







本文所谓的单标签分类指的是最终的结果为多类中选择得分最高的一类进行输出,之所以叫单标签,是为了和后面文章中的多标签相对应。
首先给出这个工作的主体流程,然后针对每一步再做比较细致的讲解。
- 准备数据(图像整理好放到合适的文件夹中,对应的ground-truth整理到一个txt中)。
- 数据转换(利用caffe提供的脚本,将原生数据转换成caffe支持的格式,本文使用的LMDB)。
- 网络模型的定义/编辑(本文做的是在预训练模型上fine-tune,所以简单地更改网络的输入输出等即可)。
- Solver的定义/编辑(solver是caffe用来训练网络的一个类似配置文件的东西)。
进行网络模型的训练与测试(基于预训练的模型)。
准备数据
这步主要是自己先把数据集划分好,比如训练集、验证集和测试集各多少张,并把相应的图片放到对应的文件夹下。一些针对图像本身的预处理,比如要进行数据增强,就可以在此步实现(数据增强在第2步数据转换时也可以做,但是没有自己手动的数据增强灵活)。除此之外,就是要生成一个txt文件来描述数据集的ground-truth,如下图所示:
文件在形式上就包含两项,第一项是图片名称(或者包含名称的路径),第二项是图片对应的类别ID(以单个整数表示,如0,1,2,3……),中间以空格间隔。数据转换
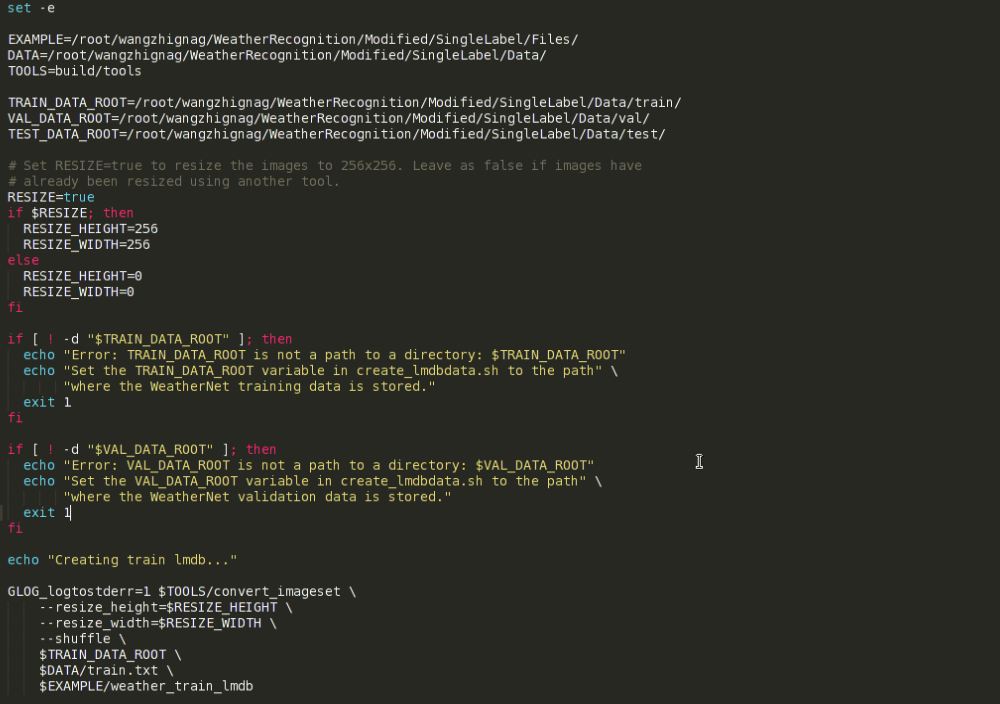
这一步可以利用caffe自带的例子中的脚本完成数据转换。从caffe的根目录进入到次级目录examples中,再找到imagenet文件夹,里面有一个名为create_imagenet.sh的文件,此文件即进行数据转换的脚本。将此脚本文件复制一份到自己项目的合适目录下,然后进行一定的更改即可,下面以本人具体工作为例进行些许解释。
上图即为数据转换脚本文件的主要内容,主要有一些路径和参数需要进行更改。图中,从上到下各变量代表的意思依次是:EXAMPLE指定转换后的lmdb数据存放的路径,DATA指定原生数据所在目录,TOOLS指定实际进行数据转换时所用到的文件所在的目录,即build/tools,注意这是个相对路径,此路径不必做更改,不过这样一来,则必须在caffe的根目录下执行该脚本文件。将TOOLS改为绝对路径应该就破除了上句所说的限制,但本人并未尝试过。从脚本文件中再往下看,三个…DATA_ROOT变量分别代表训练集、验证集和测试集所在目录。也就是说,在第一步准备数据之后,数据集和对应的标注文件应是下图所示样子:
接着往下看,首先是RESIZE选项,默认为true,由于本人使用的是AlexNet预训练模型,一般是先把图片resize到256*256的大小(再做裁剪,后面会提到)。当然,resize的高和宽都是可以根据具体的要求而更改的。如不需要resize,将RESIZE变量设为false即可。
再往下是运行时的一些错误提示信息,这里主要是针对数据集的路径进行了异常检测,也可以根据需要自行添加其他的错误提示,万一数据集路径写错,运行时大概会报如下错误:
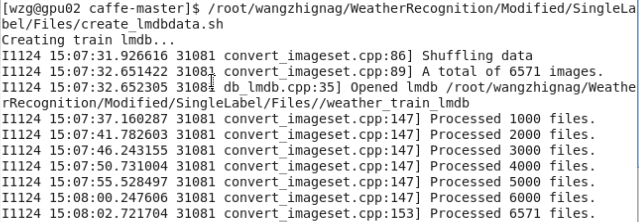
脚本文件的最后是实际调用数据转换文件进行操作的关键部分,这里指定了图片resize的大小和shuffle选项,shuffle就是指将原数据集打乱重新排列,另外,最后三项分别指定了如前所述的数据集所在目录、ground-truth标注文件和生成数据的名称及存储路径,脚本文件执行情况如下图所示:
最终完成后,最终会在指定的目录下得到如下三个文件夹,名字是脚本文件中指定的。
除了生成这些文件,还需要生成一个均值文件,因为机器学习算法一般都会对数据做去均值化处理,此均值文件会在网络训练时用到。同样的有一个执行这种操作的脚本文件,也可以在”caffe_root”/examples/imagenet文件下找到,内容很简单,如下所示:
前三个变量和上个脚本中是一样的,只是具体命令上需要注意一下,这里用到了刚刚生成的训练集的lmdb文件,本工作中的名字是”weather_train_lmdb”,请根据具体情况自行更改。命令的第二行即生成的均值文件的名称和存储路径。在caffe根目录下运行此脚本文件,最终会在指定路径下得到”_mean.binaryproto”文件。网络模型的定义/编辑
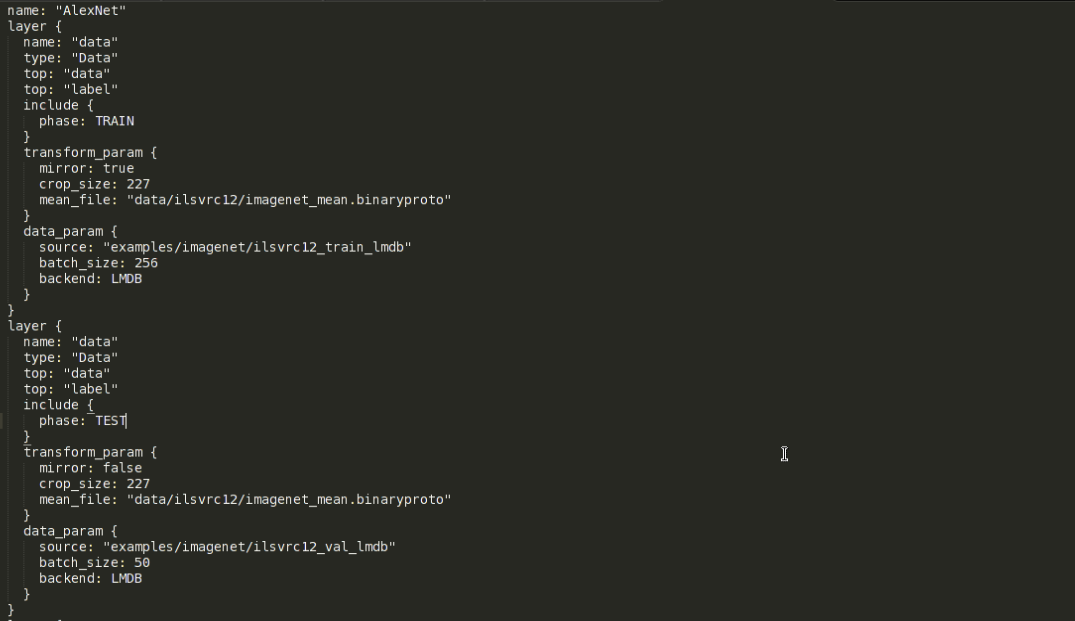
数据转换完成后,就可以对我们所用的网络结构进行编辑更改了,完全自定义新的网络结构并从头训练当然也是可以的,不过本文旨在说明使用caffe做fine-tune的过程,下面就以AlexNet为例,进行网络结构编辑的说明。caffe中,网络结构最终是以.prototxt(文件后缀)文件来定义的,可以通过写代码来定义网络,不过最后还是要生成一个.prototxt文件来执行,所以本人就直接在AlexNet的定义文件中直接进行了修改。AlexNet的网络定义文件可以在”caffe_root”/models/bvlc_alexnet文件夹下找到,即train_val.prototxt文件。对于一个普通的识别任务来讲,主要就是要更改输入层和输出层(全连接层的最后一层)。原AlexNet的网络定义文件的输入层部分如下所示:
可以看到,此文件包含两个输入层,每个layer对应的大括号中的内容分别对应着一个输入层的定义。具体的prototxt文件的格式、每层网络的定义请参见caffe官网http://caffe.berkeleyvision.org/
两个输入层一个是训练时用,一个是测试验证时用,以include{phase:}标签来区别,训练的输入层对应的phase是TRAIN,而测试验证的输入层对应的是TEST。本人为了后续训练测试时的灵活性起见,将训练和测试网络用两个独立的prototxt文件来定义,其实它们主要是输入层的不同。再来看transform_param,这是转换参数,此项主要用于数据增强,mirror变量代表图片镜像变换,其值为true则在训练时对图片进行随机的镜像变换。crop_szie代表图片裁剪后的大小,而AlexNet指定的输入图像为227*227,而我们之前做数据转换时图片resize的大小是256*256,所以这里要裁剪一下。如果是训练阶段,则裁剪是在图片内随机进行的,这样也可以起到一定的数据增强效果,如果是测试阶段,则裁剪图片正中央的部分。这里一定要保证图片原始尺寸比裁剪后的尺寸大。mean_file要指定我们之前在数据转换阶段生成的均值文件,指定好之后,就可以在训练测试时对数据做去均值化处理了。
data_param中,source变量指定转换后的lmdb文件路径,batch_size很好理解,就是一个batch包含多少张图片,backend指定数据的类型,这里自然是LMDB。
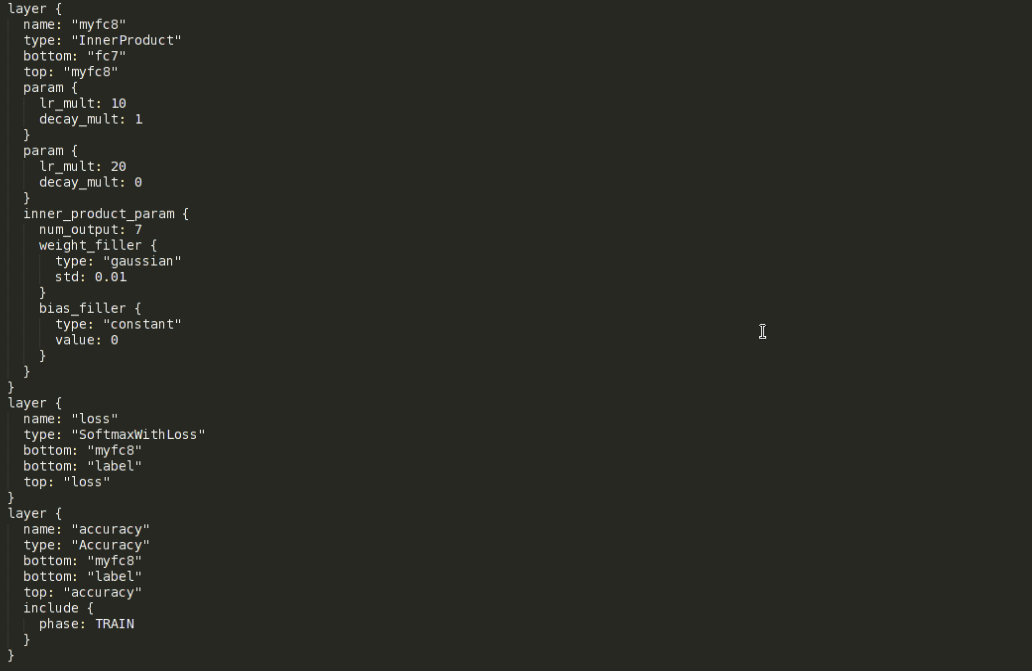
接下来是输出层、loss层和accuracy层的修改,下图展示的是我更改后的定义:
原本输出层的名字是fc8,这里首先要把名字改掉。因为fine-tune时会从预训练的模型中拷贝参数,而实际操作时是按对应层的名字进行参数拷贝的,改掉名字后就会自动忽略这一层而不会进行拷贝。然后top变量对应的值也改成当前层的名字,之后两个param中分别定义了当前层网络的权重和偏置的学习率以及权值衰减参数。权值衰减参数是正则项(为了避免过拟合,大多数网络除了正则项还会在网络中加入dropout层)的系数,这里一般不做更改。两个lr_mult(learning rate)都是其它层的10倍,因为其他层是在做fine-tune,而输出层根据任务的不同,输出单元的个数往往和预训练模型不一样,这就导致无法对输出层也做fine-tune(输出单元数目不同,无法直接拷贝参数)。那么输出层就需要从头训练,给一个较大的学习率是希望它能尽快收敛。再下面是inner_product_parm,这里面主要修改的是num_output,即输出单元的个数,具体视不同任务而定,比如本工作中类别数目是7类,所以图中此项的值就为7。其余的都不更改。至于剩余的参数这里就不专门介绍了,感兴趣者可以查阅官网或其他资料进行了解。loss层和accuracy层里面主要把除label外的bottom项改成我们自己的输出层的名字即可。到此为止,网络模型就修改完毕了。
Solver的定义/编辑
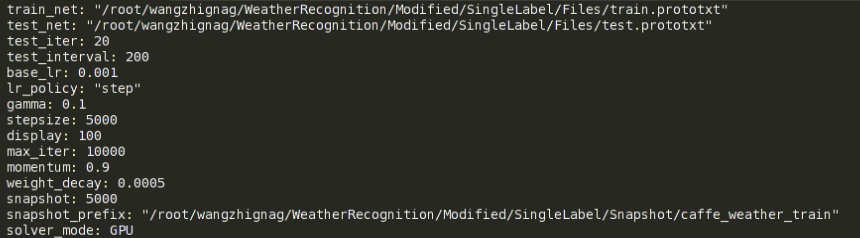
solver可以简单地理解为一个配置文件,里面定义了很多和训练测试相关的参数,本工作的solver文件截图如下:
前两项分别用来指明网络模型的定义文件的路径,由于本人是将训练网络和测试网络分开定义的,所以这里就对应着有这两项,原本caffe自带的AlexNet例子中只有下面这一行:net: "models/bvlc_alexnet/train_val.prototxt"solver文件中接下来是test_iter,这个变量要特别注意一下,它指定的数字和网络结构定义中指定的batch_size的乘积要等于测试集包含的图片的数量。比如本例中,测试集总共1000张图片,batch_size是50,所以test_iter就得设为20。其实这个test_iter就指定了一次测试跑多少个iteration(一个iteration就是一次迭代),也就等于跑多少个batch,只有test_iter*batch_size等于测试集图片总数时,才是一次测试恰好把测试集遍历一遍。
test_interval和display放到一起来说,前者指定训练中每隔多少次iteration进行一次测试,后者指定每隔多少次iteration进行阶段性的输出显示,显示内容主要就是loss和accuracy的情况。
base_lr指的是基础learning rate,它和网络定义中每层各自的learning rate的乘积是各个参数实际的学习率,solver文件中的weight_decay也是同样道理,它指的是基础的权值衰减系数。lr_ploicy指的是学习策略,如果设为”fixed”,则在整个训练过程中,基础学习率保持不变。不过这里我们采用”step”策略,它和gamma、stepsize项共同起作用。实际效果就是训练中每隔stepsize指定的迭代次数,基础学习率就乘以一次gamma值,gamma是一个小数,一般设为0.1,这样做的理由是:训练越往后网络参数越趋近于收敛,相应地也应该调低学习率。max_iter指定一共训练多少个iteration,momentum指定随机梯度下降优化方法中的动量值,这里对算法本身不做介绍。snapshot指定每隔多少次iteration对模型参数和内存状态进行一次存储,目的是应对突然断电或者训练到后面网络性能反而下降的情况。snapshot中存储的中间模型参数既可以直接拿来使用,也可以继续在其上fine-tune(这点就是为了应付突然断电的情况)。snapshot_prefix指定的是snapshot存储的路径和名字前缀,根据迭代次数不同,名字后还会加上存储snapshot时的iteration次数。solver_mode指定了硬件是用CPU还是GPU。另外,如不指定所用的优化方法,则默认使用随机梯度下降算法。针对不同的优化方法,solver中的参数也有不同,这里不做过多介绍。到此,solver文件就修改完毕了。
网络模型的训练与测试
前面的准备工作都做好后就可以开始进行网络的训练与测试了,这一步可以直接从命令行进行,具体参见caffe官网fine-tune例子。本工作中为了能够灵活地进行展示与绘图,决定使用caffe的Python接口,通过写代码来进行训练测试。不过首先需要编译pycaffe。
代码中,首先要导入caffe模块,后两行用来指定在GPU模式下训练网络以及指定使用哪块显卡(多卡情况下)。import caffe caffe.set_mode_gpu() caffe.set_device(2)然后指定好预训练好的模型所在的目录,为fine-tune做准备。
weights = caffe_root + 'models/weatherNet/weatherDB_sp1.caffemodel'再接下来就是定义运行solver的函数了:
def run_solvers(niter, solver, disp_interval=100, test_interval=200, test_iter=20): fig1,ax1=plt.subplots() #used for draw fig2,ax2=plt.subplots() #used for draw train_loss=np.zeros(np.ceil(niter*1.0/disp_interval)) train_acc=np.zeros(np.ceil(niter*1.0/disp_interval)) test_loss=np.zeros(np.ceil(niter*1.0/test_interval)) test_acc=np.zeros(np.ceil(niter*1.0/test_interval)) atom_train_loss, atom_train_acc, atom_test_loss, atom_test_acc = 0, 0, 0, 0 train_count, test_count = 0, 0 for it in range(1, niter+1): solver.step(1) atom_train_loss += solver.net.blobs['loss'].data atom_train_acc += solver.net.blobs['accuracy'].data if it % disp_interval == 0: train_loss[train_count] = atom_train_loss/disp_interval train_acc[train_count] = atom_train_acc/disp_interval atom_train_loss=0 atom_train_acc=0 print '\n##########%d iteration train: loss=%.3f, accuracy=%.3f\n' %(it, train_loss[train_count], train_acc[train_count]) train_count += 1 if it % test_interval == 0: for test_it in range(test_iter): solver.test_nets[0].forward() atom_test_loss += solver.test_nets[0].blobs['loss'].data atom_test_acc += solver.test_nets[0].blobs['accuracy'].data test_loss[test_count] = atom_test_loss/test_iter test_acc[test_count] = atom_test_acc/test_iter atom_test_loss=0 atom_test_acc=0 print '##########%d iteration Test: loss=%.3f, accuracy=%.3f\n' %(it, test_loss[test_count], test_acc[test_count]) test_count += 1 ################## Draw ax1.cla() ax1.set_title('Display Loss') ax1.set_xlabel('Iteration/100') ax1.set_ylabel('Loss') ax1.set_xlim(0,100) ax1.grid() ax1.plot(train_loss[:train_count],'r',label='train loss') ax1.plot(range(0,test_count*2,2),test_loss[:test_count],'g',label='test loss') ax1.legend(loc='best') ax2.cla() ax2.set_title('Display Accuracy') ax2.set_xlabel('Iteration/100') ax2.set_ylabel('Accuracy') ax2.set_xlim(0,100) ax2.grid() ax2.plot(train_acc[:train_count],'r',label='train accuracy') ax2.plot(range(0,test_count*2,2),test_acc[:test_count],'g',label='test accuracy') ax2.legend(loc='best') plt.pause(1) return train_loss, test_loss, train_acc, test_acc函数参数中,niter对应的就是solver文件中的max_iter,即训练总共迭代多少次。solver参数指定solver文件的路径,disp_interval=100, test_interval=200, test_iter=20这三项分别对应solver文件中的display、test_interval和test_iter。
fig1,ax1=plt.subplots() #used for draw fig2,ax2=plt.subplots() #used for draw开头这两句是为后面展示loss和accuracy的动态画图生成的对象,画图相关内容请参见我的上篇博文。
train_loss=np.zeros(np.ceil(niter*1.0/disp_interval)) train_acc=np.zeros(np.ceil(niter*1.0/disp_interval)) test_loss=np.zeros(np.ceil(niter*1.0/test_interval)) test_acc=np.zeros(np.ceil(niter*1.0/test_interval)) atom_train_loss, atom_train_acc, atom_test_loss, atom_test_acc = 0, 0, 0, 0 train_count, test_count = 0, 0接下来这些代码是为存储相关的loss、accuracy而准备的,主要是提前为变量分配好内存空间。
循环里是运行solver并进行统计的主要内容,关键代码就是下面这一行:
solver.step(1)step()函数是caffe中solver对象自带的,每循环一次就step一下,而step一次其实是包含两个步骤,即网络在一个batch上前向计算一次,得到相应的loss和accuracy。然后再反向传播一次,进行网络参数的更新。
atom_train_loss += solver.net.blobs['loss'].data atom_train_acc += solver.net.blobs['accuracy'].data if it % disp_interval == 0: train_loss[train_count] = atom_train_loss/disp_interval train_acc[train_count] = atom_train_acc/disp_interval atom_train_loss=0 atom_train_acc=0 print '\n##########%d iteration train: loss=%.3f, accuracy=%.3f\n' %(it, train_loss[train_count], train_acc[train_count]) train_count += 1 if it % test_interval == 0: for test_it in range(test_iter): solver.test_nets[0].forward() atom_test_loss += solver.test_nets[0].blobs['loss'].data atom_test_acc += solver.test_nets[0].blobs['accuracy'].data test_loss[test_count] = atom_test_loss/test_iter test_acc[test_count] = atom_test_acc/test_iter atom_test_loss=0 atom_test_acc=0 print '##########%d iteration Test: loss=%.3f, accuracy=%.3f\n' %(it, test_loss[test_count], test_acc[test_count]) test_count += 1这段代码主要进行loss和accuracy的统计,大概意思是每次迭代都对loss和accuracy进行累加,等到了该显示的迭代次数时,对loss、accuracy求一个平均值,并记录下来。用于累加的atom…_loss和atom…_acc清空,然后在控制台对当前的结果进行显示。前一段代码是针对训练数据的,而后一段则是针对测试的,性质都一样。
再往下就是画图代码了,关于画图的内容就不再细讲了,可以参考我的上篇博文。
实际运行时,使用下面三句代码:
solver = caffe.get_solver('/root/wangzhignag/WeatherRecognition/Modified/SingleLabel/Files/so lver.prototxt') solver.net.copy_from(weights) train_loss, test_loss, train_acc, test_acc = run_solvers(10000,solver)第一句是从我们定义的solver文件中获取相关参数的设定,从而创建一个solver对象。第二句是使用预训练的模型给网络做参数初始化,这里的weights是前面指定好的预训练模型的路径。最后一句则是调用刚刚定义的run_solver()函数来得到相应的loss和accuracy。
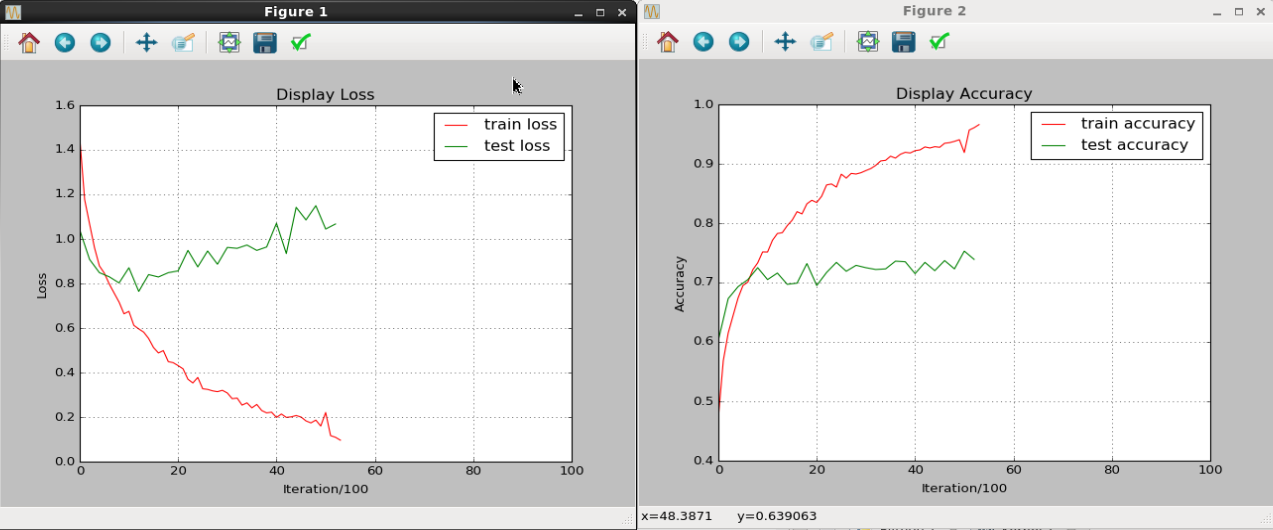
上图是运行过程中的结果展示情况,可以看出无论是loss还是accuracy,训练集和测试集上的结果都有着明显的gap,个人猜测应该是数据量不足导致无法完全发挥CNN的性能。动态画出中间结果也是为了能及时地发现过拟合现象,从而尽早停止训练。接着,再定义一个专门计算准确率的函数:
def eval_net(Netdef=caffe_root + 'models/weatherNet/test.prototxt', weights='/root/wangzhignag//WeatherRecognition/SingleLabelWeatherNet/snapshot/caffe_ weather_train_iter_10000.caffemodel', test_iters=20): test_net = caffe.Net(Netdef, weights, caffe.TEST) accuracy = 0 for it in xrange(test_iters): accuracy += test_net.forward()['accuracy'] accuracy /= test_iters return test_net, accuracy函数参数包括测试网络的定义文件(prototxt)的路径,训练好的网络模型的路径,以及test_iter(含义与run_solver函数的一样)。函数体里面,先使用网络定义文件和训练好的网络模型来创建出一个测试网络的对象,具体求值过程很简单,就是每次迭代累加accuracy,最后求一个平均值就OK了。
至此,整个流程就都介绍完了,还有一些附加的功能比如展示图片和相应的预测结果,给出前K大得分对应的类别等等这里就不介绍了,感兴趣者可以参考caffe官网中给出的例子使用jupyter notebook进行fine-tune。



















 1743
1743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









