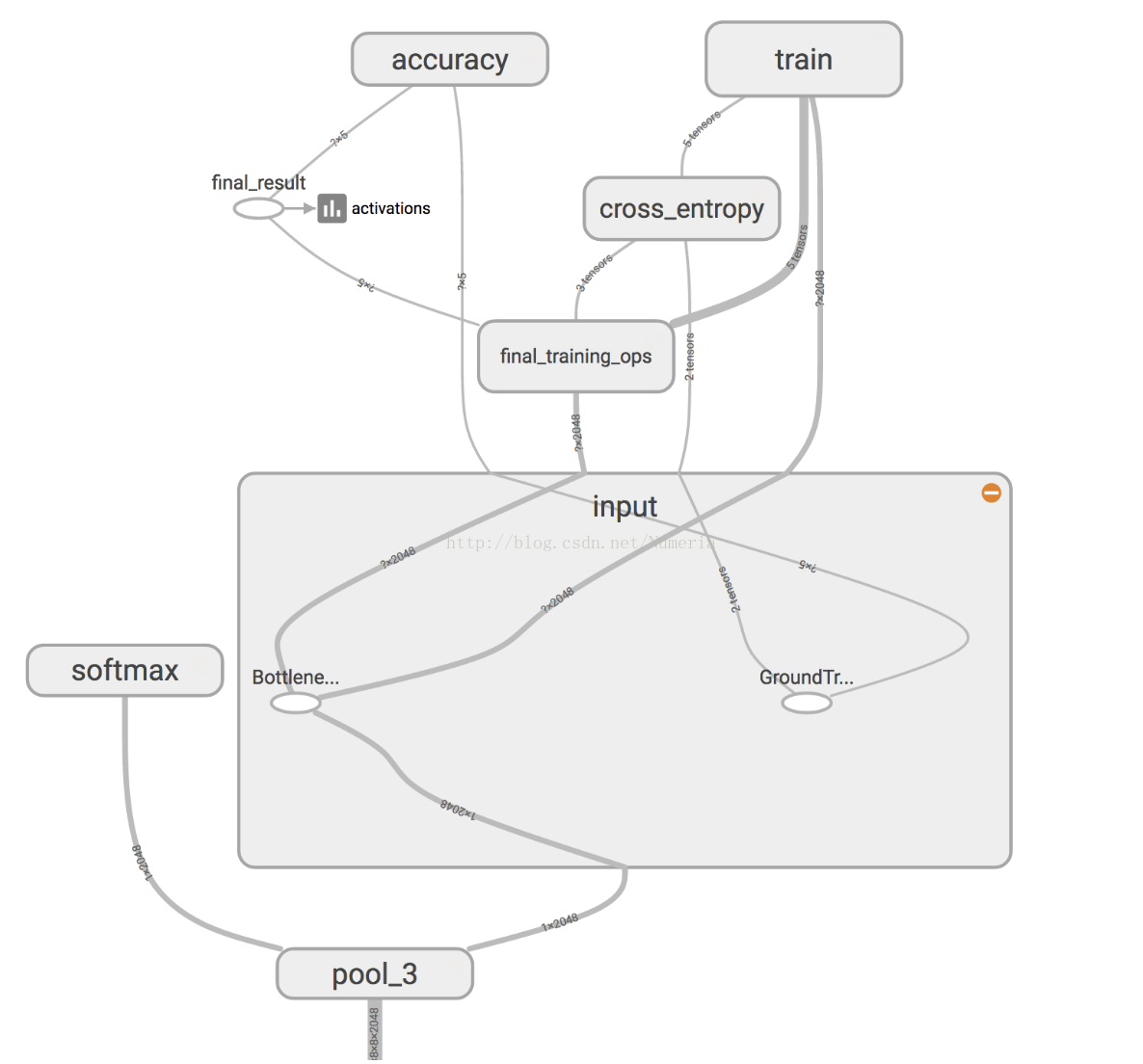
在上图中,左侧标有“softmax”的节点是原始模型的输出层。 而右侧的节点则由再训练脚本添加。 再培训脚本完成后,会自动删除额外的节点。
“bottleneck”是我们经常用于实际进行分类的最终输出层之前的层的非正式术语。 因为,在输出附近,表示比网络的主体更紧凑。
每个图像在训练期间重复使用多次。 计算每个图像bottleneck后面的层需要大量的时间。 由于网络的这些较低层没有被修改,所以它们的输出可以被缓存并重新使用。
所以脚本正在运行网络的常量部分,以下所有标记为Bottlene ...的节点,并缓存结果。
您运行的命令将这些文件保存到bottlenecks /目录。 如果您重新运行脚本,它们将被重用,因此您不必再等待此部分。
traning
一旦脚本完成生成所有的“bottleneck”文件,网络的最后一层的实际训练就开始了。
训练通过将每个图像的缓存值提供给“bottleneck”层来高效运行。 每个图像的真实标签也被馈送到标记为GroundTruth的节点。 这两个输入就足以计算分类概率,训练更新以及各种绩效指标。
在训练中,您将看到一系列步进输出,每个输出显示训练准确性,验证精度和交叉熵:
训练准确性显示在当前训练批中使用正确类别标记的图像的百分比。
验证准确性:验证精确度是来自不同集合的随机选择的图像组的精度(正确标记的图像的百分比)。
交叉熵是一个损失函数,可以看出学习过程的进步情况如何(这里的数字越少越好)。
下图显示了模型在训练时的准确性和交叉熵的进展情况。 如果您的模型已经生成”bottleneck“文件,您可以通过打开TensorBoard并点击图形名称来显示模型的进度。 TensorBoard可能会向您的命令行打印警告。 这些可以安全地忽略。


网络性能的真正衡量标准是测量其在不在训练数据中的数据集的性能。使用验证精度测量此性能。如果训练准确度很高,但是验证精度仍然很低,这意味着网络过度拟合,并且网络正在记忆训练图像中的特定特征,这些功能不能更一般地分类图像。
培训的目标是使交叉熵尽可能小,所以您可以通过关注失败是否向下倾斜,忽略短期噪音来判断学习是否正常工作。
默认情况下,此脚本运行4000个培训步骤。每个步骤从训练集中随机选择10张图像,从缓存中找到”bottleneck“,并将其馈送到最后一层以获得预测。然后将这些预测与实际标签进行比较,以通过反向传播过程更新最终层的权重。
随着流程的继续,您应该看到报告的准确性提高。所有的训练步骤完成后,该脚本将对与培训和验证图片分开的一组图像进行最终测试精度评估。该测试评估提供了对训练模型如何在分类任务上执行的最佳估计。
您应该看到精度值在85%到99%之间,尽管训练过程中随机性的确切值会因运行而异。 (如果您仅在两个班上进行训练,则应该期望更高的精度。)该数值表示在模型完全训练后给出正确标签的测试集中的图像的百分比。
五.使用再训练模型
重新训练脚本将会写出一个Inception v3网络的版本,其中最后一个图层被重新应用到您的类别为tf_files / retrained_graph.pb以及包含tf_files / retrained_labels.txt标签的文本文件。
这是一个python脚本读取你的新图片文件并开始训练它
curl -L https://goo.gl/3lTKZs > label_image.py下面我们使用这个脚本来对一张图片进行测试:

这是一张雏菊的图片,测试这个图片的命令行为
python label_image.py flower_photos/daisy/21652746_cc379e0eea_m.jpg得出的结果为:
daisy (score = 0.99071)
sunflowers (score = 0.00595)
dandelion (score = 0.00252)
roses (score = 0.00049)
tulips (score = 0.00032)
你也通过修改图片路径,测试其他图片。















 2051
2051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









