






基本的K均值聚类算法matlab代码,给了一组样本数据作为例子,注释详细,聚类的样本数据可以进行修改。
ID:8815643229030781
浪迹天涯

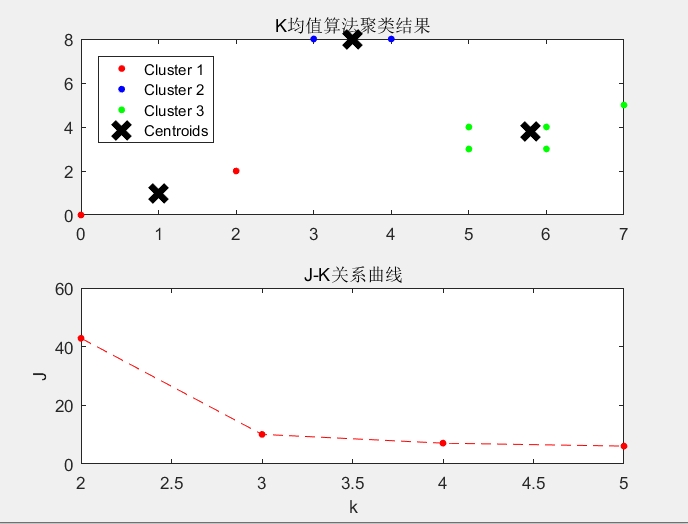
K均值聚类算法是一种常用的无监督学习方法,它可以将一组样本数据划分为若干个簇(cluster)。在这个算法中,每个簇都由一个质心(center)和一组与之关联的样本点组成。K均值聚类算法的目标是使得样本点与其所属簇的质心之间的距离最小化,同时使得不同簇之间的距离最大化。这样,我们可以得到一个将样本点划分为不同簇的聚类结果。
在本文中,我们将介绍如何使用Matlab实现基本的K均值聚类算法。我们将提供一组样本数据作为例子,并详细注释代码以帮助读者理解算法的实现过程。值得注意的是,这里给出的聚类的样本数据仅作为示例,读者完全可以根据自己的需求对其进行修改。
首先,我们需要导入Matlab的机器学习工具箱(Machine Learning Toolbox)。这个工具箱提供了一系列用于聚类分析的函数和工具,方便我们进行K均值聚类算法的实现。接下来,我们将给出基本的K均值聚类算法的代码。
% 导入数据
data = [1 1; 1 2; 2 2; 5 6; 6 5; 6 6];
% 初始化质心
k = 2; % 簇的个数
centroids = data(randperm(size(data, 1), k), :);
% 迭代更新质心
maxIter = 100; % 最大迭代次数
for iter = 1:maxIter
% 计算每个样本点到质心的距离
distances = pdist2(data, centroids);
% 将每个样本点分配到离其最近的质心所在的簇中
[~, labels] = min(distances, [], 2);
% 更新每个簇的质心为其所包含样本点的平均值
for i = 1:k
centroids(i, :) = mean(data(labels == i, :));
end
end
% 输出聚类结果
disp(labels);
在上述代码中,我们首先导入了一组样本数据data,该数据包含了若干个二维样本点。然后,我们初始化了k个质心centroids,这里我们随机选择了k个样本点作为初始质心。接下来,我们进行迭代更新质心的过程,最多进行maxIter次迭代。在每次迭代中,我们首先计算每个样本点到质心的距离,然后将每个样本点分配到离其最近的质心所在的簇中,最后更新每个簇的质心为其所包含样本点的平均值。最后,我们输出了聚类结果。
通过以上代码,我们可以实现基本的K均值聚类算法。读者可以根据自己的需求对样本数据进行修改,以得到不同的聚类结果。同时,我们还可以通过调整k的值来改变聚类的簇数。
总之,K均值聚类算法是一种常用且有效的聚类算法。通过Matlab的机器学习工具箱,我们可以方便地实现该算法并得到聚类结果。在实际应用中,我们可以利用K均值聚类算法对数据进行聚类分析,从而发现数据中的内在规律和结构,为后续的数据挖掘和分析工作提供支持。
希望以上介绍对读者有所帮助,对于想要了解和应用K均值聚类算法的程序员们来说,本文提供了一个基础的代码实现和相关的解释,希望能够启发读者的思考并促进技术的交流与分享。
相关的代码,程序地址如下:http://imgcs.cn/643229030781.html
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









