









Abstract
背景:
需要一种能扩大SPECT骨显像数据集的数据生成方法。
方法:
一种基于深度学习的SPECT骨显像生成模型。
采用生成对抗学习结构,提出骨转移显像生成模型(bone metastasis scintigram generation model,BMS-Gen)。
BMS-Gen采用多输入条件和多感受野学习来确保生成样本的真实性。
BMS-Gen采用生成对抗学习来保持生成样本的多样性。
BMS-Gen采用两阶段训练策略来提高生成样本的质量。
结果:
在 SPECT 骨转移显像图的临床数据上进行的实验评估显示了BMS-Gen的性能。
在FID(Fréchet初始距离)、MSE(均方误差)和PSNR(峰值信噪比)指标上获得了最好的总分。
在图像分类和分割任务中,BMS-Gen生成的样本的引入使F-1得分最大(最小)增加了3.01%(0.15%),DSC得分最大(最小)增加了6.83%(2.21%)。
1. Introduction
- 99 m Tc-MDP ^{99m}\text{Tc-MDP} 99mTc-MDP (technetium-99 methylene phosphonic acid)——锝-99亚甲基二膦酸盐
- SPECT \text{SPECT} SPECT (single photon emission computed tomography)——单光子发射计算机断层扫描
- PET \text{PET} PET (Positron Emission Tomography )——正电子发射断层扫描
- BM \text{BM} BM (bone metastasis)——骨转移
- BMS-Gen \text{BMS-Gen} BMS-Gen (bone metastasis scintigram generation model)——骨转移显像生成模型
使用
99
m
Tc-MDP
^{99m}\text{Tc-MDP}
99mTc-MDP 和
SPECT
\text{SPECT}
SPECT 成像设备,可以在显像图中识别和显示
BM
\text{BM}
BM 病变区域,该区域表现为放射性药物高摄取区域,通常称为“热点”。
SPECT骨显像的典型特征是空间分辨率低,骨转移病变在位置、大小和形状上不规则和不可预测。
两类CNN用于SPECT骨显像的自动分析:
- 用于自动确定图像中是否存在骨转移,将其分类到相应的类别。
- 用于通过分割图像来自动分离BM病灶。
都需要大规模的SPECT骨显像样本。
生成对抗网络(GAN)是深度生成学习中最强大的框架之一,包含一个将潜在噪声空间映射为真实图像的生成器和一个用于区分数据库中样本与生成器生成样本的判别器。
主要挑战有两点:
- SPECT骨显像较低的空间分辨率对从原始数据中生成细粒度的样本提出了很高的要求;
- 骨转移病灶在位置、大小和形状方面的不可预测性和不规则性,使得基于深度学习的模型很难表征低分辨率的骨显像图像。
BMS-Gen特点:
- 采用多输入条件和多感受野学习来确保生成样本的真实性。
- 采用生成对抗学习来保持生成样本的多样性。
- 采用两阶段训练策略来提高生成样本的质量。
贡献:
- 确定了BM显像自动生成这一研究问题,基于深度学习的医学图像分析领域中的首个相关研究。
- 提出了基于GAN的BMS-Gen模型。
- 评估并验证了生成样本在提升下游任务性能中的实用性。
2. Methods
2.1 An overview——概述
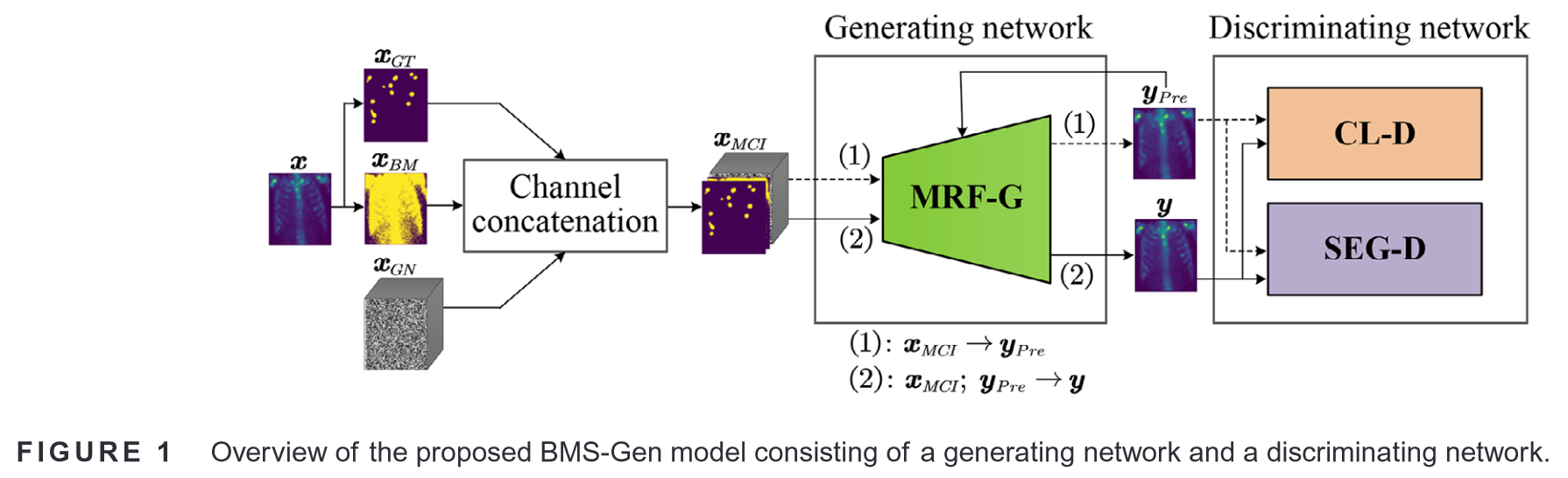
- MRF-G \text{MRF-G} MRF-G (multi-receptive field generator)——多感受野生成器
组成:
生成网络和判别网络,生成网络使用定制的生成器——MRF-G。
样本:
病灶标签
x
G
T
x_{GT}
xGT ,由经验丰富的专家使用开源工具LabelMe获取;
二值矩阵
x
B
M
x_{BM}
xBM ,将x中的所有非零元素设为1、所有零元素设为0来创建二值矩阵;
3D高斯噪声
x
G
N
x_{GN}
xGN ;
x
G
T
x_{GT}
xGT 和
x
B
M
x_{BM}
xBM 集成到
x
G
N
x_{GN}
xGN 形成多通道输入
x
M
C
I
x_{MCI}
xMCI 。集成的
x
G
T
x_{GT}
xGT 和
x
B
M
x_{BM}
xBM 可视为3D噪声
x
G
N
x_{GN}
xGN 的条件信息,代表多种条件。
初步训练阶段:
基于
x
M
C
I
x_{MCI}
xMCI 生成初步样本
y
P
r
e
y_{Pre}
yPre(即,
x
M
C
I
→
y
P
r
e
x_{MCI} \rightarrow y_{Pre}
xMCI→yPre)。
精炼训练阶段:
生成器MRF-G利用
y
P
r
e
y_{Pre}
yPre 和
x
M
C
I
x_{MCI}
xMCI ,生成最终的精炼样本
y
y
y(即,
x
M
C
I
;
y
P
r
e
→
y
x_{MCI} ; y_{Pre} \rightarrow y
xMCI;yPre→y)。
生成阶段:
判别网络通过分类判别器(CL-D)衡量生成样本的真实性;
通过分割判别器(SEG-D)计算生成像素与真实像素之间的语义相似度。
这种两阶段训练策略显著提高生成样本的质量。
2.2 The architecture of the BMS-Gen model——BMS-Gen模型的体系结构
增强生成器和判别器的能力对于开发高性能模型至关重要。
2.2.1 The generating network——生成网络
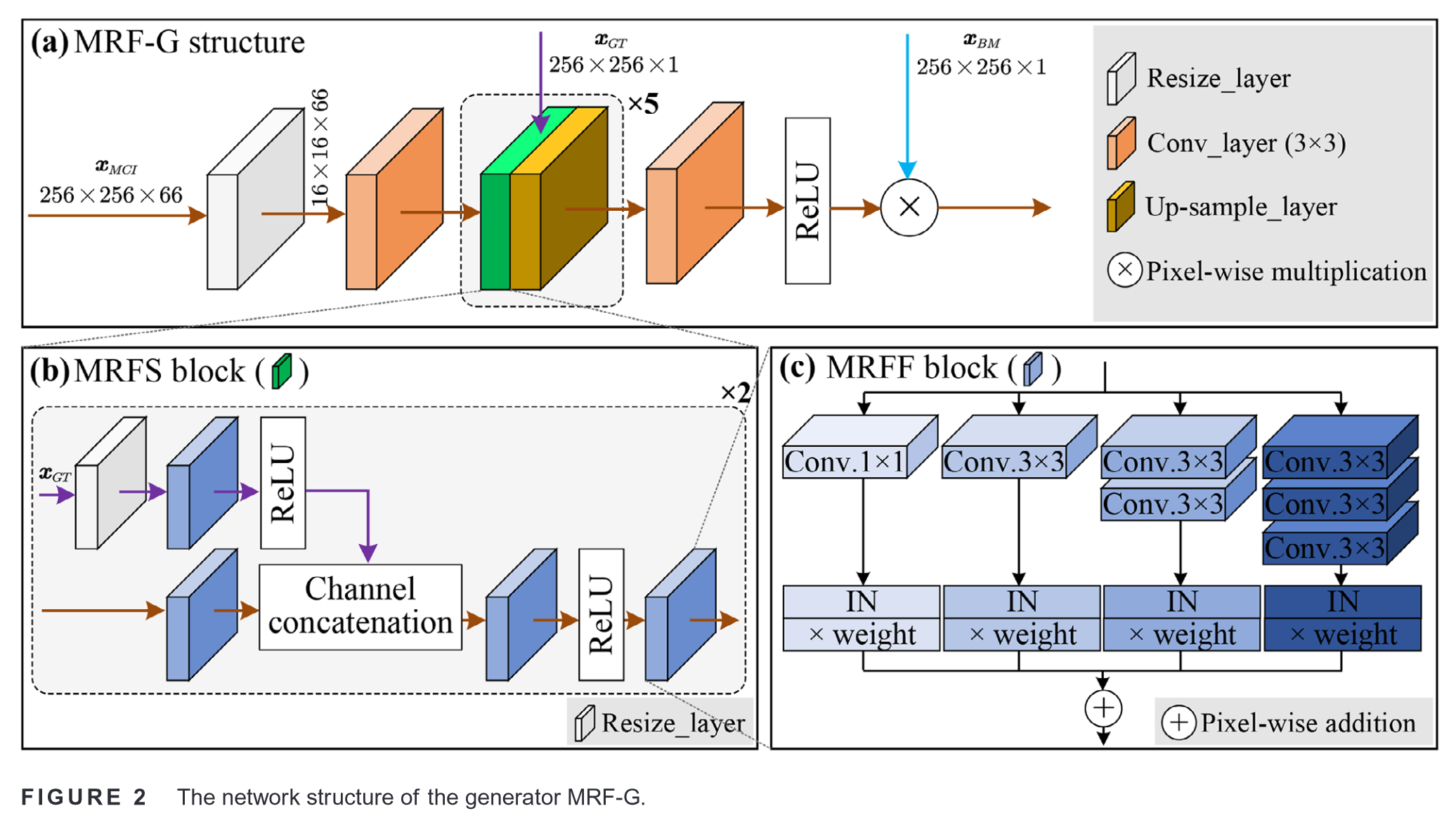
- MRFS \text{MRFS} MRFS (MRF synthesis)——多感受野生成
- MRFF \text{MRFF} MRFF (MRF fusion)——多感受野融合
- IN \text{IN} IN (Instance Normalization)——实例归一化
MRF-G通过将病灶标签 x G T x_{GT} xGT 输入到不同的层次,强化模型对病灶语义信息的理解,并在输出层使用 x B M x_{BM} xBM 控制生成图像的整体结构。
MRFS模块是 MRF-G的核心,通过使用MRFF,concat 双路径输入来生成逼真的假样本。
MRFF模块,四个不同接收场(即卷积核)的并行分支生成了四个特征图,以捕捉大小各异的BM病灶。随后按各自的权重进行加权,通过逐像素加法操作进行融合。
MRFF模块中,
使用两个连续的3 × 3卷积来替代5 × 5卷积,使用三个连续的3 × 3卷积替代7 × 7卷积,减少计算开销。
使用逐像素加法而不是通道级联进行特征融合,以保持相关结构并改善信息的估计。
使用IN对每个特征图单独进行归一化操作,确保了不同特征不混合,保持输入条件与生成结果之间的映射关系。
MRFF模块具有通过MRF卷积提升MRF-G学习能力的潜力,能够同时捕捉不同尺度的图像特征,提取局部细节特征和全局结构特征。
MRF-G可以通过融合不同接收场的特征,在不同尺度上整合视觉和语义信息。
MRFF模块的并行结构也能增加网络的宽度,能够在一定程度上缓解过拟合问题,并防止合成图像与训练数据过于相似,从而保证多样性。
2.2.2 The discriminating network——判别网络
- CL-D \text{CL-D} CL-D (classification-based discrimination)——基于分类的判别器
- SEG-D \text{SEG-D} SEG-D (segmentation-based discrimination)——基于分割的判别器
CL-D使用ResNet作为主干网络,对生成的样本进行分类,进行图像级别的分类判别,以确定生成的样本是否是真实的。无法提供细粒度的指导信息,可能导致模式崩溃的陷阱。
SEG-D使用U-Net作为主干网络,促使生成器专注于图像中的语义对象,能够保持真实图像和生成样本之间感兴趣区域(即病灶)的语义一致性。
2.2.3 Loss functions——损失函数
- BCE \text{BCE} BCE (Binary CrossEntropy)——二元交叉熵
整个网络通过对标签预测损失的反向传播以极小化方式联合训练,生成器通过更新来最小化损失,判别器通过更新来最大化损失。
BMS-Gen采用了BCE损失来定义其损失函数:
ℓ
=
−
E
I
,
φ
[
φ
log
(
D
(
I
)
)
+
(
1
−
φ
)
log
(
1
−
D
(
I
)
)
]
(1)
\ell = -\mathbb{E}_{I,\varphi} \left[ \varphi \log(D(I)) + (1 - \varphi) \log(1 - D(I)) \right] \tag{1}
ℓ=−EI,φ[φlog(D(I))+(1−φ)log(1−D(I))](1)
D 表示判别器,I 是输入到 D 的图像,φ 表示 I 的类别标签。
两个判别器的损失函数定义为:
ℓ
C
L
−
D
=
ℓ
(
y
,
C
L
−
D
)
+
ℓ
(
M
R
F
−
G
,
C
L
−
D
)
(2)
\ell_{CL-D} = \ell(y, CL-D) + \ell(MRF-G, CL-D) \tag{2}
ℓCL−D=ℓ(y,CL−D)+ℓ(MRF−G,CL−D)(2)
ℓ
S
E
G
−
D
=
ℓ
(
y
,
S
E
G
−
D
)
(3)
\ell_{SEG-D} = \ell(y, SEG-D) \tag{3}
ℓSEG−D=ℓ(y,SEG−D)(3)
y 为输入到 CL-D 和 SEG-D 的生成样本。
生成器的损失函数定义为:
ℓ
M
R
F
−
G
=
ℓ
(
M
R
F
−
G
,
C
L
−
D
)
+
ℓ
(
M
R
F
−
G
,
S
E
G
−
D
)
+
λ
⋅
L
1
(4)
\ell_{MRF-G} = \ell(MRF-G, CL-D) + \ell(MRF-G, SEG-D) + \lambda \cdot L1 \tag{4}
ℓMRF−G=ℓ(MRF−G,CL−D)+ℓ(MRF−G,SEG−D)+λ⋅L1(4)
L1 用于衡量真实图像与生成样本之间的差异,λλ 的系数值设为100,可以有效减少伪影。
L1 损失:
L
1
=
E
x
,
x
M
C
I
[
∥
x
−
G
(
x
M
C
I
)
∥
1
]
(5)
L1 = \mathbb{E}_{x,x_{MCI}} \left[ \|x - G(x_{MCI})\|_1 \right] \tag{5}
L1=Ex,xMCI[∥x−G(xMCI)∥1](5)
3. Experiments and Resaults
3.1 Experimental data——实验数据
本研究的平面骨显像数据来自中国甘肃省肿瘤医院核医学科,2016年1月至2019年12月。
从410幅骨显像图像中挑选了286幅包含胸腔转移病灶的显像图,裁剪后提取出胸腔区域用于实验。
图像大小为256 × 256。
每幅图像的病灶标签(即 xGT),由三位经验丰富的核医学医生(一名主任医师、一名副高级技师和一名主管技师)使用基于LabelMe系统手动标注转移病灶。
3.2 Experimental setup——实验设置
BMS-Gen评价指标:
- FID指标:用于衡量 xx 和 yy 之间的分布距离,得分越小,模型性能越高。
- MSE指标:计算 xx 和 yy 之间的像素级误差,MSE得分越低,生成质量越好。
- PSNR指标:衡量 xx 和 yy 之间的图像级相似度,PSNR得分越高,两图像越相似。
- SSIM指标:用于衡量两图像的结构相似性,取值介于0和1之间,值越高,表明两图像越相似。
FID(Fréchet Inception Distance):
F
I
D
(
x
,
y
)
=
∥
μ
x
′
−
μ
y
′
∥
2
2
+
Tr
(
Σ
x
+
Σ
y
−
2
(
Σ
x
Σ
y
)
0.5
)
(6)
FID(x, y) = \|\mu'_x - \mu'_y\|^2_2 + \text{Tr}\left(\Sigma_x + \Sigma_y - 2(\Sigma_x \Sigma_y)^{0.5}\right) \tag{6}
FID(x,y)=∥μx′−μy′∥22+Tr(Σx+Σy−2(ΣxΣy)0.5)(6)
μ′ 是特征图的均值,Tr 是矩阵的迹,Σ 是对应特征图的协方差矩阵。
MSE(均方误差):
M
S
E
=
1
r
c
∑
i
=
0
r
−
1
∑
j
=
0
c
−
1
(
x
(
i
,
j
)
−
y
(
i
,
j
)
)
2
(7)
MSE = \frac{1}{rc} \sum_{i=0}^{r-1} \sum_{j=0}^{c-1} (x(i, j) - y(i, j))^2 \tag{7}
MSE=rc1i=0∑r−1j=0∑c−1(x(i,j)−y(i,j))2(7)
r 和 c 是 x(y) 的行和列的数量。
PSNR(峰值信噪比):
P
S
N
R
=
10
⋅
log
10
(
M
a
x
x
2
M
S
E
)
(8)
PSNR = 10 \cdot \log_{10} \left(\frac{Max^2_x}{MSE}\right) \tag{8}
PSNR=10⋅log10(MSEMaxx2)(8)
Max 是 x 中元素的最大值。
SSIM(结构相似性指数):
S
S
I
M
(
x
,
y
)
=
(
2
μ
x
μ
y
+
C
1
)
(
2
σ
x
y
+
C
2
)
(
μ
x
2
+
μ
y
2
+
C
1
)
(
σ
x
2
+
σ
y
2
+
C
2
)
(9)
SSIM(x, y) = \frac{(2\mu_x \mu_y + C_1)(2\sigma_{xy} + C_2)}{(\mu^2_x + \mu^2_y + C_1)(\sigma^2_x + \sigma^2_y + C_2)} \tag{9}
SSIM(x,y)=(μx2+μy2+C1)(σx2+σy2+C2)(2μxμy+C1)(2σxy+C2)(9)
μx 和 μy 是图像的均值,σxy 是协方差,σx 和 σy 是标准差,正数 C1 和 C2 用于避免分母为零。
下游任务评价指标:
准确率:
A
c
c
u
r
a
c
y
=
T
P
+
T
N
T
P
+
F
P
+
T
N
+
F
N
(10)
Accuracy = \frac{TP + TN}{TP + FP + TN + FN} \tag{10}
Accuracy=TP+FP+TN+FNTP+TN(10)
精确率 / 类别像素准确率 (Precision / CPA):
P
r
e
c
i
s
i
o
n
=
C
P
A
=
T
P
T
P
+
F
P
(11)
Precision = CPA = \frac{TP}{TP + FP} \tag{11}
Precision=CPA=TP+FPTP(11)
召回率 (Recall):
R
e
c
a
l
l
=
T
P
T
P
+
F
N
(12)
Recall = \frac{TP}{TP + FN} \tag{12}
Recall=TP+FNTP(12)
F-1 分数 (F-1 score):
F
−
1
s
c
o
r
e
=
2
×
P
r
e
c
i
s
i
o
n
×
R
e
c
a
l
l
P
r
e
c
i
s
i
o
n
+
R
e
c
a
l
l
(13)
F-1 \ score = 2 \times \frac{Precision \times Recall}{Precision + Recall} \tag{13}
F−1 score=2×Precision+RecallPrecision×Recall(13)
Dice 相似系数 (DSC):
D
S
C
=
2
T
P
F
P
+
2
T
P
+
F
N
(14)
DSC = \frac{2TP}{FP + 2TP + FN} \tag{14}
DSC=FP+2TP+FN2TP(14)
TP = 真阳性(True Positive),FP = 假阳性(False Positive),FN = 假阴性(False Negative),TN = 真阴性(True Negative)。
所有训练好的模型都通过5次交叉验证在测试集上测试,以确保结果的可靠性。
参数设置:

3.3 Experimental results——实验结果
3.3.1 Performance results——性能结果
BMS-Gen模型和其他三个基于GAN的经典生成模型的实验结果:
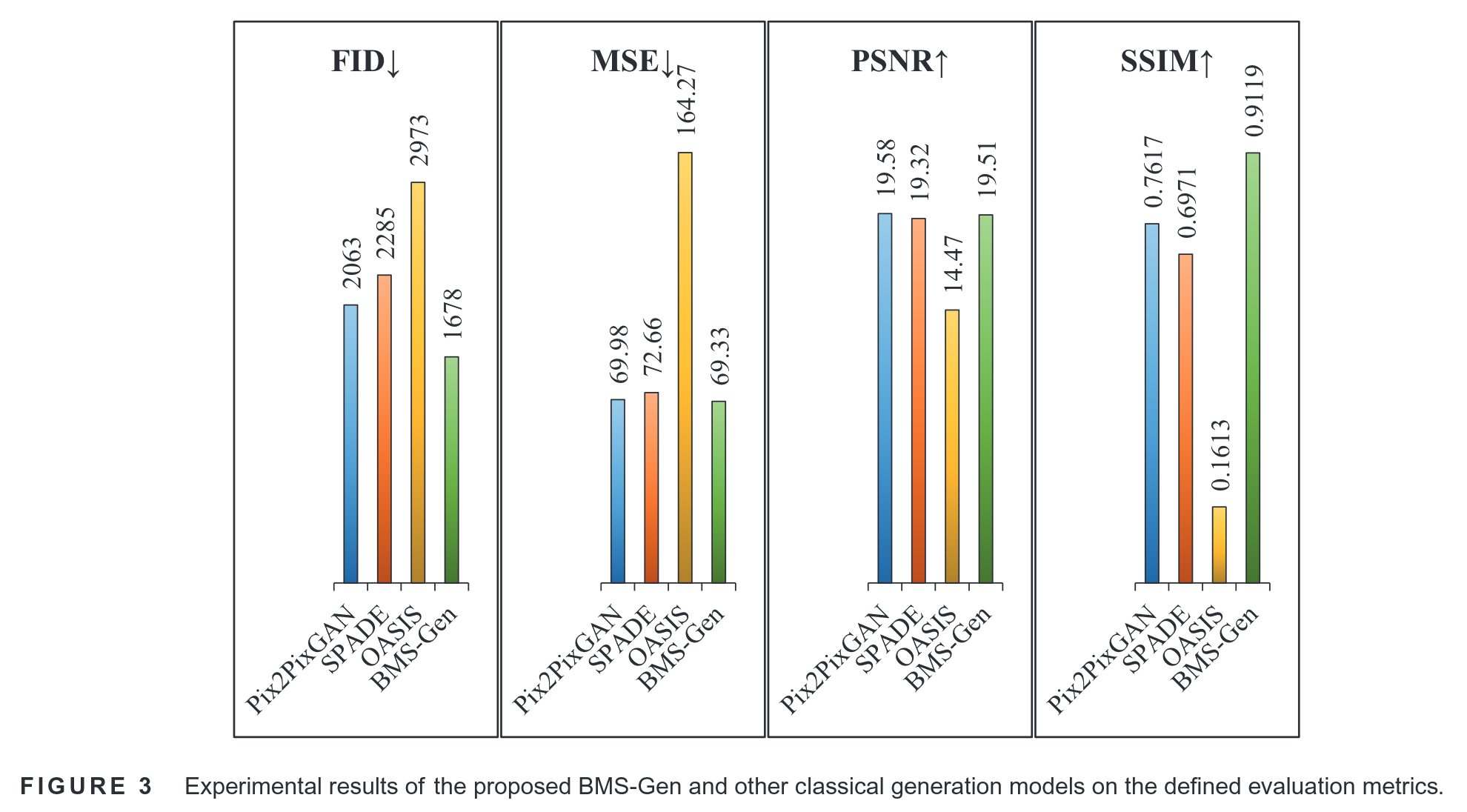
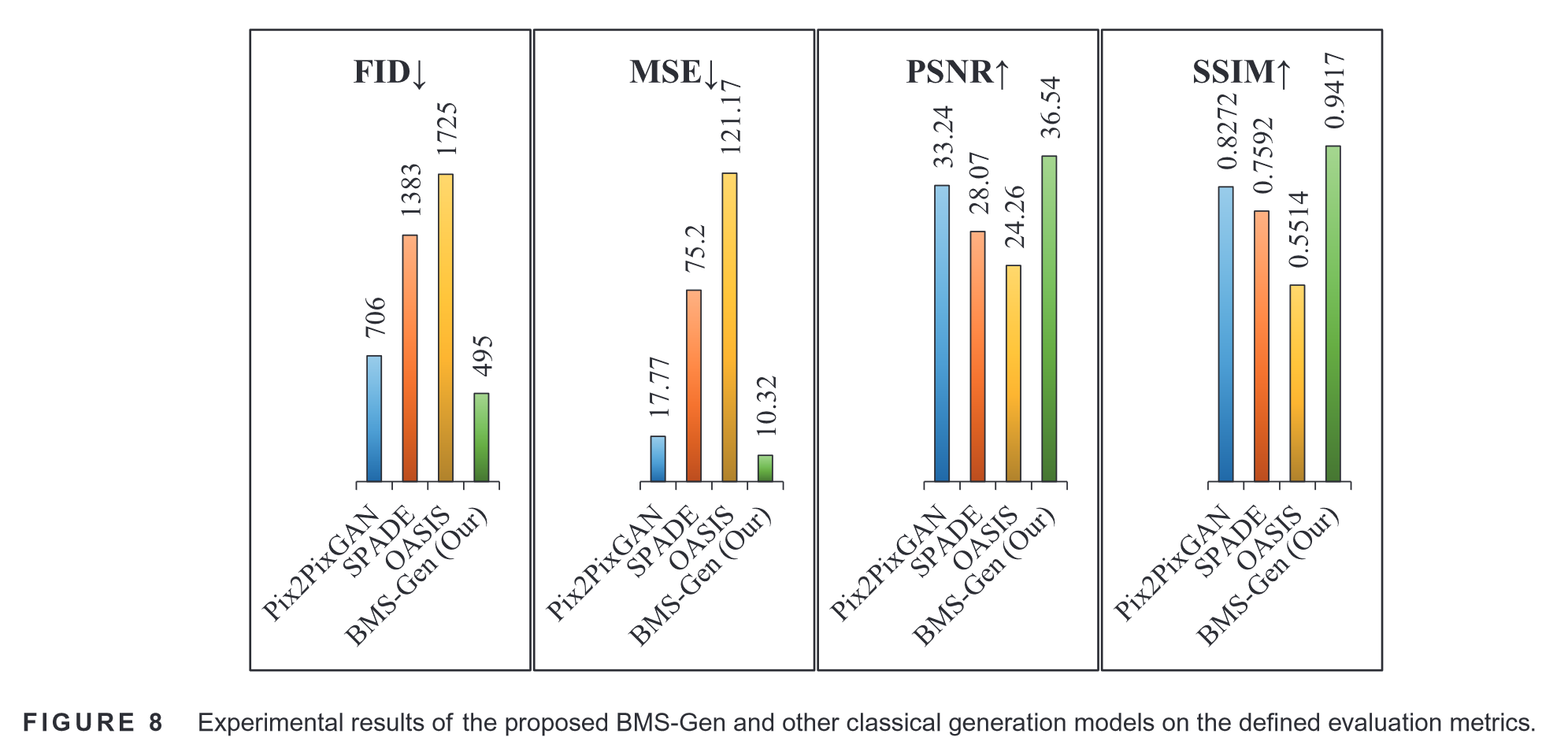
FID评分的显著降低和SSIM的显著增加表明BMS-Gen可以生成与真实图像相似的样本。
BMS-Gen的峰值信噪比比Pix2PixGAN略有下降,归因于SPECT骨显像的性质,其中SPECT BM显像中的元素通常具有比自然图像中0−255的像素值更宽的值范围。
3.3.2 Performance analysis of downstream tasks——下游任务性能分析
Semantic image segmentation(图像语义分割):
不同的数据扩充方法创建不同的数据集:
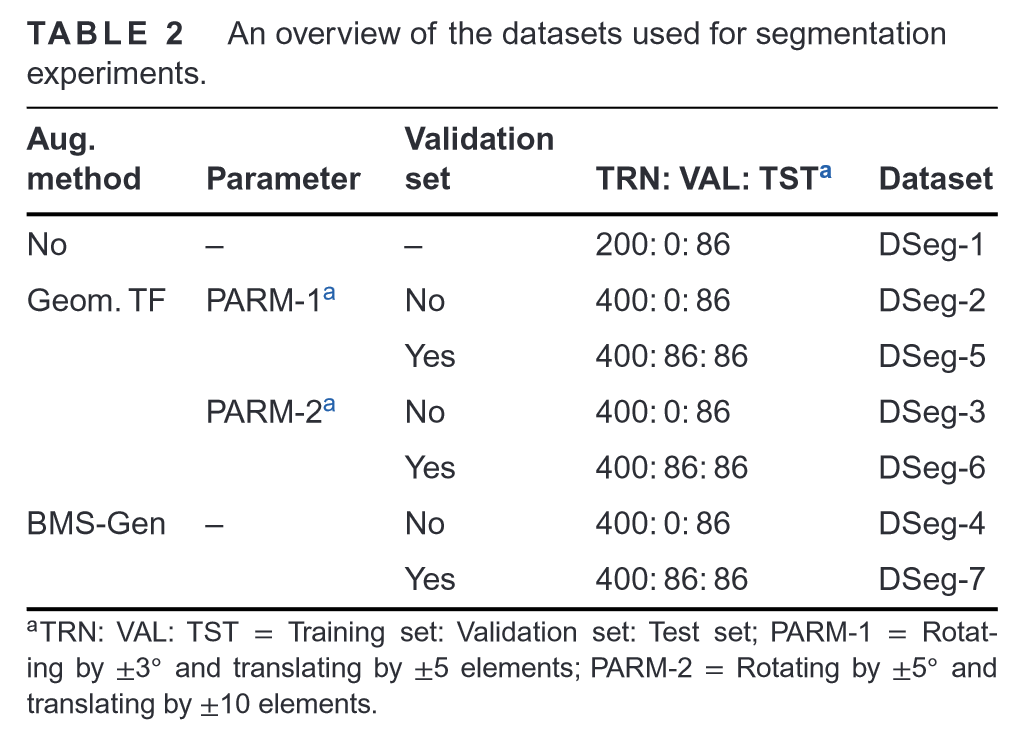
采用一对一的生成策略,分别从原始的286个SPECT骨闪烁图中生成286个样本。
随机抽取86个作为验证集(VAL),其余200个样本,结合原始200个样本,形成训练集(TRN)。
U-Net模型分割BM病变的实验结果:
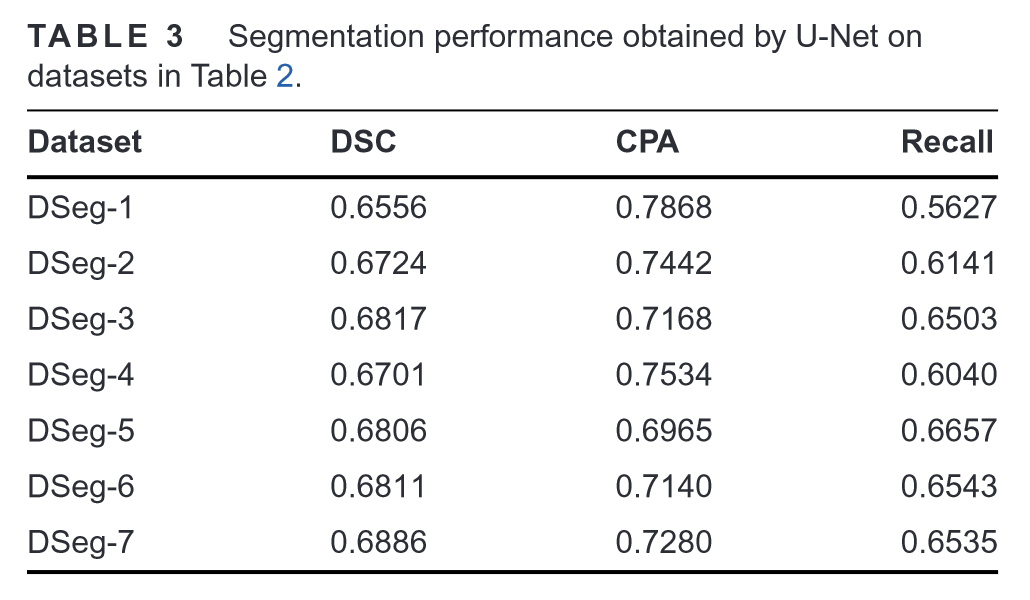
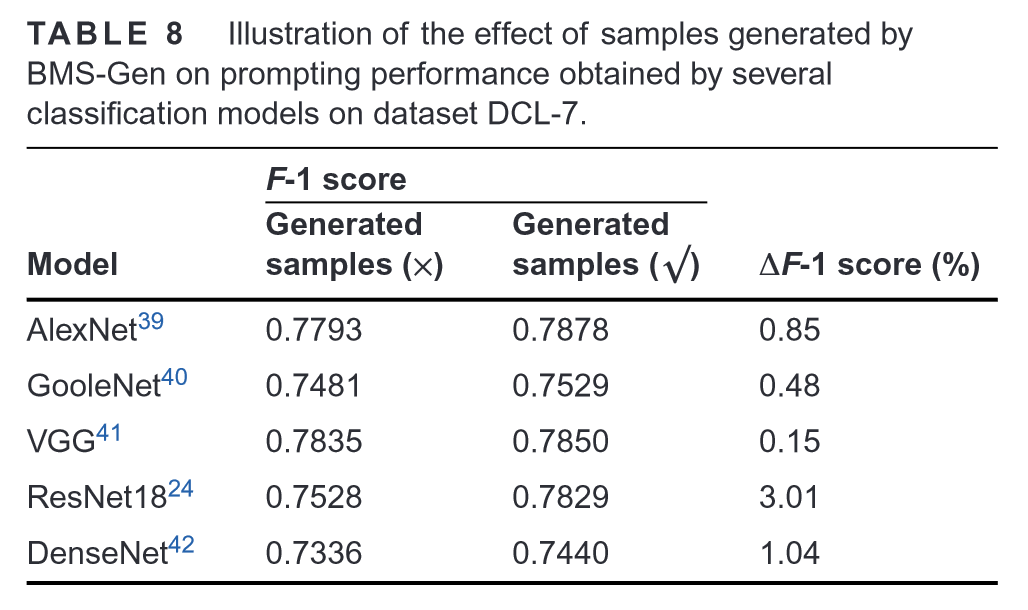
BMS-Gen生成的样本对通过数据集DSeg-7上的几种分割模型获得的提示性能的影响:
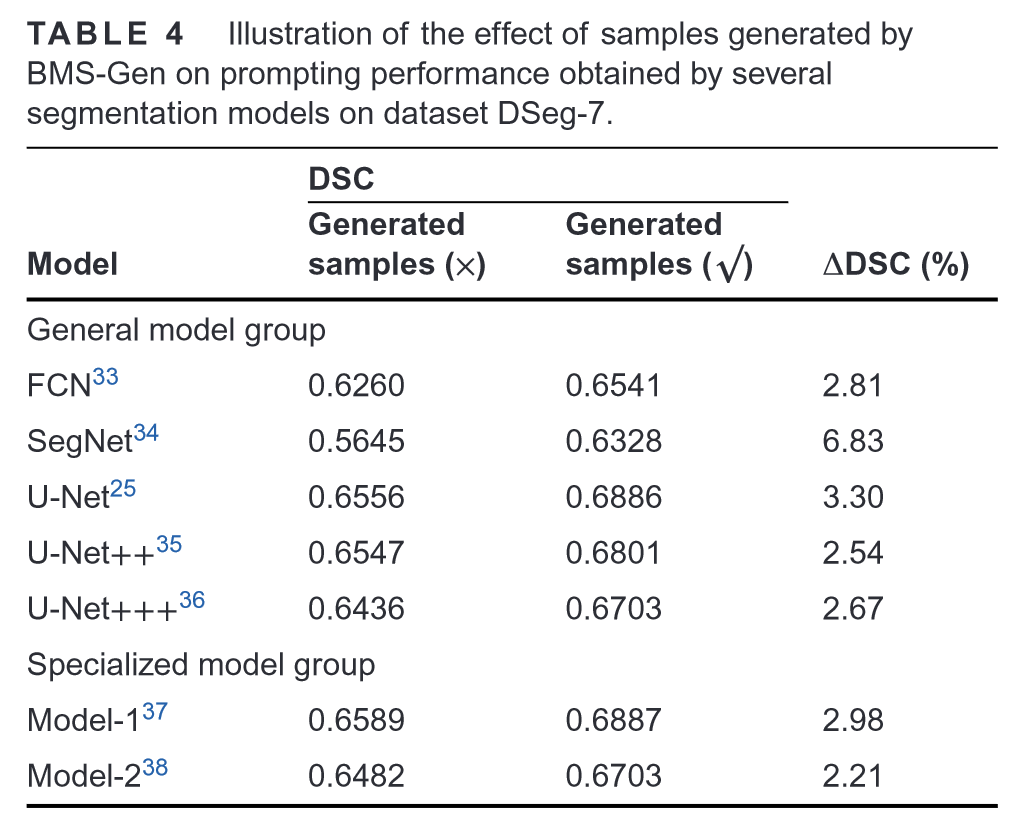
Image classification(图像分类):
不同的数据扩充方法创建不同的数据集:
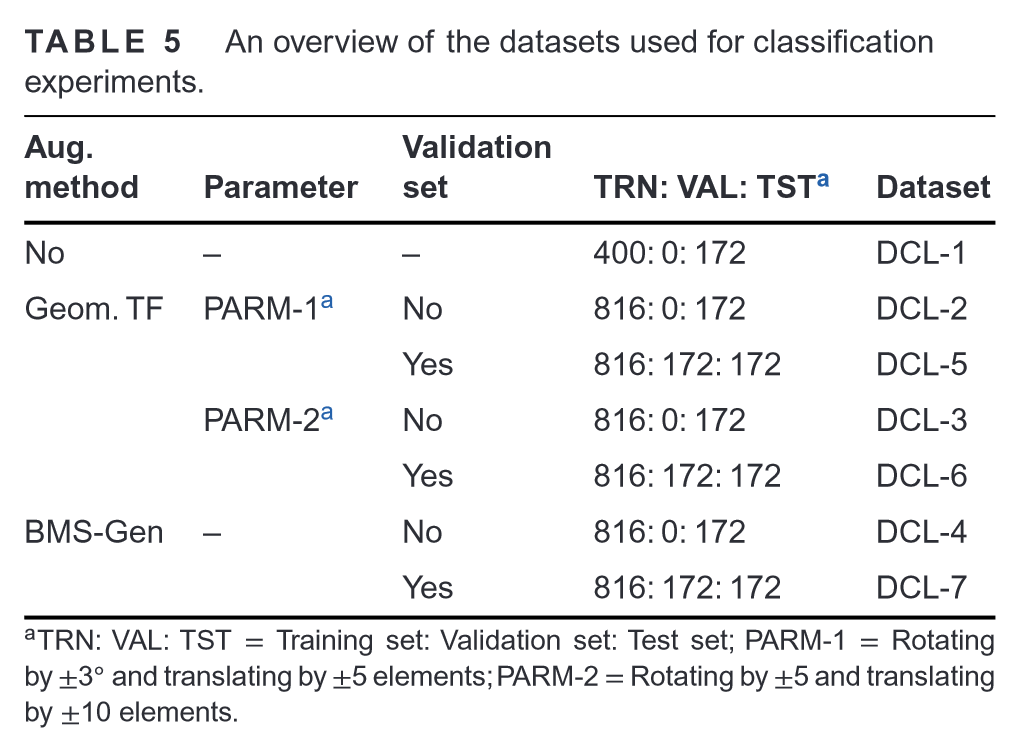
将502张正常SPECT骨扫描图中没有BM(骨转移)的286张图像与之前提到的286张样本结合,创建了实验数据集(n = 572),其余216张样本在使用生成策略时使用。
使用一对一的生成策略,BMS-Gen和几何变换分别从原始的286例SPECT骨显像中生成了286个样本。
在使用验证数据的情况下,几何变换生成了86个不含BM的样本。
- 随机选择372个生成样本中的172个作为验证集(VAL),其余200个样本与原始的616个样本组合为训练集(TRN)。
- 随机选择286个生成样本中的200个样本,与原始的616个样本组合为训练集。
两种情况都随机从原始样本中选择172个作为测试集(TST)。
对上述数据集进行实验。
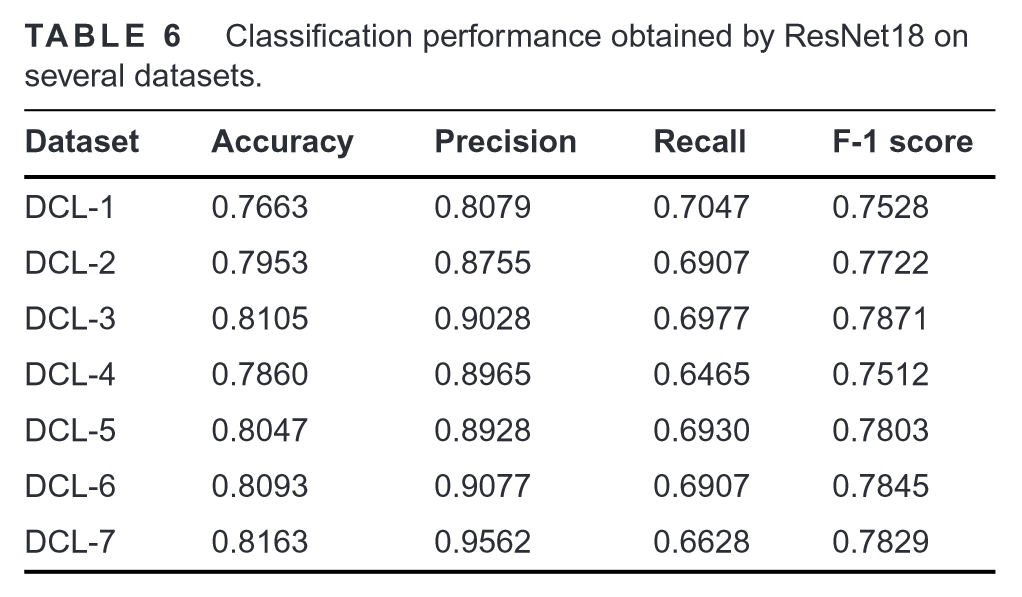
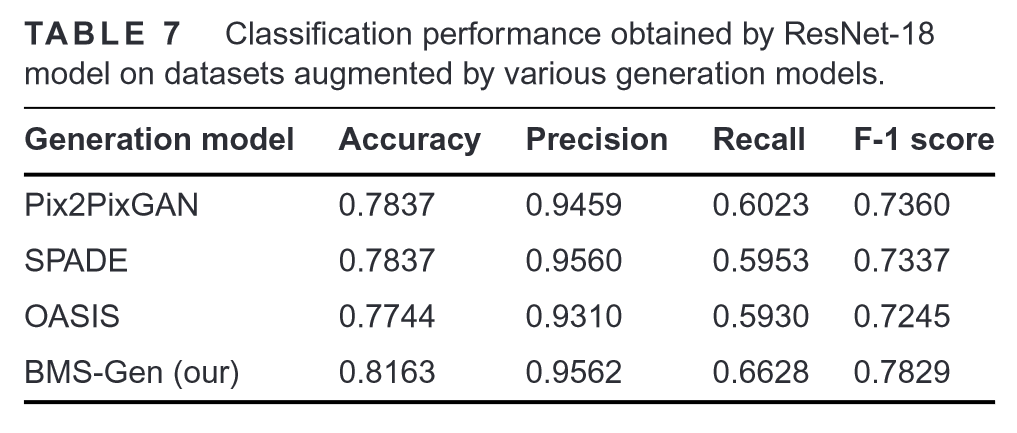
ResNet-18模型在分类骨显像时的实验结果:
ResNet-18模型对不同生成模型扩充的数据集的分类性能:
BMS-Gen生成的样本对数据集DCL-7上几种分类模型获得的提示性能的影响:
4. Discussion and Ablation Study
4.1 Effects of multiply input conditions and model network structure——多输入条件与模型网络结构的影响
BMS-Gen模型消融研究的实验结果:
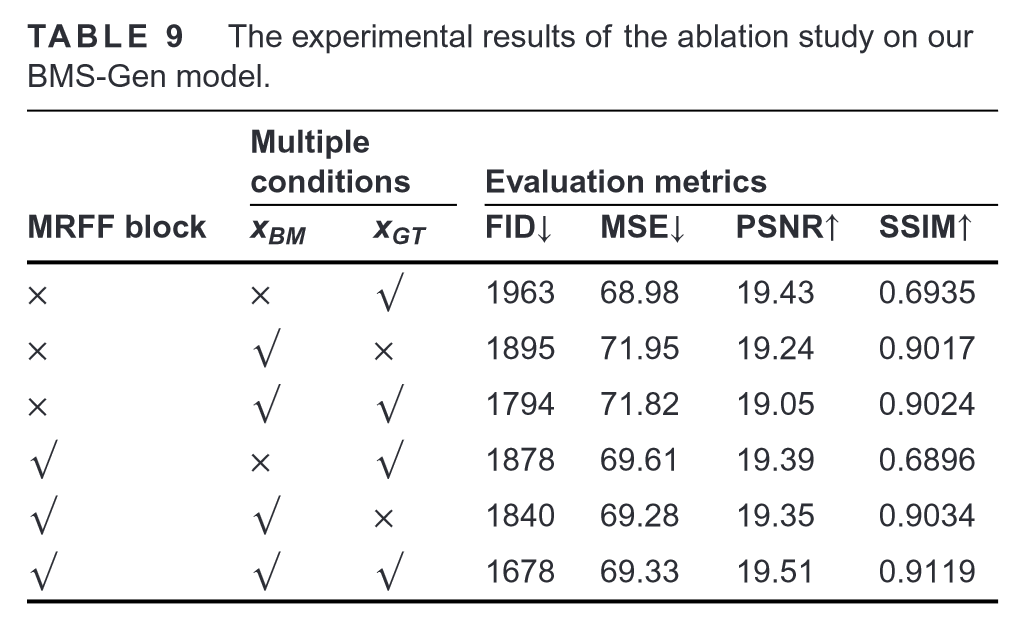
多输入条件和MRFF模块的引入,可以促进BMS-Gen模型聚焦于大小和位置具有高度随机性的病灶,生成逼真但不完全相同的样本。
两个案例进一步验证上述解释:
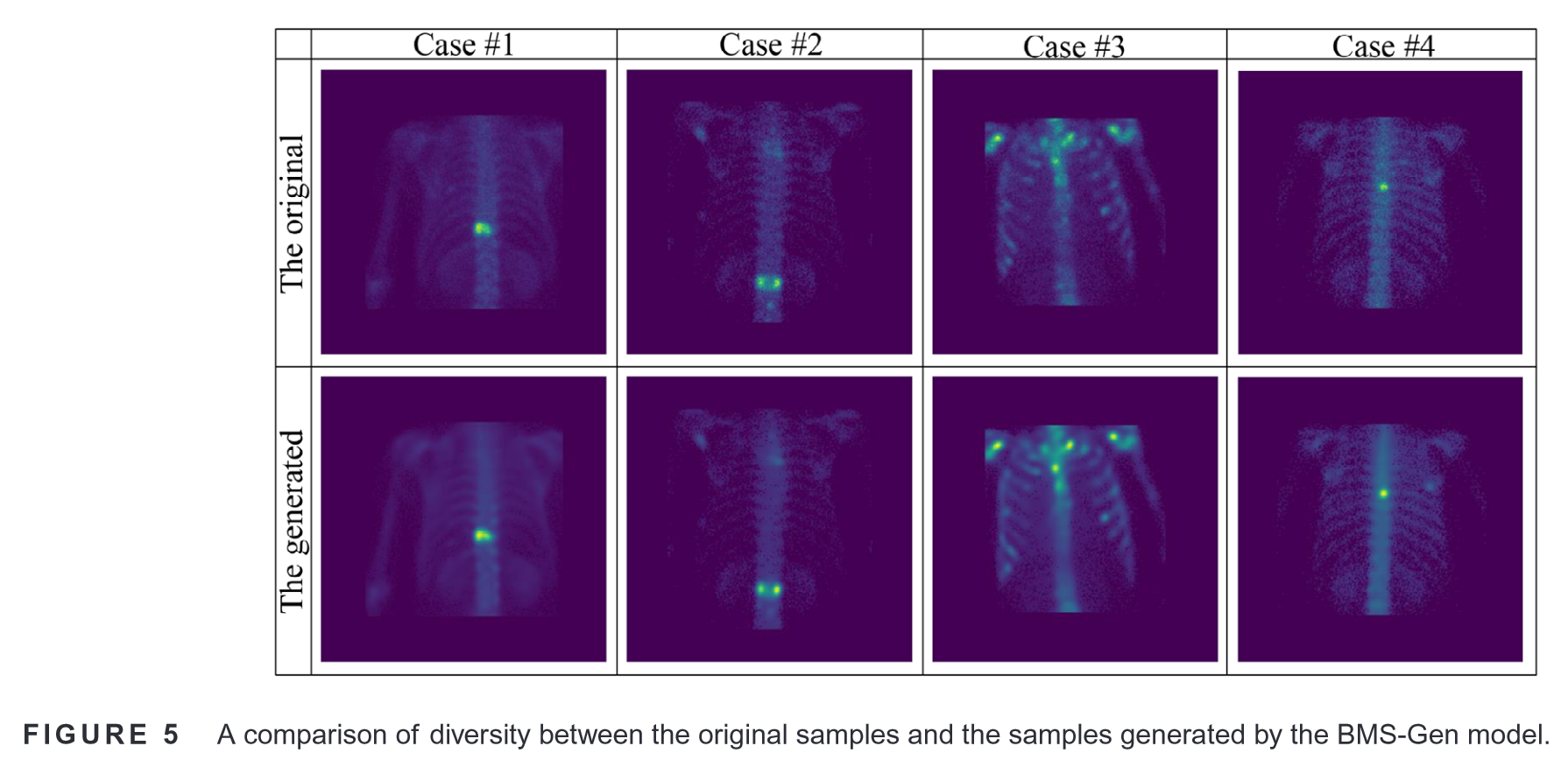
病灶区域在原始样本和生成样本之间的位置和形状保持高度一致。
病灶区域在原始样本和生成样本之间的强度和分布存在明显差异,显示了生成样本的多样性。
两个判别器对BMS-Gen总体性能的影响:
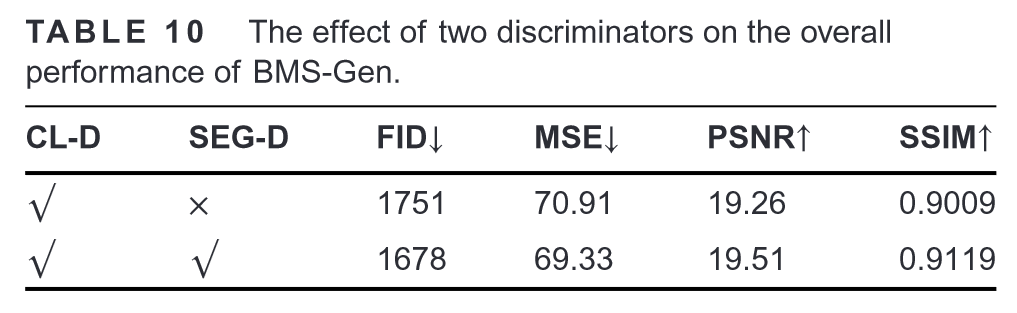
分割判别器被引入,帮助模型聚焦于骨显像中的关注区域(即BM病灶)。
SEG-D提供的额外语义信息可以有效地指导样本生成,并在生成任务中发挥积极作用。
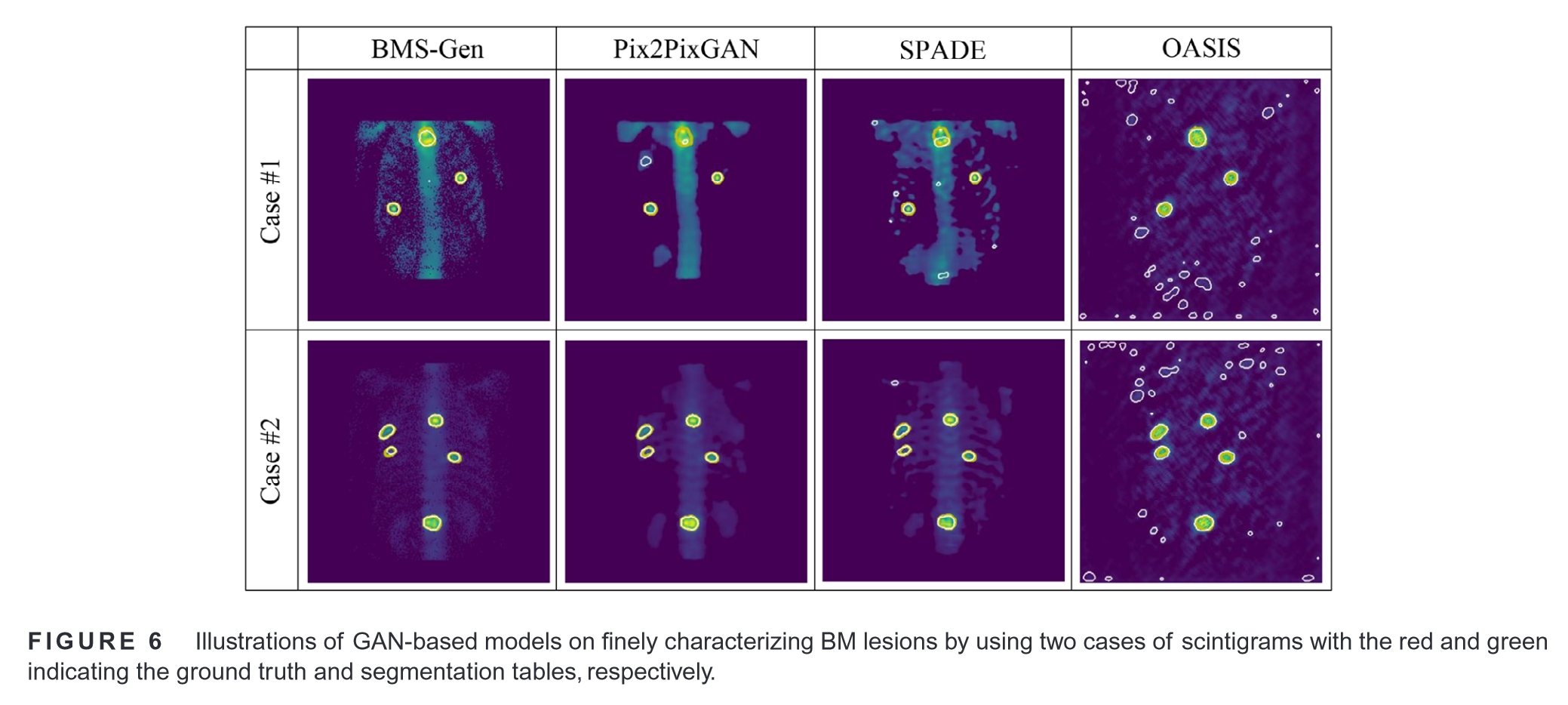
SEG-D引入其他模型刻画病灶区域的能力:
4.2 Effects of two-stage training——两阶段训练的效果
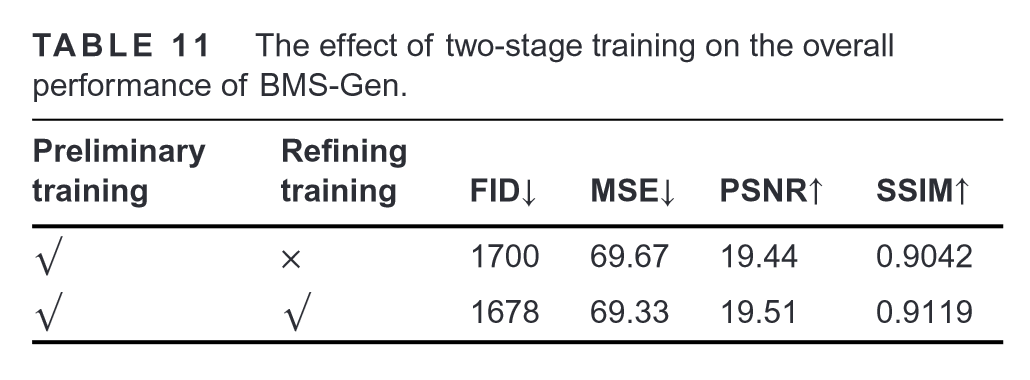
两阶段训练策略对BMS-Gen整体性能的影响:
两个案例展示两阶段训练策略效果:
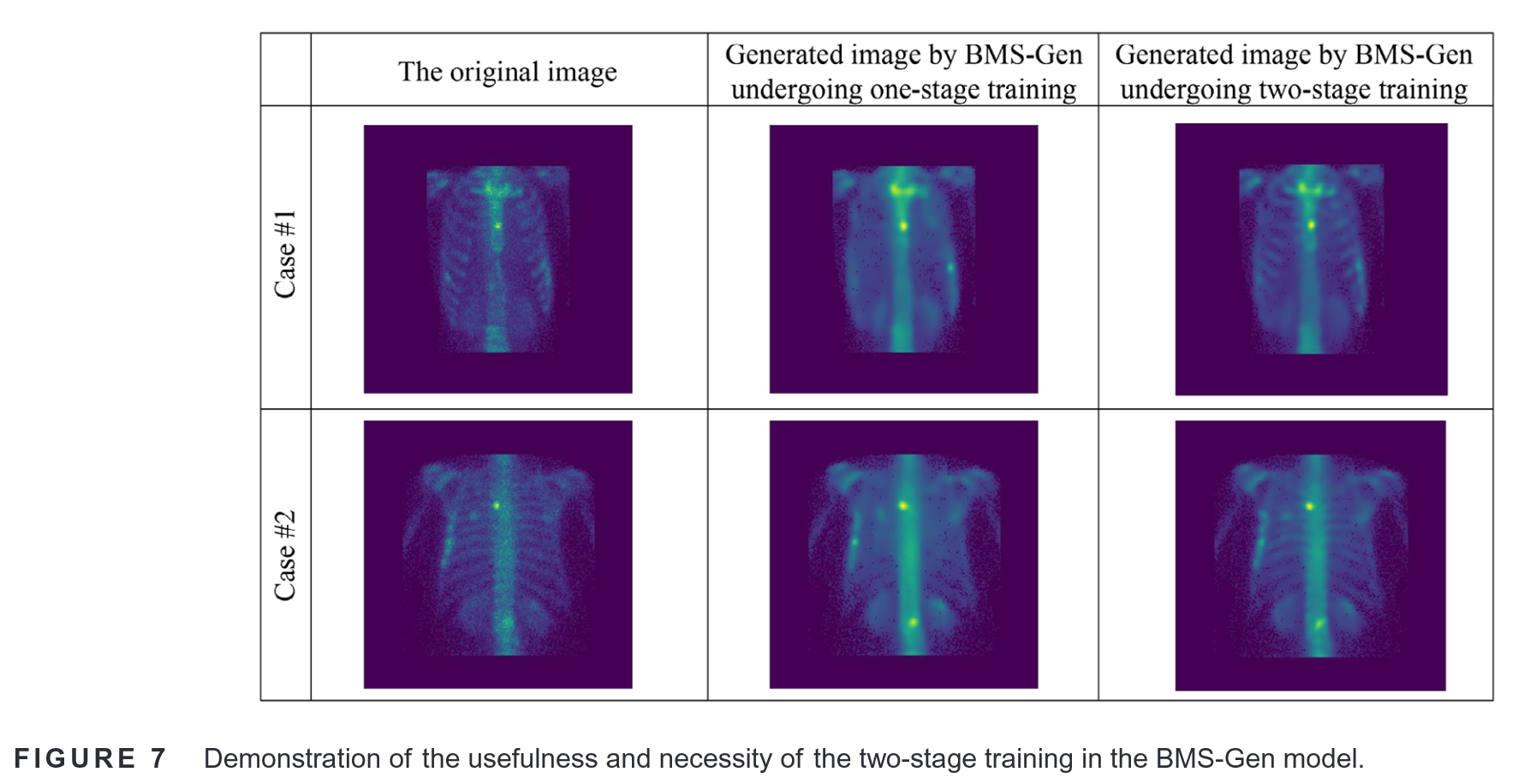
两阶段训练使得模型能够更加关注骨骼细节,从而能够精细地刻画BM病灶。
在全身骨扫描上,BMS-Gen等经典生成模型在定义的评价指标上的实验结果:
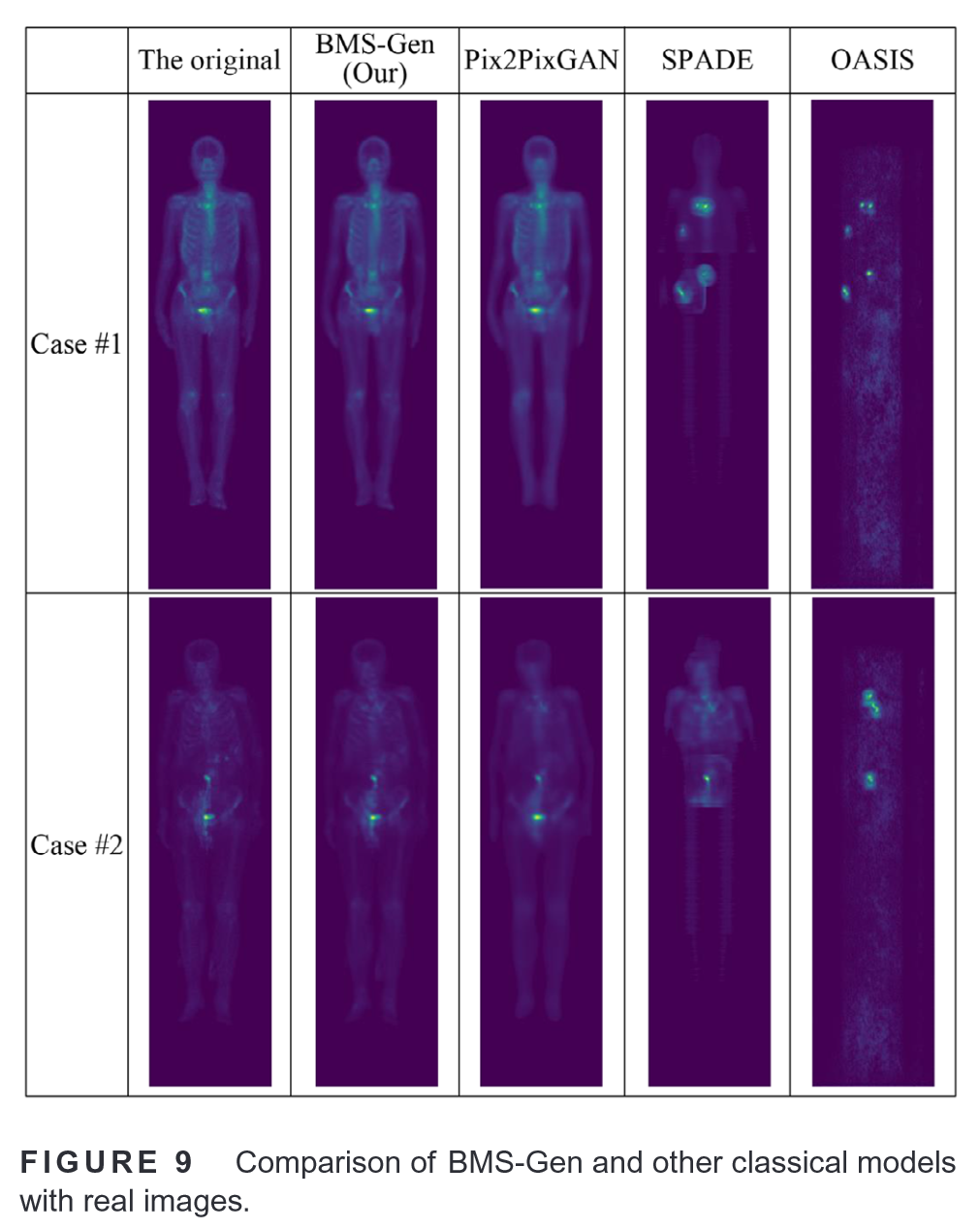
两个案例展示全身骨扫描图像生成效果:
4.3 Limitations of the proposed method on downstream tasks——所提方法对下游任务的局限性
召回率指标下降,通常是由于下游任务模型自身的限制。
Reasons for lower Recall scores on segmentation task(分割任务召回率较低的原因):
在分割任务中,前景(病变区域)通常比背景(正常组织)要小得多。
召回率可能会高估分割性能,因为它没有全面考虑所有方面。
Reasons for lower CPA scores on segmentation task(分割任务CPA分数较低的原因):
CPA下降与分割模型自身的特性有关。
Reasons for lower Recall scores on classification task(分类任务召回率较低的原因):
召回率下降与分类模型自身的特性有关。
5. Conclusion
结果表明,我们的模型优于其他比较模型。
展望:
收集更多SPECT骨显像图,以进一步测试该模型的性能。
尝试将模型应用于其他医学图像模式(如PET)的数据增强任务。















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









