






1 如何处理类别变量?
方法一:丢弃(一般不用)
方法二:LabelEncoder
from sklearn.processing import LabelEncoder
label_encoder = LabelEncoder()
X[col] = label_encoder.fit_transform(X[col])
X_val[col] = label_encoder.transform(X_val[col]
方法三:OneHotEncoding:
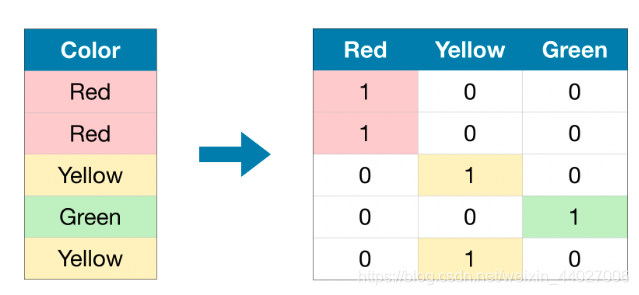
作用:可用来处理无序的类别特征。
注意:当特征类别数大于15的时候不使用该方法
from sklearn.procession import OneHotEncoding
One_H_encoder = OneHotEncoding(handle_unknown='ignore',sparse=False)
OH_cols_train = pd.DataFrame(One_H_encoder.fit_transform(X_train[object_cols])
OH_cols_val = pd.DataFrame(One_H_encoder.transform(X_val[object_cols])
OH_cols_train.index = X_train.index
OH_cols_val.index = X_val.index
num_X_train = X_train.drop(object_cols,axis=1)
num_X_val = X_val.drop(object_cols,axis=1)
OH_X_train = pd.concat([num_X_train,OH_cols_train],axis=1)
OH_X_test = pd.concat([num_X_val,OH_cols_val],axis=1)
方法四:CountEncoding
- 思想:使用某个特征中的某个取值出现的次数来代替这个值
- 为何有效:Rare values tend to have similar counts (with values like 1 or 2), so you can classify rare values together at prediction time. Common values with large counts are unlikely to have the same exact count as other values. So, the common/important values get their own grouping.
代码:
import category_encoder as ce
cat_cols = ['currency','country','category']
count_encoder = ce.CountEncoder()
count_encoded = count_encoder.fit_transform(train_data[cat_cols])
data = baseline_data.join(count_encoded).add_suffix('_count')
方法五:TargetEncoding
-
思想:使用每个特征值对应的均值来替换,比如country=‘A’,可以计算出所有country='A’的样本对应的某个数值型特征的均值是多少。
-
注意1:这里不能将测试集也包含进去,否则会发生Target Leakage。
-
注意2:如果某个特征取值非常多,会导致方差过高。Target encoding attempts to measure the population mean of the target for each level in a categorical feature. This means when there is less data per level, the estimated mean will be further away from the “true” mean, there will be more variance. There is little data per IP address so it’s likely that the estimates are much noisier than for the other features. The model will rely heavily on this feature since it is extremely predictive. This causes it to make fewer splits on other features, and those features are fit on just the errors left over accounting for IP address. So, the model will perform very poorly when seeing new IP addresses that weren’t in the training data (which is likely most new data). Going forward, we’ll leave out the IP feature when trying different encodings.
import category_encoder as ce
cat_cols = ['country','currency','category']
target_encoder = ce.TargetEncoder(cols=cat_cols)
target_encoder.fit(train[cat_cols],train['outcome'])
train = train.join(target_encoder.transform(train[cat_cols]).add_suffix('_target_encode'))
valid = valid.join(target_encoder.transform(valid[cat_cols]).add_suffix('_target_encode'))
方法五:CatBoostEncoder
- 思想:与TargetEncoder类似,但是是计算替换样本前面样本的均值
代码:
import category_encoder as ce
cat_cols = ['currency','country','category']
cat_encoder = ce.CatBoostEncoder(cols = cat_cols)
cat_encoder.fit(train[cat_cols],train['outcome'])
train = train.join(cat_encoder.transform(train[cat_cols]).add_suffix('_target'))
valid = valid.join(cat_encoder.transform(valid[cat_cols]).add_suffix('_target'))
方法6:创建新的feature
- 思路:假设有features:country、population,我们可以创建一个country_population 作为新的feature。
代码:
import pandas as pd
import itertools
from sklearn.preprocessing import LabelEncoder
cat_features = ['currency','country','population']
interaction = pd.DataFrame(index = train.index)
for col1,col2 in itertools.combination(cat_features,2):
new_col_name = '_'.join([col1,col2])
new_values = train.col1.map(str) + '_' + train.col2.map(str)
encoder = LabelEncoder()
interaction[new_col_name] = encoder.fit_transform(new_values)
# 创建一个在过去6个小时各个IP的执行数量
def past_six_hours(series,time_window='6H'):
series = pd.Series(series.index,index=series)
count = series.rolling(time_window).count() - 1
return count
方法7:特征选择
- 使用sklearn.feature_selection 的 SelectKBest
from sklearn.feature_selection import SelectKBest,f_classif
feature_cols = dataset.columns.drop('outcome')
selector = SelectKBest(f_classif,k=5)
X_new = selector.fit_transform(dataset[feature_cols],dataset['outcome'])
#若我们要知道最后保留了哪5个特征,可以使用inverse_transform来转换回来
selected_feature = pd.DataFrame(selector.inverse_transform(X_new),index = dataset.index,columns=feature_cols)
selected_columns = selected_feature.columns[selected_feature.var() != 0]
#L1
from sklearn.linear_model import LogisticRegression
from sklearn.feature_selection import SelectFromModel
def select_features_l1(X, y):
""" Return selected features using logistic regression with an L1 penalty """
logistic = LogisticRegression(C=0.1,penalty='l1',random_state=7).fit(X,y)
model = SelectFromModel(logistic,prefit=True)
X_new = model.transform(X)
selected_features = pd.DataFrame(model.inverse_transform(X_new),index=X.index,columns=X.columns)
cols_to_keep = selected_features.columns[selected_features.var()!=0]
return cols_to_keep
2 Pipeline
Pipeline 好处:
- 让代码更精简与直观
- 减少出现Bug的可能性
- 可以批量进行
代码:
import pandas as pd
import numpy as np
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.processing import OneHotEncoder
from sklearn.imputer import SimpleImputer
from sklearn.model_selection import train_test_split
from sklearn.compose import ColumnTransformer
from sklearn.metrics import mean_absolute_error
X_full = pd.read_csv('X_train.csv')
X_test_full = pd.read_csv('X_test.csv')
X_full.dropna(axis=0,subset=['SalePrice'],inplace=True)
y = X_full.SalePrice
X_full.drop('SalePrice',axis=1)
X_train_full,X_val_full,y_train,y_vaild = train_test_split(X_full,y,test_size=0.3,random_state=0)
categorical_cols = [cols for cols in X_train_full.columns if X_train_full[cols].nunique() <10 and X_train_full[cols].dtype == 'object']
numerical_cols = [cols for cols in X_train_full.columns if X_train_full[cols].dtype in ['int64','float64']]
my_cols = categorical_cols + numerical_cols
X_train = X_train_full[my_cols].copy()
X_val = X_val_full[my_cols].copy()
X_test = X_test[my_cols].copy()
#Step1:
numerical_transform = SimpleImputer()
categorical_transform = Pipline(steps=[('imputer',SimpleImputer(strategy='most_frequent')),\
('onehot',OneHotEncoder(handle_unknown='ignore',sparse=False))]
processor = ColumnTransformer(transformers=[('numerical',numerical_transform,numerical_cols),('cat',categorical_transform,categorical_cols))
#Step2:
model = RandomForestRegressor(n_estimators=100,random_state=0)
my_pipeline = Pipeline(steps=[('processor',processor),('model',model)])
my_pipeline.fit(X_train,y_train)
preds = my_pipeline.predict(X_val)
mean_error = mean_absolute_error(preds,y_val)
3 Cross Validation
适用于:小数据集
代码:
from sklearn.model_selection import cross_val_error
from sklern.ensemble import RandomForestRegressor
from sklearn.pipeline import Pipeline
from sklearn.imputer import SimpleImputer
def get_score(n_estimators,X,y)
my_pipeline = Pipeline(steps=[('Imputer',SimpleImputer(strategy='median'))
\,('model',RandomForestRegressor(n_estimators=n_estimators,random_state=0))])
score = -1*cross_val_score(my_pipeline,X,y,cv=5,scoring='neg_mean_absolute_error')
return score.mean()
4 XGBoost
理念:首先初始化一个弱学习器,然后用这个弱学习器进行预测并计算损失,然后根据损失训练出一个新的学习器,将新学习器加入到大的学习器当中,然后迭代上面的步骤。
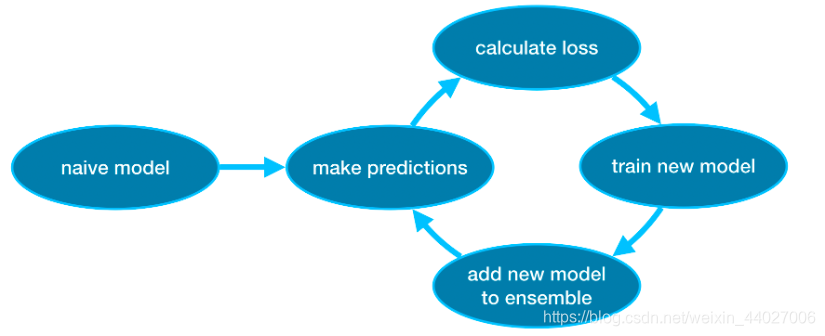
重要参数:
- n_estimators:学习器的数量,也可以看作是迭代的轮数,通常设为100-1000之间,太低会欠拟合,太高会过拟合。
- early_stopping_rounds:若loss值几轮未改变,就提早停止,通常设为5,用较高的n_estimators和early_stoppint_rounds搭配是个好选择
- eval_set:与early_stoppint_rounds一起搭配使用,用来计算validation score.
- n_jobs:当数据集很大的时候,可以设置这个参数,相当于分布式运算。
- learning_rate:给每个基学习器一个权重,而非简单相加,默认为0.1
代码:
from xgboost import XGBRegressor
model = XGBRegressor(n_estimators=500,learning_rate=0.01,random_state=0)
model.fit(X_train,y_trian,early_stopping_rounds=5,eval_set=[(X_valid,y_valid)],verbose=False)
5 Data leakage
1.Target Leakage:
- 发生场景:当数据集当中包含着那些在预测时不会发挥作用的样本时。
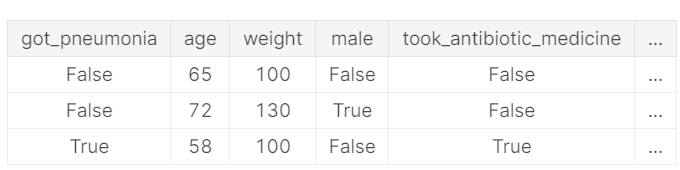
- 在上面的这个数据集中可以发现,took_antibiotic_medicine的改变经常会使得got_pneumonia发生改变,利用这个数据训练出来的模型虽然在验证集上表现很好,但是当我们拿到现实世界去的时候往往精度非常的低。原因在于:使用这个模型的目的在于预测某位病人是否得了这个病,所以一般来看病的人,即使他们已经患上了,他们也尚未拿到药,所以利用这个模型进行预测显然是不准确的,因为一些数据在预测中是不起作用的。
2.Train-Test Contamination
- 发生场景:当我们在分离训练集和验证集之前,对数据集进行了填充或者归一化。















 921
921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









