






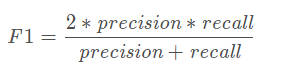
通过函数 sklearn.metrics.f1_score(y_true, y_pred, labels=None, pos_label=1, average=’binary’, sample_weight=None)计算:
y_ture:一维数组或标签,表示正确的标签
y_pred:分类器返回的估计标签
average:多分类需要此标签,如果设为None,将返回各个类的分数,否者对数据进行平均,默认参数为’binary’,仅当target是二进制时才适用,多标签时:
‘weighted’,按加权(每个标签的真实实例数)平均,这可以解决标签不平衡问题,可能导致f1分数不在precision于recall之间。
‘micro’,总体计算f1值,及不分类计算。
‘macro’:计算每个标签的f1值,取未加权平均值,不考虑标签不平衡。















03-27
 1万+
1万+
1万+
04-30
5890
5890
07-18
1701
1701
05-12
1861
1861
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









